Hadoop Technologies in Use Today and Tomorrow
By Philip Russom, TDWI Research Director
[NOTE -- My new TDWI report “Integrating Hadoop into Business Intelligence (BI) and Data Warehousing (DW)” (Hadoop4BIDW) is finished and will be published in early April. I will broadcast the report’s Webinar on April 9, 2013. In the meantime, I’ll leak a few of the report’s findings in this blog series. Search Twitter for #Hadoop4BIDW, #Hadoop, and #TDWI to find other leaks. Enjoy!]
This report considers Hadoop an ecosystem of products and technologies. Note that some are more conducive to applications in BI, DW, DI, and analytics than others; and certain product combinations are more desirable than others for such applications.
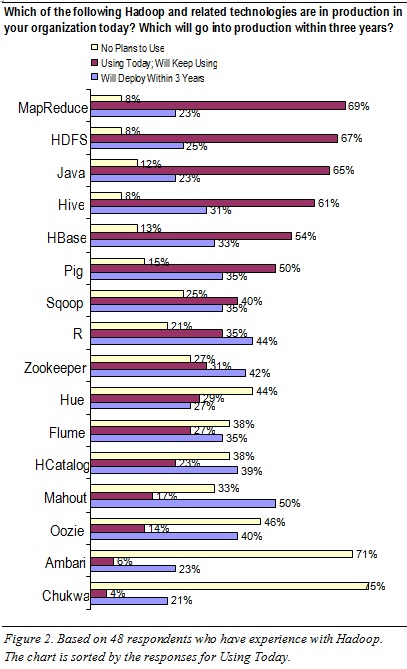
To sort out which Hadoop products are in use today (and will be in the near future), this report’s survey asked: Which of the following Hadoop and related technologies are in production in your organization today? Which will go into production within three years? Which will you never use? (See Figure 2 above.) These questions were answered by a subset of 48 survey respondents who claim they’ve deployed or used HDFS. Hence, their responses are quite credible, being based on direct hands-on experience.
HDFS and a few add-ons are the most commonly used Hadoop products today. HDFS is near the top of the list (67% in Figure 2), because most Hadoop-based applications demand HDFS as the base platform. Certain add-on Hadoop tools are regularly layered atop HDFS today:
- MapReduce (69%). For the distributed processing of hand-coded logic, whether for analytics or for fast data loading and ingestion
- Hive (60%). For projecting structure onto Hadoop data, so it can be queried using a SQL-like language called HiveQL
- HBase (54%). For simple, record-store database functions against HDFS’ data
MapReduce is used even more than HDFS. The survey results (which rank MapReduce slightly more common than HDFS) suggest that a few respondents in this survey population are using MapReduce today without HDFS, which is possible, as noted earlier. The high MapReduce usage also explains why Java and R ranked fairly high in the survey; these programming languages are not Hadoop technologies per se, but are regularly used for the hand-coded logic that MapReduce executes. Likewise, Pig ranked high in the survey, being a tool that enables developers to design logic (for MapReduce execution) without having to hand-code it.
Some Hadoop products are rarely used today. For example, few respondents in this survey population have touched Chukwa (4%) or Ambari (6%), and most have no plans for using them (75% and 71%, respectively). Oozie, Hue, and Flume are likewise of little interest at the moment.
Some Hadoop products are poised for aggressive adoption. For example, half of respondents (50%) say they’ll adopt Mahout within three years, with similar adoption projected for R (44%), Zookeeper (42%), HCatalog (40%), and Oozie (40%).
TDWI sees a few Hadoop products as especially up-and-coming. Usage of these will be driven up according to user demand. For example, users need analytics tailored to the Hadoop environment, as provided by Mahout (machine-learning based recommendations, classification, and clustering) and R (a programming language specifically for analytics). Furthermore, BI professionals are accustomed to DBMSs, and so they long for a Hadoop-wide metadata store and far better tools for HDFS administration and monitoring; these user needs are being addressed by HCatalog and Ambari, respectively, and therefore TDWI expects both to become more popular.
Want more? Register for my Hadoop4BIDW Webinar, coming up April 9, 2013 at noon ET: http://bit.ly/Hadoop13
Posted by Philip Russom, Ph.D.