Hadoop has limitations. But the relational database management systems used for data warehousing do, too. Luckily, their strengths are complementary.
By Philip Russom, TDWI Research Director for Data Management
In a recent blog in this series, I discussed “The Roles of Hadoop” in evolving data warehouse architectures. (There’s a link to that blog at the end of this blog.) In response, a few people asked me (I’m paraphrasing): “Since the Hadoop Distributed File System (HDFS) is so useful, can it replace the relational database management system (RDBMS) that’s at the base of my current data warehouse and its architecture?”
The short answer is: “No.” The long answer is: “Not today, and probably not in the future.” The main reason is that Hadoop—in its current form—lacks (or is weak with) many of the functions that we depend on in our RDBMSs. As you’ll see in the list below, most of the RDBMS functions I have in mind enable feature-rich and high-performance access to stored data via SQL. Other functions concerns tools for data security and administration.
Just so you know where this blog is going: Hadoop has limitations, but the average data warehouse does, too. Luckily, the strengths and weaknesses of the two are complementary (for the most part). When you integrate Hadoop and an RDBMS, they fill in each other’s holes and provide a more broadly capable data warehouse architecture than has been possible until now.
Hadoop’s Limitations Relative to RDBMSs Used for Data Warehousing
Despite all the goodness of Hadoop I described in a previous blog, there are areas within data warehouse architectures where HDFS isn’t such a good fit:
RDBMS functionality. HDFS is a distributed file system and therefore lacks capabilities we expect from relational database management systems (RDBMSs), such as indexing, random access to data, support for standard SQL, and query optimization. But that’s okay, because HDFS does things RDBMSs do not do as well, such as managing and processing massive volumes of file-based, unstructured data. For minimal DBMS functionality (though not fully relational), users can layer HBase over HDFS, as well as the query framework called Hive.
Low-latency data access and queries. HDFS’s batch-oriented, serial-execution engine means that it’s not the best platform for real-time or speedy data access or queries. Furthermore, Hadoop lacks mature query optimization. Hence, the selective random access to data and iterative ad hoc queries that we take for granted with RDBMSs are alien to Hadoop.
An RDBMS integrated with Hadoop can provide needed query support. HBase is a possible solution, if all you need is a record store, not a full-blown DBMS. And upcoming improvements to Hadoop Hive and the new Impala query engine will address some of the latency issues.
Streaming data. HDFS and other Hadoop products can capture data from streaming sources (Web servers, sensors, machinery) and append it to files. But, being inherently batch, they are ill-equipped to process that data in real time. In my opinion at this date, such extremes of real-time analytics are best done with specialized tools for complex event processing (CEP) and/or operational intelligence (OI) from third-party vendors.
Granular security. Hadoop today includes a few security features, such as file-permission checks, access control for job queues, and service-level authorization. Add-on products that provide encryption and LDAP integration are available for Hadoop from a few third-party vendors. Since HDFS is not a DBMS (and Hadoop data doesn’t necessarily come in relational structures), don’t expect granular security at the row or field level, as in an RDBMS.
Administrative tools. According to a TDWI survey, security is Hadoop users’ most pressing need, followed by a need for better administrative tools, especially for cluster deployment and maintenance. The good news is that a few vendors offer tools for Hadoop administration, and an upgrade of open-source Ambari is coming.
SQL-based analytics. With the above latency limitations in mind, HDFS is a problematic choice for workloads that are iterative and query based, as with SQL-based analytics. Furthermore, Hadoop products today have limited support for standard SQL. A number of vendor products (from RDBMSs to data integration and reporting tools) can provide SQL support today, and open-source Hadoop has new incubator projects that will eventually provide adequate support for SQL. These are critical if Hadoop is to become a productive part of a SQL-driven data warehouse architecture.
I’m not making up these limitations for Hadoop. The list is based on survey results and user interviews, as reported in my 2013 TDWI Best Practices Report:
Integrating Hadoop into BI and Data Warehousing.
In Defense of Hadoop
My list of limitations might seem like “Hadoop bashing” to some readers, but that is not what I intend. So let me restate what I stated positively in the last blog: “HDFS and other Hadoop tools promise to extend and improve some areas within data warehouse architectures.”
Sure, Hadoop’s help is limited to “some areas.” But the fantastically fortuitous fact is that most of Hadoop’s strengths are in areas where most warehouses and BI technology stacks are weak, such as unstructured data, outrageously large data sets, non-SQL algorithmic analytics, and the flood of files that’s drowning many of us. Conversely, Hadoop’s limitations (as discussed above) are mostly met by mature functionality available today from a wide range of RDBMS types (OLTP databases, columnar databases, DW appliances, etc.), plus admin tools. In that light, I hope it’s clear that Hadoop and the average data warehouse are complementary (despite a bit of overlap), so it’s unlikely that one could replace the other, as I am often asked.
Integrating Hadoop with an RDBMS Alleviates the Limitations of Both
The trick, of course, is making HDFS and an RDBMS work together optimally. To that end, one of the critical success factors for assimilating Hadoop into evolving data warehouse architectures is the improvement of interfaces and interoperability between HDFS and RDBMSs. Luckily, this is well under way, due to efforts from software vendors and the open source community. And technical users are starting to leverage HDFS/RDBMS integration.
For example, an emerging best practice among DW professionals with Hadoop experience is to manage diverse big data in HDFS, but process it and move the results (via ETL or other data integration media) to RDBMSs (elsewhere in the DW architecture) that are more conducive to SQL-based analytics. HDFS serves as a massive data staging area. A similar best practice is to use an RDBMS as a front-end to HDFS data; this way, data is moved via queries (whether ad hoc or standardized), not via ETL jobs. HDFS serves as a large, diverse operational data store. For more information about these practices, replay my recent TDWI Webinar: "
Ad Hoc Query Speed for Hadoop."
Other Blogs in the Evolving Data Warehouse Architectures series:
•
From EDW to DWE
•
The Role(s) of Hadoop
Posted by Philip Russom, Ph.D.0 comments
I am in the process of collecting data for my TDWI Best Practices Report on predictive analytics. The report will look at trends and best practices for predictive analytics. Some specific issues being investigated in the survey include: Who is using predictive analytics? What skills are needed for it? Is it being used in big data analysis? Is it being used in the cloud? What kind of data is being used for predictive analytics? What infrastructure is supporting it? What is the value that people using it are getting from it? The survey is slated to run another week, so if you haven’t had the chance to take it yet, please do. Here is the link:
I define predictive analytics as a statistical or data mining solution consisting of algorithms and techniques that can be used on both structured or unstructured data (together or individually) to determine future outcomes. It can be deployed for prediction, optimization, forecasting, simulation, and many other uses.
One of the first questions I ask in the survey is, “What is the status of predictive analytics in your organization?” To date, 37% of the respondents are currently utilizing predictive analytics, 53% are exploring it, and less than 10% have no plans to use it. Please note that this survey is not meant to determine the adoption of predictive analytics. The group who answered the survey might have been self-selecting in that those who are not using predictive analytics may have chosen not to respond to the survey, at all. One reason I asked this question was to be able to look at any differences between the two groups.
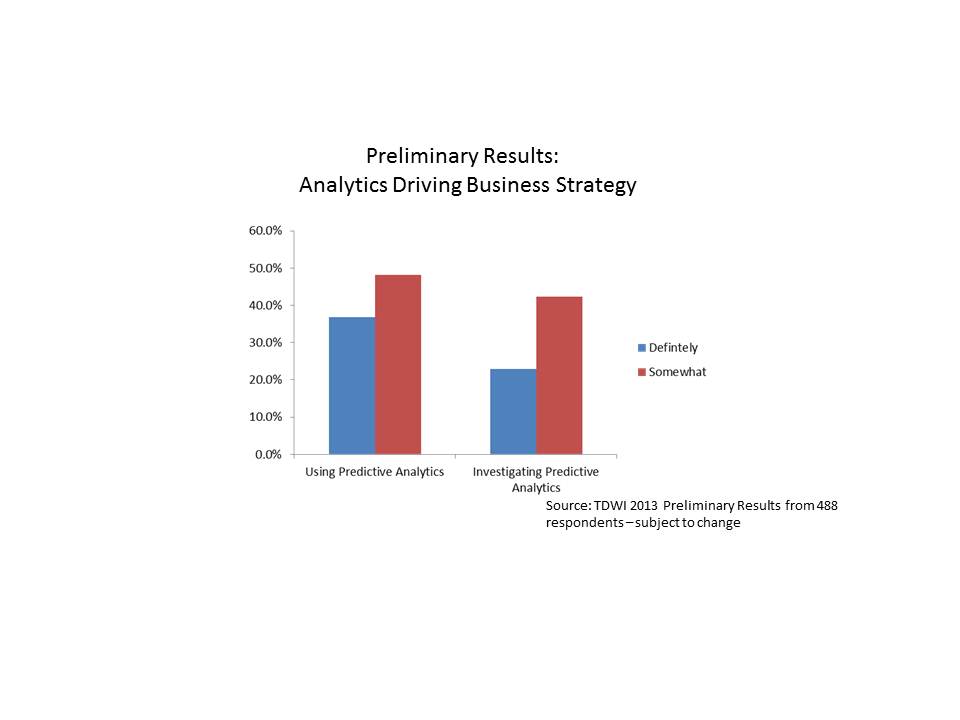
We asked the following question: “Would you say that analytics underpins your organization’s business strategy and drives day-to-day decisions?” The preliminary breakdown of responses is shown below.
Interestingly, those respondents who are already using predictive analytics were more likely to respond that analytics (in general) underpins their organization’s strategy and drives day-to-day decisions. About 37% of those respondents who are already using predictive analytics stated that analytics definitely underpins their day-to-day decision making, while only about 23% of those investigating the technology stated the same. Another way of looking at it is that 85% of those respondents using predictive analytics state that analytics is driving their day-to-day decisions in some way (i.e., answered definitely or somewhat), while only 65% of those who are investigating use analytics to drive day-to-day decisions and strategy.
Does this use of predictive analytics to drive strategy and decisions provide a benefit? It would appear so from preliminary results of the survey (of course subject to change). Close to 50% of the respondents who now use predictive analytics have actually measured a top or bottom line benefit or both from their predictive analytics efforts.
These preliminary results are quite interesting and I’m looking forward to getting all the data and analyzing the results! The TDWI Best Practices Report will be published later this year. I will continue to provide some updates here, along the way. So, stay tuned!
Posted by Fern Halper, Ph.D.0 comments
HDFS and other Hadoop tools promise to extend and improve some areas within data warehouse architectures
By Philip Russom, TDWI Research Director for Data Management
In a TDWI survey I designed and ran in 2012, 88% of the users surveyed reported that the Hadoop ecosystem of products is a business opportunity (not a technology problem) because it enables new types of applications. When asked which types of applications benefit most from Hadoop, survey respondents chose (in priority order) big data analytics, advanced analytics (i.e., data mining, statistical analysis, and complex SQL), and discovery analytics. After these three analytic application types, respondents then chose two data management use cases for Hadoop, namely information exploration and complementing a data warehouse. Other data management uses seen in the survey include data archiving, transforming big data for analytics, and data staging.
If you pull together all the things I just mentioned, it’s quite a list of use cases in data warehousing for the Hadoop Distributed File System (HDFS) and other Hadoop tools (MapReduce, Hive, HBase, HCatalog, Impala, etc.). And many of these—if implemented in a multi-platform data warehouse environment (DWE)—would have a strong influence on the architecture of that data environment.
Promising Uses of Hadoop that Impact DW Architectures
I see a handful of areas in data warehouse architectures where HDFS and other Hadoop products have the potential to play positive roles:
Data staging. A lot of data processing occurs in a DW’s staging area, to prepare source data for specific uses (reporting, analytics, OLAP) and for loading into specific databases (DWs, marts, appliances). Much of this processing is done by homegrown or tool-based solutions for extract, transform, and load (ETL). Imagine staging and processing a wide variety of data on HDFS.
For users who prefer to hand-code most of their solutions for extract, transform, and load (ETL), they will most likely feel at home in code-intense environments like Apache MapReduce. And they may be able to refactor existing code to run there. For users who prefer to build their ETL solutions atop a vendor tool, the community of vendors for ETL and other data management tools is rolling out new interfaces and functions for the entire Hadoop product family.
Note that I’m assuming that (whether you use Hadoop or not), you should physically locate your data staging area(s) on standalone systems outside the core data warehouse, if you haven’t already. That way, you preserve the core DW’s capacity for what it does best: squeaky clean, well-modeled data (with an audit trail via metadata and master data) for standard reports, dashboards, performance management, and OLAP. In this scenario, the standalone data staging area(s) offload most of the management of big data, archiving source data, and much of the data processing for ETL, data quality, and so on.
Data archiving. When organizations embrace forms of advanced analytics that require detail source data, they amass large volumes of source data, which taxes areas of the DW architecture where source data is stored. Imagine managing detailed source data as an archive on HDFS.
You probably already do archiving with your data staging area, though you probably don’t call it archiving. If you think of it as an archive, maybe you’ll adopt the best practices of archiving, especially information life cycle management (ILM), which I feel is valuable but woefully vacant from most DWs today. Archiving is yet another thing the staging area in a modern DW architecture must do, thus another reason to offload the staging area from the core DW platform.
Traditionally, enterprises had three options when it came to archiving data: leave it within a relational database, move it to tape or optical disk, or delete it. Hadoop’s scalability and low cost enable organizations to keep far more data in a readily accessible online environment. An online archive can greatly expand applications in business intelligence, advanced analytics, data exploration, auditing, security, and risk management.
Multi-structured data. Relatively few organizations are getting BI value from semi-structured and unstructured data, despite years of wishing for it. Imagine HDFS as a special place within your DW environment for managing and processing semi-structured and unstructured data. Another way to put it is: imagine not stretching your RDBMS-based DW platform to handle data types that it’s not all that good with.
One of Hadoop’s strongest complements to a DW is its handling of semi-structured and unstructured data. But don’t go thinking that Hadoop is only for unstructured data; HDFS handles the full range of data, including structured forms, too. In fact, Hadoop can manage just about any data you can store in a file and copy into HDFS.
Processing flexibility. Given its ability to manage diverse multi-structured data, as I just described, Hadoop’s NoSQL approach is a natural framework for manipulating non-traditional data types. Note that these data types are often free of schema or metadata, which makes them challenging for SQL-based relational DBMSs. Hadoop supports a variety of programming languages (Java, R, C), thus providing more capabilities than SQL alone can offer.
In addition, Hadoop enables the growing practice of “late binding.” Instead of transforming data as it’s ingested by Hadoop (the way you often do with ETL for data warehousing), which imposes an a priori model on data, structure is applied at runtime. This, in turn, enables the open-ended data exploration and discovery analytics that many users are looking for today.
Advanced analytics. Imagine HDFS as a data stage, archive, or twenty-first-century operational data store that manages and processes big data for advanced forms of analytics, especially those based on MapReduce, data mining, statistical analysis, and natural language processing (NLP). There’s much to say about this; in a future blog I’ll drill into how advanced analytics is one of the strongest influences on data warehouse architectures today, whether Hadoop is in use or not.
Stay tuned, because I’ll soon post more blogs about evolving data warehouse architectures. In the meantime, please read the new TDWI Checklist “
Where Hadoop Fits in Your Data Warehouse Architecture.”
Other blogs in the Evolving Data Warehouse Architectures series:
•
From EDW to DWE
Posted by Philip Russom, Ph.D.0 comments
Many Enterprise Data Warehouses (EDWs) are evolving into multi-platform Data Warehouse Environments (DWEs)
By Philip Russom, TDWI Research Director for Data Management
Analytics, big data, real time, and unstructured data present new data warehouse (DW) workloads.
Workload-centric DW architecture. One way to measure a data warehouse’s architecture is to count the number of workloads it supports. According to the TDWI Survey on High-Performance Data Warehousing of 2012, a little over half of user organizations surveyed (55%) support only the most common workloads, namely those for standard reports, performance management, and online analytic processing (OLAP). The other half (45%) also supports workloads for advanced analytics, detailed source data, various forms of big data, and real-time data feeds.
The trend is toward the latter. In other words, the number and diversity of DW workloads is increasing, due to organizations embracing big data, multi-structured data, real-time or streaming data, and data processing for advanced analytics. The catch is that some data warehouses (whether defined as a vendor product or a user’s design) can handle multiple, concurrent workloads of various types, whereas others cannot.
The diversification of DW workloads leads to distributed architectures for DWs.
Distributed DW architecture. The issue in a multi-workload environment is whether a single-platform data warehouse can be designed and optimized such that all workloads run optimally, even when concurrent. More and more DW teams are concluding that a single-platform DW is no longer desirable. Instead, they maintain a core DW platform for traditional workloads (reports, performance management, and OLAP), but offload other workloads to other platforms. For these organizations, the DW is not going away; it’s just being complemented by additional data platforms tuned to workloads that can and should be offloaded from the core warehouse.
For example, data and processing for SQL-based analytics are regularly offloaded to DW appliances and columnar DBMSs. And a few teams offload workloads for big data and advanced analytics to HDFS, MapReduce, and other NoSQL platforms. The result is a strong trend toward distributed DW architectures, where many areas of the logical DW architecture are physically deployed on standalone platforms instead of the core DW platform.
A distributed DW architecture is both good and bad. It’s good if your fidelity to business requirements and DW performance lead you to deploy another data platform in your DW environment, and the new platform integrates well with others in the distributed architecture. But it’s bad when disconnected systems proliferate uncontrolled, like the errant data marts we all fear. So far, the newest generation of analytic databases and data management platforms are controlled by users far better than the marts of yore. But you still have to be diligent to avoid abuses.
Also, note that the architectural distinctions made here have always been a matter of degree, and will continue to be so. In other words, no architecture is 100% monolithic or 100% distribution. Many are hybrids, and the percentage right for you depends on many matters of business and technology. Many DW architectures have always been distributed, to some degree. It's just that the degree is more pronounced today.
The trend toward a distributed DW architectures isn’t new. Not by a long shot. For decades, warehouses have wended their way through a variety of “edge systems” that are deployed on standalone servers off to the side of the warehouse, but integrated with it. This has been true from the dawn of warehousing (as with data marts and operational data stores (ODSs)), though recently expanded (with DW appliances and columnar DBMSs), and now continuing with new types of data platforms (namely NoSQL and Hadoop). Hence, even the new platforms fit comfortably into the well-established tradition of DW edge systems.
Rearrange the acronym from EDW to DWE, standing for “data warehouse environment,” meaning multi-platform DW.
From the single-platform EDW to the multi-platform DWE. A consequence of the workload-centric approach is a trend away from the single-platform monolith of the enterprise data warehouse (EDW) toward a physically distributed data warehouse environment (DWE). A modern DWE consists of multiple platform types, ranging from the traditional warehouse (and its satellite systems for marts and ODSs) to new platforms like DW appliances, columnar DBMSs, noSQL databases, MapReduce tools, and HDFS. In other words, users’ portfolios of tools for BI/DW and related disciplines are diversifying aggressively.
The multi-platform approach adds more complexity to the DW environment, but BI/DW professionals have always managed complex technology stacks successfully. The upside is that users love the high performance and solid information outcomes that they get from workload-tuned platforms.
Note that a DWE can be a simple bucket of standalone silos, and that’s where many organizations are today. Ideally, the physically distinct systems of the DWE should be integrated with others, so they connect via an overall logical design. Integration within the DWE can take many forms, including shared dimensions, data sync, federation, data flows across DWE platforms, and so on. Unless the platforms of a DWE are integrated at appropriate levels, the DWE is just a bucket of silos, whereas it will be more efficient technically and more effective for business users if it has an architectural design that unifies it.
Stay tuned, because I’ll soon post more blogs about evolving data warehouse architectures. In the meantime, please attend an upcoming TDWI Webinar, in which I’ll address many of the issues mentioned here. Register online for the Webinar Big Data and Your Data Warehouse, to be broadcast September 5, 2013 at 9:00am ET.
Posted by Philip Russom, Ph.D.0 comments
Good information and analytics are vital to enabling organizations of all stripes to survive tumultuous changes in the healthcare landscape. The latest issue of TDWI’s
What Works in Healthcare focuses on data-driven transformations in healthcare. I wrote an article for the issue that looks at some of the business intelligence and analytics issues surrounding the transition from a traditional, fee-for-service system to a value-based, “continuum of care” approach. One thing is clear: The importance of data and information integration as the fabric of this approach cannot be overstated.
A continuum (or “continuity”) of care is where a patient’s care experiences are connected across multiple providers: doctors, therapists, clinics, hospitals, pharmacies, and so on, including social programs. The traditional, fee-based approach has encouraged a disconnected experience for patients; visits to providers are mutually exclusive events and their patient data also lives in disparate silos. This disconnect increases the risk of patients getting the wrong treatments, taking medications improperly due to poor follow-up, or falling through the cracks entirely until there is an emergency. When patients only engage with healthcare when there is an emergency, costs go up. If there is poor follow-up after a hospital or emergency care visit, there is a greater likelihood that patients will have to be readmitted soon for the same problem.
Information integration plays a key role in the business model convergence that many experts envision as essential to improving care. “We see new partnerships or communities of care forming to improve collaboration across boundaries,” said Karen Parrish, IBM VP of Industry Solutions for the Public Sector during a recent conversation about IBM’s
Smarter Care. IBM’s ambitious program, announced in May, “enables new business and financial models that encourage interaction among government and social programs, healthcare practitioners and facilities, insurers, employers, life sciences companies and citizens themselves,” according to the company. Improving the continuum of a particular patient’s care among these participants will require good quality data and fewer barriers to the flow of information so that the right caregivers are involved, depending on the circumstances.
At the center of this information flow must be the patient. “Access to the unprecedented amount of data available today creates an opportunity for deeper insight and earlier intervention and engagement with the patient,” said Parrish. This includes unstructured data, such as doctor’s notes. In an insightful
interview with TDWI’s Linda Briggs, Ted Corbett, founder of Vizual Outcomes (and a speaker at the upcoming TDWI
BI Executive Summit in San Diego) points out that while unstructured data “houses some of the richest data in the hospital system…there is little consistency across providers in note format, which makes it difficult to access this rich store of information.”
To improve the speed and quality of unstructured data analysis, IBM puts forth its cognitive computing engine
Watson, which understands natural language. While Watson and cognitive computing are topics for another day, it’s clear that when we talk about information integration in healthcare, we have to remember that the vast majority of this information is unstructured. There will be increasing demand to apply machine learning and other computing power to draw intelligence from an integrated view of multiple sources of this information to improve patient care and treatment.
Posted by David Stodder0 comments
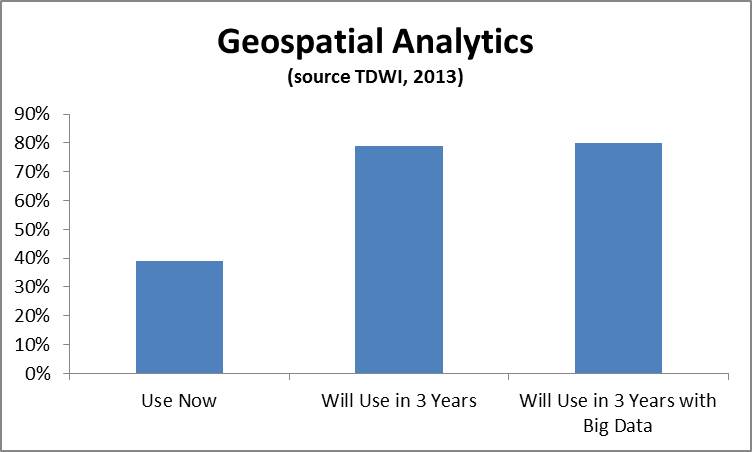
Geospatial data can be extremely powerful for a wide variety of use cases. Geospatial analysis – i.e. the practice of incorporating spatial characteristics in various kinds of analysis- has been incorporated in BI and visualization solutions for at least several years. Recently I’ve been hearing a lot from vendors about geospatial applications and using geospatial data in a range of more advanced analytics. In a recent TDWI technology survey, you can see that the geospatial analytics is growing in importance. We asked the respondents, “What kind of analytics are you currently using in your organization today to analyze data? In three years?” and “What kinds of techniques and tools is your organization using for big data analysis both today and in three years?” In the figure below, the 39% of respondents were currently using geospatial analysis and this number jumped to 79% in three years. The number of respondents answering affirmatively that geospatial analysis would be used in their big data solutions in three years was 81%.
Companies are becoming excited by the prospect of incorporating geospatial data into analysis. In terms of more advanced analytics, here are few examples of the kinds of analysis I’ve been hearing about:
- Predictive analytics. Geo-location data is being incorporated into predictive analytics. The most recent example of this is KXEN (www.kxen.com) announcing support for geo-location in its predictive analytics solution. KXEN will support data sources such as GPS, phone calls, machine sensors, geo-referenced signals, and social media. This includes capabilities for location-awareness, co-location, and path identification. For instance, marketers could use this kind of data to determine how likely someone is to purchase something at a store based on the path they took to get there (based on what others who took similar paths with a similar profile did) and offer a coupon based on this.
- Operational Intelligence. Operational intelligence incorporates analytics as part of a business process. Companies like Vitria (www.vitria.com) that provide operational intelligence solutions, support geospatial data. For instance, a wireless telephone company that monitors its network could use location data to determine which cell tower to fix based on where their high value customers are located.
- Situational Intelligence. Situational intelligence is a technique that integrates and correlates large volumes of multidimensional real time and historical data to identify and act on a problem. Part of that data is often geospatial For example, companies like Space Time Insight (www.spacetimeinsight.com) provide this kind of solution to help companies that deal with physical assets. Visualizing and analyzing this data can help answer questions like what happened, where did it happen, and why did it happen. Companies such as utility companies would use this information to a pinpoint problem and find the closest person to fix it.
I expect to hear a lot more about geospatial data and geospatial analysis moving forward. I’ll be writing more on the topic in the second half of 2013 and in 2014. Stay tuned.
Posted by Fern Halper, Ph.D.0 comments