
Getting Started with Big-Data-as-a-Service
Big-Data-as-a-Service (BDaaS) is an emerging trend with great potential for adoption. We have begun to hear CxOs say that BDaaS makes big data projects viable. We explain why the technology is so appealing.
By Raghu Sowmyanarayanan
Introduction
After software-as-a-service, platform-as-a-service, and data-as-a-service, the next big trend will be big-data-as-a-service (BDaaS). In the last few years, many vendors (e.g. Amazon's AWS with Elastic MapReduce, EMC's Greenplum, Microsoft's Hadoop on Azure, Google's Google cloud big table, etc.) have started focusing on offering cloud-based big data services to help companies and organizations solve their Information management challenges.
Some analysts estimate that the portion of business IT spending that is cloud-based, x-as-a-service activity will increase from about 15 percent today to 35 percent by 2021. Given that it is estimated by IDC that the global big data market will be worth $88 billion by that point, at its current rate, we'd forecast that the value of the BDaaS market could be $30 billion -- which means roughly 4 percent of all IT spending will go into BDaaS in just six years.
In this article, I offer a brief overview of the BDaaS concept and explain how it can be utilized by organizations around the world.
What is BDaaS?
Big data refers to the ever-growing amount of more varied, more complex, and less structured information we are creating, storing, and analyzing. In a business sense, BDaaS refers specifically to applying insights gleaned from this analysis to drive business growth.
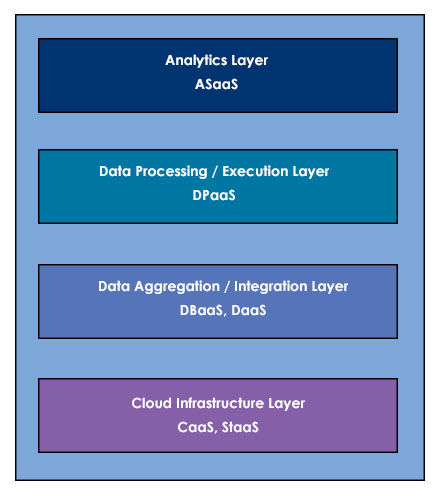
Big-data-as-a-service (BDaaS) is delivered as an analytical tool or as processed information provided by an outside supplier to provide insight into (and plans for creating) a competitive advantage. Such insights are provided by analyzing large amounts of data processed from a variety of sources.
The diagram above depicts various layers that are required to provide big data as a service.
The bottommost layer represents infrastructure-as-a-service components such as compute-as-a-service (CaaS) and storage-as-a-service (StaaS) and their management. On the next layer up, service providers offer database-as-a-service (DBaaS) or data aggregation and exposure as part of data-as-a-service (DaaS). The next layer up in this BDaaS architecture is data platform-as-a-service. As user expectations for real time grow, real-time analytics need to be enabled, and this occurs in the topmost layer; users of analytics-software-as-a-service can generate their own reports, visualizations, and dashboards.
Is the BDaaS Architecture Rigid?
Depending on the scope and size of an application, the data aggregation and data processing layers can be merged. Also it is not mandatory that all the layers need not be based on tools from same vendor. For example, storage-as-a-service (StaaS) and database-as-a-service (DBaaS) are very different and considerations for choosing a vendor or product for each layer would be different as well. It is not necessary to force-fit a solution from same vendor across layers unless we are convinced that it suits the business.
Why BDaaS?
Typically, most commercial big data initiatives will require spending money up front on components and infrastructure. When a large company launches a major initiative, this capital outlay is likely to be substantial. On top of initial setup costs, storing and managing large quantities of information require significant ongoing costs as well.
Big-data-as-a-service enables enterprises to provide users with widespread accessibility to big data interfaces and tools, including MapReduce, Hive, Pig, Presto, and Sqoop. At the same time, its self-managed and auto-scaling infrastructure enables enterprises to achieve this access with a very small operational footprint.
BDaaS enables agility, fluidity, and flexibility. For example, enterprises find it's relatively easier and quicker to adapting changes at lesser cost. Fluidity is the degree to which your BDaaS can be rapidly and cost-effectively repurposed and reconfigured to respond to (and proactively drive) change in a dynamic world. Regulatory factors can affect where you locate your data layer. For example, evolving data provenance laws in some countries require data to be hosted on "native soil." In such cases, the fastest path to compliance might be to extend your data layer to a public cloud data center within the country rather than establishing your own data center there.
Fluidity also enables greater business continuity, and thus confidence. After all, servers fail. Network connections fail. Data centers go offline. To keep serving users and generating value, a fluid data layer includes replicas of data in different locations that can handle data requests in the event of failures in other parts of the data layer.
When organizations outsource all of the big data-related technology and adopt a BDaaS approach, they are then free to focus on business challenges such as mergers and acquisitions, risk and regulatory compliance, customer churn, and adapting to a rapidly changing market
Some example scenarios:
- As a small retailer, we could analyze the relationship between social-media conversations and buying trends to quickly capitalize on emerging sales opportunities.
- When launching a new online service, we could analyze our site's visitors and track how they move from page to page so we can understand what engages them, what turns them off, and where we have promotional and cross-selling opportunities.
Top 3 Myths about Big Data as a Service
Myth #1: It is an Infrastructure Play
It's not just an infrastructure play; it's also a way of buying and selling the data itself in big data sets, or in the case of governments, giving it away. Take www.data.gov for example. It's a regular treasure trove of data. You don't need to pull all that data in-house because the government is kind enough to host it for you, and allow you to put your data analysis tools to bear on it to find the data nuggets that are most valuable to you and your business requirements — and whatever question you are trying to answer.
Myth #2: Architecture is Very Complex
Cloud computing has fundamentally changed the landscape of large-scale computing. Users are now able to quickly instantiate simple virtual machines with little effort and can exploit scalable platforms to serve their applications.
Following aspects of the services make the architecture relatively less complex but still deliver big data as a service in a seamless way. With this architecture, these services do not "install" applications but instantiate which is analogous to forking a process. These services also enable transferring data from one service to another set of services. This architecture also enables packaging various components (storage, caching, analysis etc.) together into a single service. By packaging various storage and analysis components together, users can create analytic services. Using this architecture, users will be able to interact with complex analytic services without considering the underlying software and hardware.
Myth #3: It is Hard to Implement
Vendors such as Microsoft, Google, Amazon, EMC have provided complete solutions to support Big data as a service and pay-as-you-use models. With such products and solutions, it has become viable and relatively less challenging to implement. This service eliminates the implementation and operational headaches caused by big data. Proprietary systems management of these products wraps proven configuration of standard open source technologies to provide a robust, scalable, secure and reliable service, giving customers a simple, developer-friendly environment. This can be deployed in public cloud, virtual private cloud, enterprise private cloud and dedicated clusters depending on business use case and data sensitivities.
Final Thoughts
The term big-data-as-a-service may not be elegant or attractive, but the concept is solid. As more organizations realize the benefits of implementing big data strategies, more vendors will emerge to provide such supporting services to them. With the growth in popularity of software-as-a-service, organizations are getting used to working in a virtualized environment via a Web interface and integrating analytics into this process is a natural next step.
We have started hearing from CxOs that this is making big data projects viable for many businesses that previously would not have considered it because they expected a low ROI or because their team didn't have the skills, time, or resources to tackle the technology. This service allows customers to focus on creating the applications that will drive value for their business instead of spending their time learning to design, test, deploy and manage a secure, scalable and available big data "infrastructure stack." Big-data-as-a-service is something we will see and hear a lot more about in the near future.
Raghuveeran Sowmyanarayanan is a vice president at Accenture and is responsible for designing solution architecture for RFPs and opportunities. You can reach him at [email protected].