
Self-Healing and Intelligent Data Delivery at Scale (Part 2 of 2)
A useful template for a self-healing data system consists of five core layers, explained here.
- By Prashanth H. Southekal, Ph.D.
- March 18, 2026
The first part of this article explained the shortcomings of traditional data pipelines and the benefits of self-healing systems.
A Reference Architecture for Self-Healing Data Systems
A reference architecture is essentially a standardized blueprint or template for designing and implementing a system, solution, or technology. It provides a set of guidelines, best practices, and components that can be reused across multiple projects, helping ensure consistency, efficiency, and reliability.
An effective self-healing reference architecture separates concerns and avoids overloading any single component. Separation of concerns (SoC) is a design principle where you divide a solution into distinct sections, and each section handles one specific responsibility. A useful reference architecture for a self-healing data system consists of five core layers.
1. Data Platform (Execution Layer)
The data platform is responsible for ingesting, storing, transforming, and serving data at scale. It enforces schemas and basic data quality checks and is designed for performance and reliability. Remediation actions—such as reprocessing or schema alignment—are applied to this layer, but the platform itself remains focused on execution rather than decision-making. Potential tools can be DBT, Coalesce, SQLMesh, etc.
2. Observability (Detection Layer)
Observability tools continuously monitor data freshness, volume, schema drift, and pipeline health. They surface anomalies and failures early, before bad data impacts downstream consumers. Crucially, observability operates alongside the data platform rather than being deeply embedded within it, reducing coupling and risk. Example tools are Monte Carlo, Datadog, and Dynatrace.
3. Intelligence (Analysis Layer)
Machine learning and generative AI systems form an external intelligence layer. They analyze observability signals, metadata, lineage, and historical incidents to identify root causes and failure patterns. Rather than directly modifying data, they reason about what went wrong and recommend or trigger appropriate remediation actions. OpenAI models, Snowflake Cortex, and Google Vertex AI are some of the options in this layer.
4. Governance (Oversight Layer)
This layer has products and platforms designed to govern AI agents, providing tools to control actions, monitor behavior, enforce policies, and ensure safe and compliant operation of autonomous AI systems. Example tools are OpenAI Frontier, Microsoft Agent 365, WitnessAI, FluxAI, Levo, OneTrust, and Adeptiv.
5. Automation (Healing Layer)
This layer executes policy-driven remediation such as job retries, backfills, schema rollbacks, or data quarantining. CI/CD-managed orchestration ensures fixes are applied safely and reproducibly, with human-in-the-loop oversight and full auditability. Example tools are Airflow, Dagster, and GitHub.
Together, these five layers, as shown below, create a closed loop: detect, understand, heal, and learn.
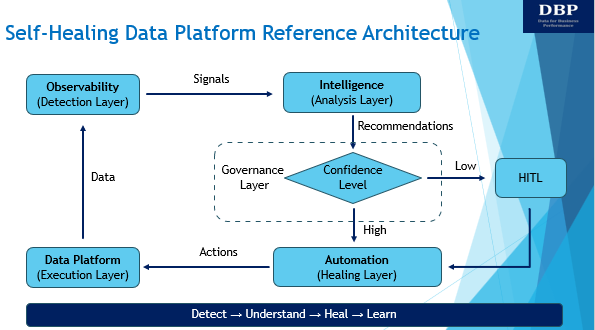
Figure: Reference Architecture for Self-Healing Data Systems
While some enterprises prefer one platform to manage all five layers, there is no single tool that effectively covers all layers from end to end. Databricks, Snowflake, and hyperscalers (like AWS, GCP, and Azure) might address some of them, but there will be some trade-offs to handle.
Challenges and Trade-offs
While self-healing systems offer significant benefits, they introduce some important challenges.
One key trade-off is false positives versus missed failures. Systems that are too sensitive generate noise and unnecessary interventions, while overly conservative systems allow real data issues to slip through. Striking the right balance requires careful validation and tuning of rules and continuous evaluation based on the risk appetite and the changing business circumstances.
Automation is another risk. Automation works only when the process is stable, repetitive, and clearly defined. If the process isn’t standardized, automation will cost more than it saves. Automated fixes applied without sufficient context or guardrails can cause more harm than the original failure. Policy-driven controls and staged autonomy are essential to prevent cascading mistakes.
Data and model drift can pose challenges to self-healing systems. Data drift and model drift quietly change the ground under a self-healing system’s feet. When that happens, the system may still act but no longer act correctly. Every business is an evolving entity, and that means data evolves. This results in the detection models becoming outdated, leading to degraded accuracy. Continuous retraining, validation, and feedback are required to maintain effectiveness.
Finally, governance and auditability are critical. Every automated decision must be explainable and traceable, especially in regulated environments. Trust in self-healing systems depends not only on outcomes, but on transparency.
Conclusion
Self-healing and intelligent data delivery represent a shift in how we think about data reliability. Failures are inevitable at scale, but their impact does not have to be. By treating data quality as a first-class concern, separating execution from intelligence, and combining observability, automation, and governance, organizations can build data systems that protect trust even in the face of constant change.
McKinsey says AI and robotics could technically automate 57% of U.S. work hours if companies fully redesign jobs and workflows. This requires changing the organization structure, workflows, roles, and more to enable the “agentic organization.” Overall, the goal of self-healing is not to eliminate human involvement in data remediation, but to ensure that humans spend less time firefighting data quality issues and more time improving the system so that data remains a critical business asset for improved business performance.
About the Author
Prashanth Southekal, Ph.D., MBA, ICD.D is a data, analytics, and AI consultant, author, and professor. He has consulted for over 100 organizations including P&G, GE, Shell, Apple, AWS, Whirlpool, Husky Energy, Bell Canada, Verizon, and SAP. He has also trained over 5,000 professionals worldwide in data, analytics, and AI.
Dr. Southekal has helped organizations unlock business value from data and analytics now supercharged with AI, for better growth, improved efficiency, and mitigated business risks. His work primarily focuses on designing scalable data pipelines and ecosystems, implementing robust data governance and security controls, and enabling advanced analytics, predictive modeling, and intelligent automation.
Dr. Southekal is the author of three books: Data for Business Performance, Analytics Best Practices, and Data Quality and writes regularly on data, analytics, and AI. His second book was ranked #1 analytics book of all time in May 2022 by BookAuthority. Dr. Southekal is also an adjunct professor of data and analytics at IE Business School (Madrid, Spain).