With all of the research I’ve been doing around cloud computing over the past few years, I’ve noticed something very disturbing about how people use the word premises. I’ve blogged about this before but it merits repeating on my TDWI blog. Maybe it’s because I come from a telecommunications background that this bothers me so much – but has anyone else noticed that people are misusing the words premise/premises when describing aspects of the cloud? The proper term is generally premises, people, as in – on your premises (see below).
From Dictionary.com
Premise: a proposition supporting or helping to support a conclusion, a statement considered to be true.
Premises: a tract of land including its buildings.
Therefore, when discussing where servers, services, etc. are located, for instance, you should use the term premises.
Even vendors in the space make this mistake and I cringe every time I hear it. I used to correct them, but I’ve given up doing that. I could list hundreds, if not thousands, of examples of this error. Has the definition of the word changed and I’m missing something? Or, has the word been used incorrectly so many times that it doesn’t matter anymore? My POV: It still matters.
Posted by Fern Halper, Ph.D.0 comments
Blog by Philip Russom
Research Director for Data Management, TDWI
To help you better understand how Hadoop can be integrated into business intelligence (BE) and data warehousing (DW) and why you should care, I’d like to share with you the series of 27 tweets I recently issued on the topic. I think you’ll find the tweets interesting, because they provide an overview of these issues and best practices in a form that’s compact, yet amazingly comprehensive.
Every tweet I wrote was a short sound bite or stat bite drawn from my recent TDWI report “Integrating Hadoop in Business Intelligence and Data Warehousing.” Many of the tweets focus on a statistic cited in the report, while other tweets are definitions stated in the report.
I left in the arcane acronyms, abbreviations, and incomplete sentences typical of tweets, because I think that all of you already know them or can figure them out. Even so, I deleted a few tiny URLs, hashtags, and repetitive phrases. I issued the tweets in groups, on related topics; so I’ve added some headings to this blog to show that organization. Otherwise, these are raw tweets.
Status of Users’ Efforts at Integrating Hadoop into BI/DW
1. #TDWI SURVEY SEZ: Shocking 26% don’t know what #Hadoop is. Ignorance of #Hadoop too common in BI & IT.
2. #TDWI SURVEY SEZ: Mere 18% have had experience w/#HDFS & #Hadoop. Only 2/3rds of 18% have deployed HDFS.
3. Use of #Hadoop Distributed File System (#HDFS) will go from scarce to ensconced in 3 yrs.
4. #TDWI SURVEY SEZ: Only 10% have deployed #HDFS today, yet another 63% expect to within 3 yrs.
5. #TDWI SURVEY SEZ: A mere 27% say their organization will never deploy #HDFS.
Hadoop Technologies Used Today in BI/DW
6. #TDWI SURVEY SEZ: #MapReduce (69%) & #HDFS (67%) are the most used #Hadoop techs today.
7. #TDWI SURVEY SEZ: #Hive (60%) & #HBase (54%) are the #Hadoop techs most commonly used w/#HDFS.
8. #TDWI SURVEY SEZ: #Hadoop technologies used least today are: Chukwa, Ambari, Oozie, Hue, Flume.
9. #TDWI SURVEY SEZ: #Hadoop techs etc poised for adoption: Mahout, R, Zookeeper, HCatalog, Oozie.
What Hadoop will and won’t do for BI/DW
10. #TDWI SURVEY: 88% say #Hadoop for BI/DW (#Hadoop4BIDW) is opportunity cuz enables new app types.
11. #TDWI SURVEY: Can #Hadoop Distributed File System (#HDFS) replace #EDW? Mere 4% said yes.
12. #TDWI SURVEY: Can #Hadoop Distributed File System (#HDFS) augment #EDW? Mere 3% said no.
13. #TDWI SURVEY: Can #Hadoop Distributed File System (#HDFS) expand your #Analytics? Mere 1% said no.
Hadoop Use Case with BI/DW
14. #TDWI SURVEY: 78% of respondents say #HDFS complements #EDW. That’s leading use case in survey.
15. #TDWI SURVEY: Other #HDFS use cases: archive (52%), data stage (41%), sandbox (41%), content mgt (35%).
Hadoop Benefits and Barriers
16. #TDWI SURVEY: Best #Hadoop4BIDW benefits: #BigData source, #analytics, data explore, info discover.
17. #TDWI SURVEY: Worst #Hadoop4BIDW barriers: lacking skill, biz case, sponsor, cost, lousy #Hadoop tools.
Best Practices among Users who’ve deployed Hadoop
18. #TDWI SURVEY: Why adopt #Hadoop4BIDW? Scale, augment DW, new #analytics, low cost, diverse data types.
19. #TDWI SURVEY: Job titles of #Hadoop4BIDW workers: data developer, architect, scientist, analyst.
20. Organizations surveyed with #Hadoop in production average 12 clusters; median is 2.
21. Orgs surveyed with #Hadoop in production average 45 nodes per cluster; median is 12.
22. Orgs surveyed with #Hadoop in production manage a few TBs today but expect ~.5PB within 3yrs.
23. Orgs surveyed with #Hadoop in production mostly load it via batch every 24 hrs.
24. #TDWI SURVEY: Worst #Hadoop functions: security, admin tools, namenode, data quality, loading, dev tools.
BI/DW Tools etc. Integrated Today & Tomorrow with Hadoop
25. #TDWI SURVEY: BI/DW tools commonly integrated with #Hadoop: #analytics, DWs, reporting, webservers, DI.
26. Other BI/DW tools integrated with #Hadoop: analytic DBMSs, #DataViz, OpApps, marts, DQ, MDM.
27. #TDWI SURVEY: Machinery (13%) & sensors (8%) are seldom integrated w/#Hadoop today, but coming.
Want to learn more about big data and its management?
Take courses at the TDWI World Conference in Chicago, May 5-10, 2013. Enroll online.
For a more detailed discussion – in a traditional publication! – get the TDWI Best Practices Report, titled “Integrating Hadoop into Business Intelligence and Data Warehousing,” which is available in a PDF file via a free download.
You can also register online for and replay my TDWI Webinar, where I present the findings of the TDWI report “Integrating Hadoop into BI/DW.”
Philip Russom is the research director for data management at TDWI. You can reach him at [email protected] or follow him as @prussom on Twitter.
Posted by Philip Russom, Ph.D.0 comments
We are just weeks away from the
TDWI World Conference in Chicago (May 5-10), where the theme will be “Big Data Tipping Point.” I have it on good authority that by then, the current coldness will have passed and Chicago will be basking in beautiful spring weather. (If not, as they say, wait five minutes.) The theme of the World Conference is “Big Data Tipping Point,” which means that TDWI will feature many educational sessions to help you get beyond the big data hype and learn how to apply best practices and new technologies for conquering the challenges posed by rising data volumes and increased data variety.
I would like to highlight three sessions to be held at the conference that I see as important to this objective. The first actually does not have “big data” in its description but addresses what always appears in our research as a topmost concern: data integration. In many organizations, the biggest “big data” challenge is not so much about dealing with one large source as integrating many sources and performing analytics across them. Mark Peco will be teaching
“TDWI Data Integration Principles and Practices: Creating Information Unity from Data Disparity” on Monday, May 6.
On Wednesday, May 7, Dave Wells will head up
“TDWI Business Analytics: Exploration, Experimentation, and Discovery.” For most organizations, the central focus of big data thinking is about analytics; business leaders want to anchor decisions in sound data analysis and use data science practices to uncover new insights in trends, patterns, and correlations. Yet, understanding analytics techniques how to align them with business demands remains a barrier. Dave Wells does a great job of explaining analytics, how the practices relate to business intelligence, and how to bring the practices to bear to solve business problems.
The third session I’d like to spotlight is
“Building a Business Case for Big Data in Your Data Warehouse,” taught by Krish Krishnan. A critical starting point for big data projects and determining their relationship to the existing data warehouse is building the business case. Krish is great at helping professionals get the big picture and then see where to begin, so that you don’t get intimated by the scale. He will cover building the business case, the role of data scientists, and how next-generation business intelligence fits into the big data picture.
These are just three of the many sessions to be held during the week, on topics ranging from data mining, Hadoop, and social analytics to advanced data modeling and data virtualization. I hope you can attend the Chicago TDWI World Conference!
Posted by David Stodder0 comments
By Philip Russom, TDWI Research Director
[
NOTE -- My new TDWI report “Integrating Hadoop into Business Intelligence (BI) and Data Warehousing (DW)” (Hadoop4BIDW) is finished and will be published in early April. I will broadcast the report’s Webinar on April 9, 2013 at noon ET. In the meantime, I’ll leak a few of the report’s findings in this blog series. Search Twitter for #Hadoop, #TDWI, and #Hadoop4BIDW to find other leaks. Enjoy!]
Hadoop is still rather young, so it needs a number of upgrades to make it more palatable to BI professionals and mainstream organizations in general. Luckily, a number of substantial improvements are coming.
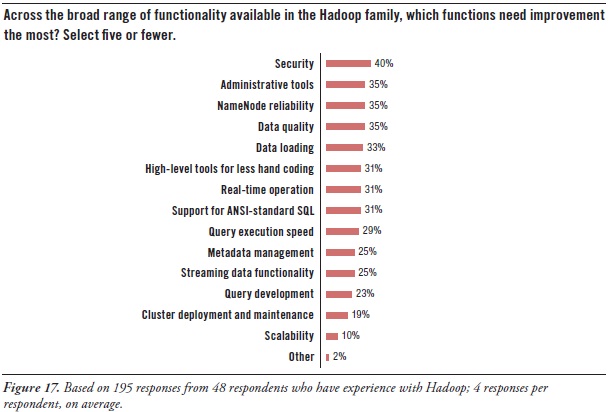
Hadoop users’ greatest needs for advancement concern security, tools, and high availability:
Security. Hadoop today includes a number of security features, such as file-permission checks and access control for job queues. But the preferred function seems to be Service Level Authorization, which is the initial authorization mechanism that ensures clients connecting to a particular Hadoop service have the necessary, pre-configured permissions. Furthermore, add-on products that provide encryption or other security measures are available for Hadoop from a few third-party vendors. Even so, there’s a need for more granular security at the table level in HBase, Hive, and HCatalog.
Administration. As noted earlier, much of Hadoop’s current evolution is at the tool level, not so much in the HDFS platform. After security, users’ most pressing need is for better administrative tools (35% in Figure 17 above), especially for cluster deployment and maintenance (19%). The good news is that a few vendors offer tools for Hadoop administration, and a major upgrade of open-source Ambari is coming soon.
High availability. HDFS has a good reputation for reliability, due to the redundancy and failover mechanisms of the cluster it sits atop. However, HDFS is currently not a high availability (HA) system, because its architecture centers around NameNode. It’s the directory tree of all files in the file system, and it tracks where file data is kept across the cluster. The problem is that NameNode is a single point of failure. While the loss of any other node (intermittently or permanently) does not result in data loss, the loss of NameNode brings the cluster down. The permanent loss of NameNode data would render the cluster's HDFS inoperable, even after restarting NameNode.
A BackupNameNode is planned to provide HA for NameNode, but Apache needs more and better contributions from the open source community before it’s operational. There’s also Hadoop SecondaryNameNode (which provides a partial, latent backup of NameNode) and third-party patches, but these fall short of true HA. In the meantime, Hadoop users protect themselves by putting NameNode on especially robust hardware and by regularly backing up NameNode’s directory tree and other metadata.
Latency issues. A number of respondents are hoping for improvements that overcome the data latency of batch-oriented Hadoop. They want Hadoop to support real-time operation (31%), fast query execution (29%), and streaming data (25%). These will be addressed soon by improvements to Hadoop products like MapReduce, Hive, and HBase, plus the new Impala query engine.
Development tools. Again, many users needs better tools for Hadoop, including development tools for metadata management (25%), query design (23%), and ANSI-standard SQL (31%), plus a higher-level approach that results in less hand coding (31%).
Want to learn more about big data and its management? Take courses at the TDWI World Conference in Chicago, May 5-10, 2013.
Enroll online.
Posted by Philip Russom, Ph.D.0 comments

By Philip Russom, TDWI Research Director
[
NOTE -- My new TDWI report “Integrating Hadoop into Business Intelligence (BI) and Data Warehousing (DW)” (Hadoop4BIDW) is finished and will be published in early April. I will broadcast the report’s Webinar on April 9, 2013 at noon ET. In the meantime, I’ll leak a few of the report’s findings in this blog series. Search Twitter for #Hadoop4BIDW, #Hadoop, and #TDWI to find other leaks. Enjoy!]
Number of HDFS clusters per enterprise. One way to measure the adoption of HDFS is to count the number of HDFS clusters per enterprise. Since far more people have downloaded HDFS and other Hadoop products than have actually put them to enterprise use, it’s best to only count those clusters that are in production use. The vast majority of survey respondents (and, by extension, most user organizations) do not have HDFS clusters in production. So, this report identified 32 respondents who do, and asked them about their clusters. (See Figure 13 above.)
When asked how many HDFS clusters are in production, 32 survey respondents replied in the range one to one hundred. Most responses were single digit integers, which drove the average number of HDFS clusters down to 12 and the median down to 2. Parsing users’ responses reveals that over half of respondents have only one or two clusters in production enterprise-wide at the moment, although one fifth have 50 or more.
Note that ownership of Hadoop products can vary, as discussed earlier, thereby affecting the number of HDFS clusters. Sometimes central IT provides a single, very large HDFS cluster for shared use by departments across an enterprise. And sometimes departments and development teams have their own.
Number of nodes per HDFS cluster. We can also measure HDFS cluster maturity by counting the number of nodes in the average cluster. Again, the most meaningful count comes from clusters that are in production. (See Figure 14 above.)
When asked how many nodes are in the HDFS cluster most often used by the survey respondent, respondents replied in the range one to six hundred and twenty, where one third of responses were single digit. That comes to 45 nodes per production cluster on average, with the median at 12. Half of the HDFS clusters in production surveyed here have 12 or fewer nodes, although one quarter have 50 or more.
To add a few more data points to this discussion, people who work in large Internet firms have presented at TDWI conferences, talking about HDFS clusters with approximately one thousand nodes. However, speakers discussing fairly mature HDFS usage specifically in data warehousing usually have clusters in the fifty to one-hundred node range. Proof-of-concept clusters observed by TDWI typically have four to eight nodes, whereas development clusters may have but one or two.
Want to learn more about big data and its management? Take courses at the TDWI World Conference in Chicago, May 5-10, 2013.
Enroll online.
Posted by Philip Russom, Ph.D.0 comments
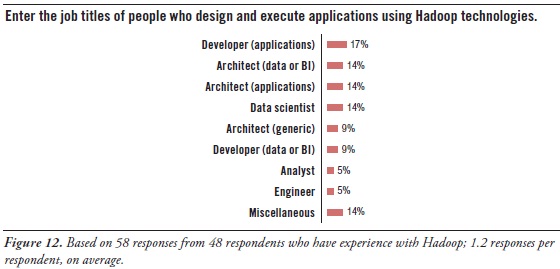
By Philip Russom, TDWI Research Director
[
NOTE -- My new TDWI report “Integrating Hadoop into Business Intelligence (BI) and Data Warehousing (DW)” (Hadoop4BIDW) is finished and will be published in early April. I will broadcast the report’s Webinar on April 9, 2013. In the meantime, I’ll leak a few of the report’s findings in this blog series. Search Twitter for #Hadoop4BIDW, #Hadoop, and #TDWI to find other leaks. Enjoy!]
One way to get a sense of what kinds of technical specialists are working with HDFS and other Hadoop tools is to look at their job titles. So, this report’s survey asked a subset of respondents to enter the job titles of Hadoop workers. (See Figure 12 above.) Many users are concerned about acquiring the right people with the right skills for Hadoop, and this list of job titles can assist in that area.
Hadoop workers are typically architects, developers, data scientists, and analysts:
Architect. It’s interesting that the word architect appeared in more job titles than any other word, followed closely by the word developer. Among these, two titles stand out – data architect and application architect – plus miscellaneous titles like system architect and IT architect. Most architects (regardless of type) guide designs, set standards, and manage developers. So architects are most likely providing a management and/or governance function for Hadoop, since Hadoop has an impact on data, application, and system architectures.
Developer. Similar to the word architect, many job titles contained the word developer. Again, there’s a distinction between application developers and data (or BI) developers. Application developers may be there to satisfy Hadoop’s need for hand-coded solutions, regardless of the type of solution. And, as noted, some application groups have their own Hadoop cluster. The data and BI developers obviously bring their analytic expertise to Hadoop-based solutions.
Data Scientist. This job title has slowly gained popularity in recent years, and seems to be replacing the older position of business analyst. Another way to look at it is that some business analysts are proactively evolving into data scientists, because that’s what their organizations need from them. When done right, the data scientist’s job involves many skills, and most of those are quite challenging. For example, like a business analyst, the data scientist is also a hybrid worker who needs knowledge of both business and data (that is, data’s meaning, as well as its management). But the data scientist must be more technical than the average business analyst, doing far more hands-on work writing code, designing analytic models, creating ETL logic, modeling databases, writing very complex SQL, and so on. Note that these skills are typically required for high-quality big data analytics in a Hadoop environment, and the position of the data scientist originated for precisely that. Even so, TDWI sees the number of data scientists increasing across a wide range of organizations and industries, because they’re needed as analytic usage gets deeper and more sophisticated and as data sources and types diversify.
Analyst. Business analyst and data analyst job titles barely registered in the survey. Perhaps that’s because most business analysts rely heavily on SQL, relational databases, and other technologies for structured data, which are currently not well represented in Hadoop functionally. As noted, some analysts are becoming data scientists, as they evolve to satisfy new business requirements.
Miscellaneous. The remaining job titles are a mixed bag, ranging from engineers to marketers. This reminds us that big data analytics – and therefore Hadoop, too – is undergoing a democratization that makes it accessible to an ever-broadening range of end users who depend on data to do their jobs well.
Want more? Register for my Hadoop4BIDW Webinar, coming up April 9, 2013 at noon ET:
http://bit.ly/Hadoop13
Posted by Philip Russom, Ph.D.0 comments
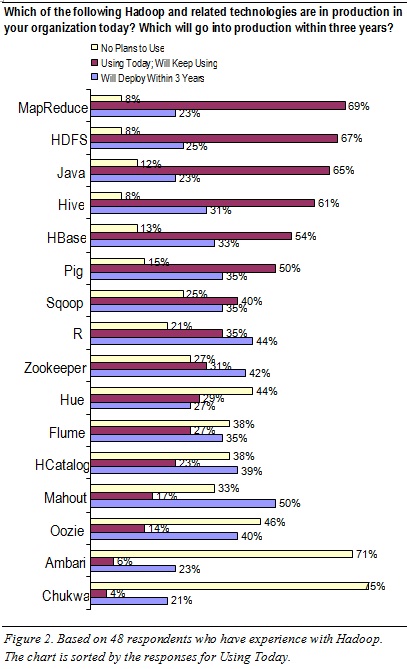
By Philip Russom, TDWI Research Director
[NOTE -- My new TDWI report “Integrating Hadoop into Business Intelligence (BI) and Data Warehousing (DW)” (Hadoop4BIDW) is finished and will be published in early April. I will broadcast the report’s Webinar on April 9, 2013. In the meantime, I’ll leak a few of the report’s findings in this blog series. Search Twitter for #Hadoop4BIDW, #Hadoop, and #TDWI to find other leaks. Enjoy!]
This report considers Hadoop an ecosystem of products and technologies. Note that some are more conducive to applications in BI, DW, DI, and analytics than others; and certain product combinations are more desirable than others for such applications.
To sort out which Hadoop products are in use today (and will be in the near future), this report’s survey asked: Which of the following Hadoop and related technologies are in production in your organization today? Which will go into production within three years? Which will you never use? (See Figure 2 above.) These questions were answered by a subset of 48 survey respondents who claim they’ve deployed or used HDFS. Hence, their responses are quite credible, being based on direct hands-on experience.
HDFS and a few add-ons are the most commonly used Hadoop products today. HDFS is near the top of the list (67% in Figure 2), because most Hadoop-based applications demand HDFS as the base platform. Certain add-on Hadoop tools are regularly layered atop HDFS today:
- MapReduce (69%). For the distributed processing of hand-coded logic, whether for analytics or for fast data loading and ingestion
- Hive (60%). For projecting structure onto Hadoop data, so it can be queried using a SQL-like language called HiveQL
- HBase (54%). For simple, record-store database functions against HDFS’ data
MapReduce is used even more than HDFS. The survey results (which rank MapReduce slightly more common than HDFS) suggest that a few respondents in this survey population are using MapReduce today without HDFS, which is possible, as noted earlier. The high MapReduce usage also explains why Java and R ranked fairly high in the survey; these programming languages are not Hadoop technologies per se, but are regularly used for the hand-coded logic that MapReduce executes. Likewise, Pig ranked high in the survey, being a tool that enables developers to design logic (for MapReduce execution) without having to hand-code it.
Some Hadoop products are rarely used today. For example, few respondents in this survey population have touched Chukwa (4%) or Ambari (6%), and most have no plans for using them (75% and 71%, respectively). Oozie, Hue, and Flume are likewise of little interest at the moment.
Some Hadoop products are poised for aggressive adoption. For example, half of respondents (50%) say they’ll adopt Mahout within three years, with similar adoption projected for R (44%), Zookeeper (42%), HCatalog (40%), and Oozie (40%).
TDWI sees a few Hadoop products as especially up-and-coming. Usage of these will be driven up according to user demand. For example, users need analytics tailored to the Hadoop environment, as provided by Mahout (machine-learning based recommendations, classification, and clustering) and R (a programming language specifically for analytics). Furthermore, BI professionals are accustomed to DBMSs, and so they long for a Hadoop-wide metadata store and far better tools for HDFS administration and monitoring; these user needs are being addressed by HCatalog and Ambari, respectively, and therefore TDWI expects both to become more popular.
Want more? Register for my Hadoop4BIDW Webinar, coming up April 9, 2013 at noon ET: http://bit.ly/Hadoop13
Posted by Philip Russom, Ph.D.0 comments

By Philip Russom, TDWI Research Director
[NOTE -- My new TDWI report “Integrating Hadoop into Business Intelligence (BI) and Data Warehousing (DW)” (Hadoop4BIDW) is finished and will be published in early April. I will broadcast the report’s Webinar on April 9, 2013. In the meantime, I’ll leak a few of the report’s findings in this blog series. Search Twitter for #Hadoop, #TDWI and #Hadoop4BIDW to find other leaks. Enjoy!]
The Hadoop Distributed File System (HDFS) and other Hadoop products show great promise for enabling and extending applications in BI, DW, DI, and analytics. But are user organizations actively adopting HDFS?
To quantify this situation, this report’s survey asked: When do you expect to have HDFS in production? (See Figure 1.) The question asks about HDFS, because in most situations (excluding some uses of MapReduce) an HDFS cluster must first be in placed before other Hadoop products and hand-coded solutions are deployed atop it. Survey results reveal important facts about the status of HDFS implementations. A slight majority of survey respondents are BI/DW professionals, so the survey results represent the broad IT community, but with a BI/DW bias.
-
HDFS is used by a small minority of organizations today. Only 10% of survey respondents report having reached production deployment.
-
A whopping 73% of respondents expect to have HDFS in production. 10% are already in production, with another 63% upcoming. Only 27% of respondents say they will never put HDFS in production.
-
HDFS usage will go from scarce to ensconced in three years. If survey respondents’ plans pan out, HDFS and other Hadoop products and technologies will be quite common in the near future, thereby having a large impact on BI, DW, DI, and analytics – plus IT and data management in general, and how businesses leverage these.
Figure 1. Based on 263 respondents: When do you expect to have HDFS in production?
10% = HDFS is already in production
28% = Within 12 months
13% = Within 24 months
10% = Within 36 months
12% = In 3+ years
27% = Never
Hadoop: Problem or Opportunity for BI/DW?
Hadoop is still rather new, and it’s often deployed to enable other practices that are likewise new, such as big data management and advanced analytics. Hence, rationalizing an investment in Hadoop can be problematic. To test perceptions of whether Hadoop is worth the effort and risk, this report’s survey asked: Is Hadoop a problem or an opportunity? (See Figure 3.)
-
The vast majority (88%) consider Hadoop an opportunity. The perception is that Hadoop products enable new applications types, such as the sessionization of Web site visitors (based on Web logs), monitoring and surveillance (based machine and sensor data), and sentiment analysis (based on unstructured data and social media data).
-
A small minority (12%) consider Hadoop a problem. Fully embracing multiple Hadoop products requires a fair amount of training in hand-coding, analytic, and big data skills that most BI/DW and analytics teams lack at the moment. But (at a mere 12%) few users surveyed consider Hadoop a problem.
Figure 3. Based on 263 respondents: Is Hadoop a problem or an opportunity?
88% = Opportunity – because it enables new application types
12% = Problem – because Hadoop and our skills for it are immature
Want more? Register for my Hadoop4BIDW Webinar, coming up April 9, 2013 at noon ET: http://bit.ly/Hadoop13
Posted by Philip Russom, Ph.D.0 comments
Blog by Philip Russom
Research Director for Data Management, TDWI
To help you better understand High-Performance Data Warehousing (HiPerDW) and why you should care about it, I’d like to share with you the series of 34 tweets I recently issued. I think you’ll find the tweets interesting, because they provide an overview of HiPerDW in a form that’s compact, yet amazingly comprehensive.
Every tweet I wrote was a short sound bite or stat bite drawn from my recent TDWI report on HiPerDW. Many of the tweets focus on a statistic cited in the report, while other tweets are definitions stated in the report.
I left in the arcane acronyms, abbreviations, and incomplete sentences typical of tweets, because I think that all of you already know them or can figure them out. Even so, I deleted a few tiny URLs, hashtags, and repetitive phrases. I issued the tweets in groups, on related topics; so I’ve added some headings to this blog to show that organization. Otherwise, these are raw tweets.
Defining High-Performance Data Warehousing (#HiPerDW)
1. The 4 dimensions of High-Performance Data Warehousing (#HiPerDW): speed, scale, complexity, concurrency.
2. High-performance data warehousing (#HiPerDW) achieves speed & scale, despite complexity & concurrency.
3. #HiPerDW 4 dimensions relate. Scaling requires speed. Complexity & concurrency inhibit speed & scale.
4. High-performance data warehousing (#HiPerDW) isn't just DW. #BizIntel, #DataIntegration & #Analytics must also perform.
5. Common example of speed via high-performance data warehousing (#HiPerDW) = #RealTime for #OperationalBI.
6. A big challenge to high-performance data warehousing (#HiPerDW) = Scaling up or out to #BigData volumes.
7. Growing complexity & diversity of sources, platforms, data types, & architectures challenge #HiPerDW.
8. Increasing concurrency of users, reports, apps, #Analytics, & multiple workloads also challenge #HiPerDW.
HiPerDW Makes Many Applications Possible
9. High-performance data warehousing (#HiPerDW) enables fast-paced, nimble, competitive biz practices.
10. Extreme speed/scale of #BigData #Analytics requires extreme high-performance warehousing (#HiPerDW).
11. #HiPerDW enables #OperationalBI, just-in-time inv, biz monitor, price optimiz, fraud detect, mobile mgt.
HiPerDW is An Opportunity
12. #TDWI SURVEY SEZ: High-performance data warehousing (#HiPerDW) is mostly opportunity (64%); sometimes problem (36%).
13. #HiPerDW is an opportunity because it enables new, broader and faster data-driven business practices.
14. #TDWI SURVEY SEZ: 66% say High Perf #DataWarehousing (#HiPerDW) is extremely important. 6% find it a non-issue.
15. #TDWI SURVEY SEZ: Most performance improvements are responses to biz demands, growth, or slow tools.
New Options for HiPerDW
16. Many architectures support High-Perf #DataWarehousing (#HiPerDW): MPP, grids, clusters, virtual, clouds.
17. #HiPerDW depends on #RealTime functions for: streaming data, buses, SOA, event processing, in-memory DBs.
18. Many hardware options support #HiPerDW: big memory, multi-core CPUs, Flash memory, solid-state drives.
19. Innovations for Hi-Perf #DataWarehousing (#HiPerDW) = appliance, columnar, #Hadoop, #MapReduce, InDB #Analytics.
20. Vendor tools are indispensible, but #HiPerDW still requires optimization, tweaks & tuning by tech users.
Benefits and Barriers for HiPerDW
21. #TDWI SURVEY SEZ: Any biz process or tech that’s #Analytics, #RealTime or data-driven benefits from #HiPerDW.
22. #TDWI SURVEY SEZ: Biggest barriers to #HiPerDW are cost, tool deficiencies, inadequate skills, & #RealTime.
Replacing DW to Achieve HiPerDW
23. #TDWI SURVEY SEZ: 1/3 of users will replace DW platform within 3 yrs to boost performance. #HiPerDW
24. #TDWI SURVEY SEZ: Top reason to replace #EDW is scalability. Second reason is speed. #HiPerDW
25. #TDWI SURVEY SEZ: The number of analytic datasets in 100-500+ terabyte ranges will triple. #HiPerDW
HiPerDW Best Practices
26. #TDWI SURVEY SEZ: 61% their top High-Performance DW method (#HiPerDW) is ad hoc tweaking & tuning.
27. #TDWI SURVEY SEZ: Bad news: Tweaking & tuning for #HiPerDW keeps developers from developing.
28. #TDWI SURVEY SEZ: Good news: Only 9% spend half or more of time tweaking & tuning for #HiPerDW.
29. #TDWI SURVEY SEZ: #HiPerDW methods: remodeling data, indexing, revising SQL, hardware upgrade.
30. BI/DW team is responsible for high-performance data warehousing (#HiPerDW), then IT & architects.
HiPerDW Options that will See Most Growth
31. #HiPerDW priorities for hardware = server memory, computing architecture, CPUs, storage.
32. #TDWI SURVEY SEZ: In-database #Analytics will see greatest 3-yr adoption among #HiPerDW functions.
33. #TDWI SURVEY SEZ: Among High-Perf #DataWarehouse functions (#HiPerDW), #RealTime ones see most adoption.
34. #TDWI SURVEY SEZ: In-memory databases will also see strong 3-yr growth among #HiPerDW functions.
FOR FURTHER STUDY:
For a more detailed discussion of High-Performance Data Warehousing (HiPerDW) – in a traditional publication! – see the TDWI Best Practices Report, titled “High-Performance Data Warehousing,” which is available in a PDF file via download.
You can also register for and replay my TDWI Webinar, where I present the findings of the TDWI report on High-Performance Data Warehousing (HiPerDW).
If you're not already, please follow me as @prussom on Twitter.
Posted by Philip Russom, Ph.D.0 comments
By Philip Russom, TDWI Research Director
[NOTE -- My new TDWI report about High-Performance Data Warehousing (HiPer DW) is finished and will be published in October. The report’s Webinar will broadcast on October 9, 2012. In the meantime, I’ll leak a few of the report’s findings in this blog series. Search Twitter for #HiPerDW to find other leaks. Enjoy!]
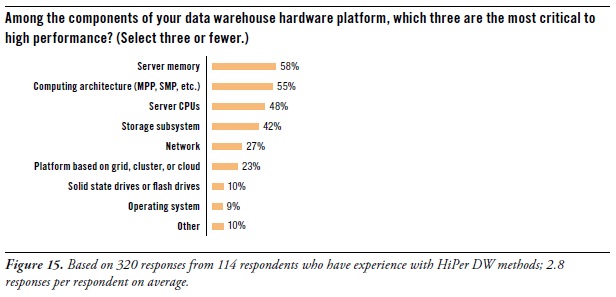
Let’s focus for a moment on the hardware components of a data warehouse platform. After all, many of the new capabilities and high performance of data warehouses come from recent advances in computer hardware of different types. To determine which hardware components contribute most to HiPer DW, the survey asked: “Among the components of your data warehouse hardware platform, which three are the most critical to high performance?” (See Figure 15. [shown above])
You may notice that the database management system (DBMS) is omitted from the list of multiple answers for this question. That’s because a DBMS is enterprise software, and this question is about hardware. However, let’s note that – in other TDWI surveys – respondents made it clear that they find the DBMS to be most critic component of a DW platform, whether for high performance, data modeling possibilities, BI/DI tool compatibility, in-database processing logic, storage strategies, or administration.
Performance priorities for hardware are server memory, computing architecture, CPUs, and storage.
Server memory topped respondents’ lists as most critical to high performance (58% of survey respondents). Since 64-bit computing arrived ten years ago, data warehouses (like other platforms in IT) have migrated away from 32-bit platform components, mostly to capitalize on the massive addressable memory spaces of 64-bit systems. As the price of server memory continues to drop, more organizations upgrade their DW servers with additional memory; 256 gigabytes seems common, although some systems are treated to a terabyte or more. To a lesser degree, users are also upgrading ETL and EBI servers. “Big memory” speeds up complex SQL, joins, and analytic model rescores due to less I/O to land data to disk.
Computing architecture (55%) also determines the level of performance. In other TDWI surveys, respondents have voiced their frustration at using symmetrical multi-processing systems (SMP), which were originally designed for operational applications and transactional servers. The DW community definitely prefers massively parallel processing (MPP) systems, which are more conducive to the large dataset processing of data warehousing.
Server CPUs (48%) are obvious contributors to HiPer DW. Moore’s Law once again takes us to a higher level of performance, this time with multi-core CPUs at reasonable prices.
We sometimes forget about storage (42%) as a platform component. Perhaps that’s because so many organizations now have central IT departments that provide storage as an ample enterprise resource, similar to how they’ve provided networks for decades. The importance of storage grows as big data grows. Luckily, storage has kept up with most of the criteria of Moore’s Law, with greater capacity, bandwidth, reliability, and capabilities, while also dropping in price. However, disk performance languished for decades (in terms of seek speeds), until the recent invention of solid-state drives, which are slowly finding their way into storage systems.
USER STORY -- Caching OLAP cubes in server memory provides high-performance drill down. “Within our enterprise BI program, we have business users who depend on OLAP-based dashboards for making daily strategic and tactical decisions,” said the senior director of BI architecture at a media firm. “To enable drill down from management dashboards into cube details, we maintain cubes in server memory, and we refresh them daily. We’ve only been doing this a few months, as part of a pilot program. The performance is good, and we received very positive feedback from the users. So it looks like we’ll do this for other dashboards in the future. To prepare for that eventuality, we just upgraded the memory in our enterprise BI servers.”
On a related topic, one of the experts interviewed for this report had this to add: “As memory chip density increases, the price comes down. Price alone keeps most server memory down to one terabyte or less today. But multi-terabyte server memory will be common in a few years.”
Want more? Register for my HiPer DW Webinar, coming up Oct.9 noon ET.
Read other blogs in this series:
Reasons for Developing HiPer DW
Opportunities for HiPer DW
The Four Dimensions of HiPer DW
Defining HiPer DW
High Performance: The Secret of Success and Survival
Posted by Philip Russom, Ph.D.0 comments