
Fantasy Sports, Analytics, and the Enterprise
Growth of fantasy sport coincides with increasing interest in and understanding of data and analytics throughout business. As a game of numbers, it is no wonder that data scientists have taken an active interest in fantasy sport.
- By Brian J. Dooley
- September 7, 2016
When asked why he robbed banks, Willie Sutton famously replied, “Because that’s where the money is.” Today, everyone is looking at fantasy sport -- particularly fantasy football -- for the same reason: it’s where the action is. Growth of fantasy sport coincides with increasing interest in and understanding of data and algorithms throughout business. As a game of numbers, it is no wonder that data scientists have taken an active interest in fantasy sport. This is no longer a casual hobby.
Growth of Fantasy Sports
Fantasy sport participants act as owners of a team that they assemble from real-world players through a “draft.” The draft value of individual players is based on their real-world statistics. Each week, the players in fantasy rosters are accorded points based on their real-world performance. The fantasy team owner with the largest point total for that week wins the game. Money is often at stake, be it a small amount when playing against office co-workers or more significant amounts when playing against thousands of competitors online.
Although no prediction method is a sure thing, those with a casual interest are likely to lose out to increasingly sophisticated professionals. The amount spent is staggering. The Fantasy Sports Trade Association (FSTA) estimates that players spent $556 per year on fantasy sports. With participation in excess of 57 million players and growing, this could reach as high as $32 billion per year.
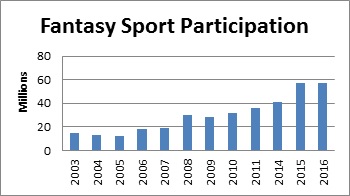
Source: Fantasy Sports Trade Association (FSTA)
The Data Is Real
Initially, fantasy sport statistics were handled by simple spreadsheets assembled by dedicated fans. In today's fantasy sports arena, expect to see massive amounts of data.
Data is freely distributed by the NFL in huge quantities, including the usual statistics on passes, touchdowns, and so forth. To this, we can now add all social interactions and social feeds, newspaper reviews, injury reports, and other potential influencing factors (such as weather).
At the same time, the ability to store and manipulate data has grown astronomically with the introduction of big data, deep learning, predictive analytics, and artificial intelligence. These new elements are being rushed into the fantasy lineup as quickly as possible.
The largest winner is reportedly a professional player, Saahil Sud, who has made over $3.5 million in the game. It is little surprise that Sud began his career in fantasy sports after leaving a position as a data scientist with a Cambridge, Massachusetts, company.
Big Firms Using as a Case Study
This new set of data has also attracted serious business analytics firms. For companies such as IBM and SAP, fantasy sport provides a way to showcase their sophisticated analytics products. As these products are applied, the likelihood of winning for a non-technologist is further diminished.
For example, IBM is using its Watson Cognitive Computing engine, the same solution that beat Jeopardy champions, to scour all relevant social media and statistics and deliver predictions for fantasy rosters with the highest likelihood of winning in a particular week.
IBM is partnering with IT fantasy football start-up Edge Up to provide its fantasy solution. This gives Watson publicity and provides a statistical advantage to players. Watson reads millions of Internet pages per second and gathers all relevant information, then applies a variety of APIs to digest the data and make predictions.
Another industry effort, this one from Intel and SAP, is a comparison tool that uses SAP's Hana in-memory database to provide access to advanced analytics for developing any fantasy roster.
Specialists and Specialized Products Appearing
In addition to general business analytics programs, innumerable niche products offering predictive and prescriptive analytics focusing on fantasy football have begun to appear. Many of these also provide a mobile emphasis to make them more accessible throughout the day and more attractive to the digital generation.
One example is a program called NumberFire, a service that claims its user’s teams perform 30 percent better using predictive analytics and crowdsourced knowledge to form team rosters.
Then there are the data scientists. Anyone who can build their own algorithm in R, use Hadoop, or integrate a variety of predictive mechanisms to create a unique and accurate result can potentially beat the odds. The specific techniques tend to be secret. The top ranked players generally have their own algorithms and programs, because use of programs -- as we know from the stock market -- can create uniformity that makes obtaining a performance advantage more difficult.
Undoubtedly, the Wild West environment will be challenged as the inequities of playing against sophisticated data programs become more evident to regulators. There are already several legal challenges in the offing, many of which challenge the gambling aspect of fantasy sites.
A Fertile Training Ground
On a positive note, fantasy sport is feeding a wider understanding of data and statistics with its huge and growing popularity. It is perhaps an ideal early experience for the budding data scientist. It is already having an effect within companies in making data and the consequences of data analysis more visible. The availability of potentially very large jackpots only increases interest.
Plus, of course, it is a real-world means of testing and improving big data, machine learning, and artificial intelligence platforms. To compete effectively, programs need to understand complex games and the intersection between game statistics and real-world outcomes.
There is an arms race afoot. Casual fans will migrate to less competitive platforms. The digital, statistical competition will likely grow both fiercer and more remunerative over time.
About the Author
Brian J. Dooley is an author, analyst, and journalist with more than 30 years' experience in analyzing and writing about trends in IT. He has written six books, numerous user manuals, hundreds of reports, and more than 1,000 magazine features. You can contact the author at [email protected].