
Tunable Consistency in Cassandra NoSQL
Tunable consistency is one of the many points of differentiation between SQL and NoSQL databases. This article explains this important parameter and the tunable consistency options Cassandra provides.
- By William McKnight
- July 18, 2016
When it comes to data consistency, most relational databases give you one choice. RDBMSs deploy a highly consistent model in real-time, which ensures data accuracy to 100 percent of the users. John will not be looking at a record that is down-level from the one Mary is looking at.
However, in the fast-paced, real-time world, options are useful. An occasional inconsistent read can be more than offset by the ability to handle the veracity of the ingest. The options in this area are one reason many turn to NoSQL databases when it comes to modern operational deployments.
Cassandra, commercially supported by DataStax, is a NoSQL column store -- aka a Bigtable clone. It was created by none other than Facebook and donated to Apache. Cassandra has some noteworthy adopters, including Netflix, eBay, and Twitter. It features high-write performance and multi-data center support, and is optimized for solid-state storage.
Cassandra's use of "TABLE" takes some getting used to if you're coming from the relational world. It uses TABLE to mean a column family, which are groupings of columns that have fairly homogenous access patterns. Families occupy special parts of the cluster and are like metadata that tell the cluster which column goes into which column family when presented in an insert.
Although Cassandra offers parameters that are tuned at the column level, HBase, another column store, offers more, such as number of versions, duration to keep the value, compression, and in-memory options. The historical data options make that column store especially useful for time-series analysis.
Though all the major NoSQL offerings have tunable consistency options, Cassandra gives you the most, I believe. To understand the options, you must understand the replication factor for the nodes. Although the default is 3, for localized performance and failover you can deploy a higher number of replica nodes in the cluster.
You can set it up to release the record for read when all of the replicas have responded, which may take some time (milliseconds, but still time) or you can release the record when one of them has responded. That's high availability, and you can do so for almost all thinkable combinations of the replicas, such as two of them or a named set!
You can also group replicas into a quorum and utilize this concept in the determination. For example, you can specify that quorum A and B must respond, 2 quorums must respond, etc. The setup can be done at the cluster or data center level or on an individual I/O operation basis. Figure 1 shows 2 quorums, one per data center, for example. For strong consistency, quorum writes and reads or all are the most used. When eventual consistency is acceptable, it can be set to one.
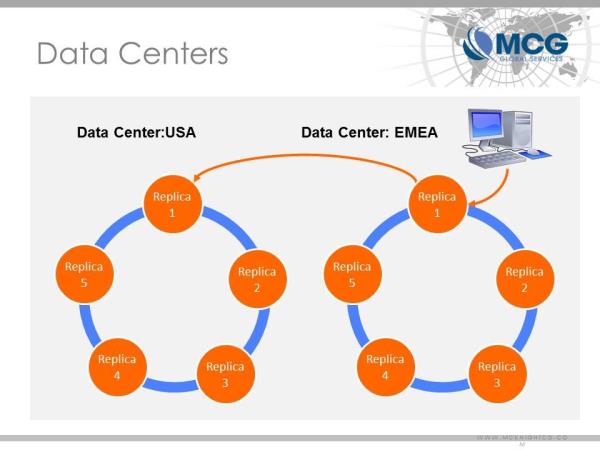
Figure 1
Tunable consistency is one of the many points of differentiation between SQL and NoSQL databases. Others include the schema-less nature of the data, use of in-RAM key-value stores, scale out, RESTful APIs, and -- inherent in the conversation of consistency -- the use of replicas potentially across data centers instead of RAID techniques.
Choose your NoSQL tunable consistency options carefully, but enjoy the options.
About the Author
McKnight Consulting Group is led by William McKnight. He serves as strategist, lead enterprise information architect, and program manager for sites worldwide utilizing the disciplines of data warehousing, master data management, business intelligence, and big data. Many of his clients have gone public with their success stories. McKnight has published hundreds of articles and white papers and given hundreds of international keynotes and public seminars. His teams’ implementations from both IT and consultant positions have won awards for best practices. William is a former IT VP of a Fortune 50 company and a former engineer of DB2 at IBM, and holds an MBA. He is author of the book Information Management: Strategies for Gaining a Competitive Advantage with Data.