
A New Front in the Data Wars? How to Evaluate Data Lakehouse Table Formats
What will be the standard table format for analytics: Apache Iceberg or Delta Lake?
- By Mark Lyons
- September 19, 2022
At the height of the big data wars in the early 2010s, Hadoop vendors, cloud providers, and large technology companies battled over the future file format for analytics: Apache Parquet or ORC. Although both are still popular open source columnar file storage formats, ultimately they’ve been optimized for different use cases and tools, with Parquet rising as the industry standard. A decade later, a similar battle has emerged, this time over the table format for analytics.
A file format standardizes how we store data in a file system, but a table format allows us to define data sets as tables. Table formats abstract away the physical representation of the data as files so data consumers and processing engines can focus on the logical representation -- rows and columns -- as they do in relational databases. Along with this abstraction, table formats also provide metadata that allows processing engines to optimize query performance in the data lakehouse at scale.
Table formats are a key enabler for running all analytics workloads on a cost-effective data lakehouse instead of an expensive data warehouse.
Two frontrunners in the table format wars have emerged in the last year: Apache Iceberg and Delta Lake.
The Case for Apache Iceberg
Apache Iceberg was initially created at Netflix and it is now an open source Apache project with many major contributors, including Netflix, Apple, Alibaba, AWS, LinkedIn, Dremio, Adobe, and Stripe. Apache Iceberg’s architecture is based on a three-tier metadata tree that tracks the files that make up the table.
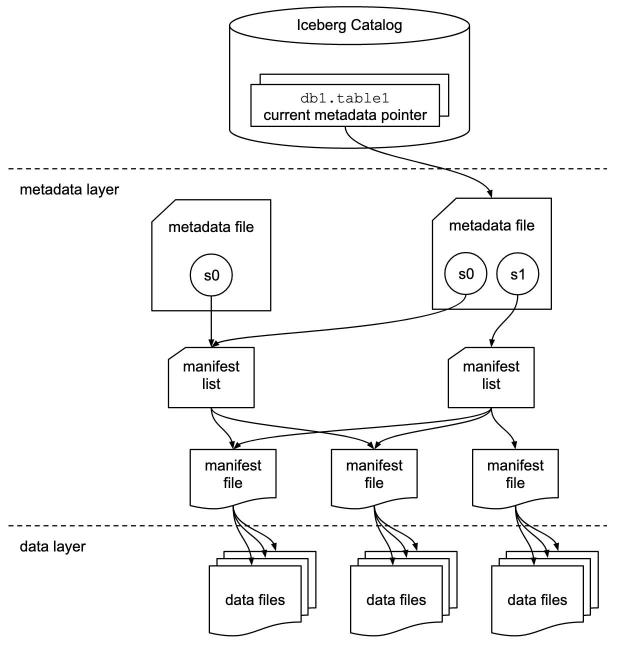
Image Credit: Apache Iceberg
Offering features such as ACID transactions, time travel, hidden partitioning, partition evolution, and schema evolution, Iceberg also has a few pros and cons compared to Delta Lake.
Iceberg’s pros include:
Open source. One hundred percent of Apache Iceberg’s code is publicly available, giving data tools the transparency they need to take full advantage of the table format. Not only is the code publicly available, so is the list of the project management committee members, the mailing list, and the invitation and notes from publicly held community meetings.
Vendor agnostic. No single company controls the project. This agnosticism ensures that development priorities are always focused on what is best for the community, not just one particular vendor. It also ensures the project will continue even if one company decides to stop investing in it. Apache projects must have a diverse contributor base; this results in a more robust technology because it leads to a broad set of contributed use cases and capabilities over time. Code transparency, as well as diversity in project governance, prevents issues such as vendor lock-in (i.e., when only one vendor can optimally use a format due to control over the format) and lock-out (i.e., when new vendors can’t support or choose not to support a format due to lack of access to the code or the inability to influence the project’s direction).
Modern. Unlike other formats that build on the file layout of the legacy Apache Hive project, Apache Iceberg organizes the files of a table to achieve high performance at scale on object storage. When using Delta Lake, the object store will throttle access to files when too many are in the same directory, which often happens with large table partitions.
The cons revolve around:
No easy data sharing. Iceberg currently doesn’t have a solution that enables easy sharing of data between organizations.
No automatic optimization. Currently, Apache Iceberg tables require you to manage table maintenance including compaction, expiring snapshots, etc. Although the Iceberg API and SQL extensions make these easy to perform and schedule yourself, there isn’t an automation service out of the box. However, it’s noteworthy that tools for automatic optimization should hit the market soon through services such as Dremio Arctic and Tabular.
The Case for Delta Lake
The Delta Lake format was created by Databricks and was later open-sourced as a Linux Foundation project. Like the Apache Software Foundation, the Linux Foundation has offered key open technologies to developers and the market for more than 20 years.
Although Delta Lake is an open source project, it still receives most of its development from Databricks developers. Unlike Iceberg, which uses different tiers of metadata, Delta Lake depends on log files (JSON files) that handle listing files, tracking changes, and column metrics in one file. The data from several log files can be summarized periodically by creating checkpoint files (Parquet files).
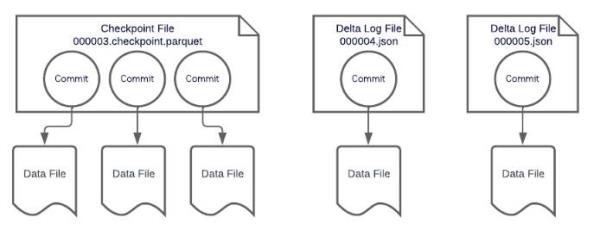
Image Credit: Dremio
Delta Lake also offers ACID transactions, time travel, schema evolution, and hidden partitioning (called generated columns). It does not have some features that Iceberg has, such as partition evolution and a high-performance object store layout.
Delta Lake also has some pros and cons relative to Iceberg tables.
Delta Lake’s pros include:
Delta Sharing. Delta Lake has a sibling open source data sharing protocol called Delta Sharing. This project allows data sharing in Delta Lake tables between internal and external parties without duplicating data.
Automatic optimization. When using Delta Lake on the Databricks platform, you can have your Delta Lake table optimization scheduled automatically. Upcoming services such as Dremio Arctic and Tabular will play this role for Apache Iceberg tables, but they are not yet generally available.
Generated columns. This Delta Lake feature lets you define a column as a function of another, so values are automatically calculated when new records are added. Generated columns also have partitioning benefits similar to Apache Iceberg’s hidden partitioning feature.
The cons revolve around:
Open code, but some aspects are hidden. Although the code is openly available, there is a lack of transparency around who sits on the Technical Steering Committee that controls the project. There is no visibility into the development process, such as when the TSC meets, or a publicly visible developer mailing list. Delta Lake has several user communities built around supporting users, but there’s limited visibility into Delta Lake’s development.
Single-vendor dependency. The vast majority of development and communication around the project is from a single company’s developers. This lack of diversity means the evolution of the project is intrinsically tied to the needs of that company, relegating all other tools to the status of second-class citizens. The ultimate result is that users are locked in to a vendor, albeit circuitously, if they choose Delta Lake.
Assessing the Risks
The value of a data lakehouse lies not only in running analytics on a data lake at scale but also in avoiding the high costs of vendor lock-in and lost opportunities of vendor lock-out that many organizations have experienced with data warehouses. A data lakehouse built on a table format that doesn’t have the highest standard of openness, transparency, and community diversity will ultimately result in the same lock-in and lock-out problems as proprietary data warehouses.
These risks are long-term considerations that are resolved by Apache Iceberg’s feature-rich platform and high standard of openness and transparency, keeping the data lakehouse value proposition a reality.
With companies such as Apple, AWS, Databricks, Dremio, Netflix, and Snowflake involved, the stakes are high. Apache Iceberg is vendor-agnostic, managed by the Apache Software Foundation along with other popular open source data technologies, and used globally by some of today’s most successful technology companies. As it continues to gain traction, Apache Iceberg is in an excellent position to win the table format battle over the next several years, while the greater struggle between data lakehouses and warehouses plays out in the enterprise arena. Ultimately, technologies that reduce the movement of data and treat data as an independent tier likely will prevail.
About the Author
Mark Lyons is the VP of product at Dremio. In his career, Lyons has worked on strategy consulting projects for Fortune 100 companies and has more than 10 years of product management experience in enterprise software. Prior to Dremio, Lyons led product management at Vertica, the first column store data warehouse. You can reach the author via email, Twitter, or LinkedIn.