LESSON - Addressing Performance Bottlenecks in the Face of Exponential Data Growth
By Susan Garretson Friedman, Senior Technical Analyst, Syncsort Incorporated
We all know that enterprises today are facing unprecedented levels of data growth. Compliance initiatives such as Sarbanes-Oxley and HIPAA are only accelerating and exacerbating this growth, and making it even more crucial to accommodate it effectively. A 2003 study by the Enterprise Storage Group, recently recounted in Forbes magazine, projected that the worldwide capacity of compliant records will have a compounded annual growth rate of 64 percent from 2003 to 2006. This seems to be an on-base, if not lowball, estimate.
From Web sites alone, a company can generate several gigabytes of data each day. Then there is other transactional data such as store inventory, monthly sales, and customer addresses. Try to load all this into a data warehouse in a timely manner, and you’ve got all the ingredients of a bottleneck. Further, as these volumes continue to grow, it will become increasingly difficult to transform unrefined data into reliable information efficiently, hindering strategic planning and decision making.
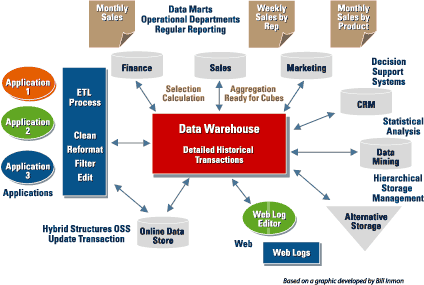
Illustration 1. A typical organization’s data processing flow is filled with potential bottlenecks.
Many organizations also need to process data about customers and markets quickly and frequently in order to anticipate and respond to new and changing business conditions. Generating information and analysis helps a company to stay competitive and empowers it to more effectively monitor and manage business performance.
Side by side with this growth in data volumes and demand for more information and analysis, there has also been an increase in the number of applications being developed and supported in most organizations. This has placed significant demands on IT professionals, since there hasn’t always been a corresponding increase in staff.
Organizations are also increasingly focused on controlling costs. They want to solve the challenges caused by growing data volumes and demand for real-time information with the minimum possible expenditure of money and resources.
We have found that many organizations share some similar areas where data volumes cause bottlenecks, and also have discovered that the right software tools that optimize the process in question work to break through and improve performance. Moreover, we have seen that it is software that is necessary to do this, as it cannot be accomplished with hardware.
One of the most frequent bottlenecks is the most basic: the volume of data movement and its attendant impact on I/O resource and network resource usage. Optimized file and database access methods are needed to combat this problem area. Another holdup point is the huge amounts of processing and data movement required by data marts to precalculate aggregate data to produce summaries, since doing it at query time takes too long. In order to handle this effectively and speed it up, a tool that optimizes aggregation algorithms is needed.
In addition, much raw data these days comes from Web servers. This data is typically very verbose; for example, URLs and CGI parameter strings contain large amounts of text, but only a few characters are relevant to a specific application. The data parsers needed to handle this kind of data can take huge amounts of CPU for processing. One way to handle this most effectively is with a tool that optimizes pattern matching.
Further, not all database vendors provide highly optimized access methods for extracting data from their databases. Their concern is more with loading data into the database, but a typical organization’s data flow usually isn’t that simplistic—there are numerous disparate databases and data marts, which the data needs to move between. For the best performance, all data processes, extracting, transferring, and loading need to be speeded and optimized. Also, database loads involve index creation; index creation requires sorting; and using the fastest possible sorting algorithms improves sort performance generally.
We have found that many organizations sharesome similar areas where data volumes causebottlenecks, and also have discovered that theright software tools that optimize the processin question work to break through and improveperformance. Moreover, we have seen that itis software that is necessary to do this, as itcannot be accomplished with hardware.
We continually run into situations where a system was not originally designed for performance, and performance has to be sutured in afterwards. This is frequently because the system was implemented at an early stage of the business when there wasn’t much volume. Often the designers thought that volume growth could be taken care of by simply upgrading the system, or adding additional systems, or that hardware capacity would just continue to increase in the future the way it has for the last 20 years.
There are several reasons why hardware growth generally won’t yield the performance gains that are needed:
- Run times are almost never linear with data volume growth; when the amount of data is doubled, it more than doubles the processing time.
- Doubling the number of CPUs doesn’t double the throughput, so more hardware is needed to yield less benefit.
- Adding processors only improves performance if the application was well parallelized to start with.
- Increases in hardware capacity (faster CPUs, bigger disks, faster networks, grids) allow new applications to be automated, and these new applications typically generate higher volumes of data than the old ones. And then, we want to turn that data into information.
Looking over these bottleneck challenges, you can see a shared need to minimize the elapsed time of each process—whether the process involves a sort, a load, or an extract, and so on. It doesn’t matter what the other aspects of a solution might be, if the deliverables can’t be delivered on time. To improve application performance, the software must manage to speed all aspects of data transformation—every time data is touched in the process. It should be designed to solve performance problems at whatever stage is appropriate, either as a plug-in to an existing ETL system, a redevelopment of a performance-critical subsystem, or for development of the entire system from scratch. The software should also be easy to use, and scalable to grow with the enterprise. Using such a solution to improve performance will yield high ROI by reducing CPU, memory, and disk resource usage; allowing applications to be deployed on significantly smaller hardware systems; and helping to meet the increased demands on reduced staff.
This article originally appeared in the issue of .