Designing Parallelism into the Data Integration Models
How data integration developers can include parallelism into data integration models.
 In his new book Data Integration Blueprint and Modeling: Techniques for a Scalable and Sustainable Architecture, Anthony David Giordano examines how data integration and its application in business analytics has become tightly integrated into IT’s fabric. Combining data from different sources has become its own discipline, which Giordano examines -- including integration techniques and its methods of defining, designing, and developing a mature data integration environment that serves the business by moving ever-increasing data volumes within smaller and smaller timeframes.
In his new book Data Integration Blueprint and Modeling: Techniques for a Scalable and Sustainable Architecture, Anthony David Giordano examines how data integration and its application in business analytics has become tightly integrated into IT’s fabric. Combining data from different sources has become its own discipline, which Giordano examines -- including integration techniques and its methods of defining, designing, and developing a mature data integration environment that serves the business by moving ever-increasing data volumes within smaller and smaller timeframes.
In this excerpt, the author looks at how to best optimize the execution of data integration jobs through parallel processing.
Designing Parallelism into the Data Integration Models
The concept of parallel processing was first discussed in Chapter 7, “Data Integration Logical Design,” while discussing the partitioning of staged data. Parallel processing is the ability to break large data integration processes and/or data into smaller pieces that are run in parallel, thereby reducing overall runtime, as demonstrated in Figure 9.10.
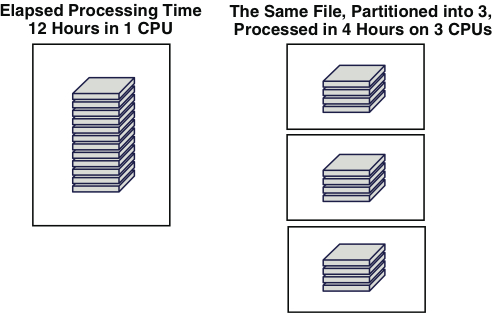
Figure 9.10 File-based parallel processing example
Types of Data Integration Parallel Processing
Although each of the data integration development software packages provides a different view on how to best implement parallel processing, there are two common approaches to parallelizing a data integration application: between data integration processes and within a data integration process, which are discussed in the following sections.
Between Data Integration Processes
The first approach is demonstrated in the following scenario, where there are three source systems that need to be extracted for downstream processing:
- A customer file system: 4 hours
- A commercial loan system: 5 hours
- A retail loan system: 3 hours
If these data integration processes are executed serially, the elapsed runtime would take 12 hours; however, if these processes are run in parallel, the elapsed time is only 5 hours, as displayed in Figure 9.11.
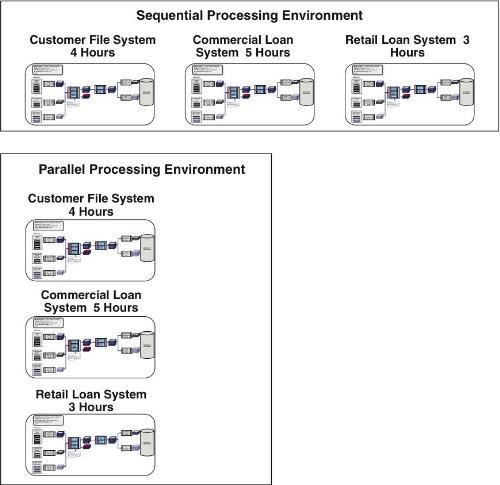
Figure 9.11 Sequential versus parallel process processing
Within a Data Integration Process
The second approach is to parallelize where possible within a data integration process. This normally revolves around parallel processing large data sets. Using the prior scenario, the longest running data integration process was the five-hour commercial loan system. Upon further analysis, it is found that the reason for the five-hour runtime is that the commercial loan file is 250GB. If the file can be partitioned into five segments and run in five separate partitions, the overall elapsed time for the commercial loan extract processing will be reduced to only one hour, as shown in Figure 9.12.
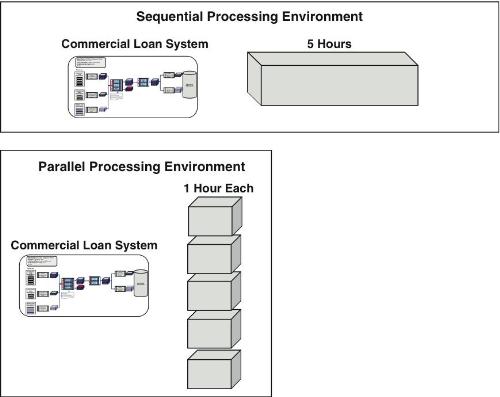
Figure 9.12 Sequential versus parallel file processing
Using these two approaches, a data integration architect should be able to review the entire data integration process flow for opportunities to optimize using parallel processing techniques. Figure 9.13 portrays the optimized extract processing along with the underlying physical environment needed for that processing.
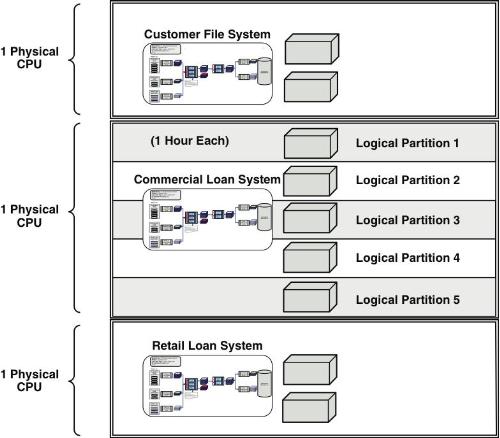
Figure 9.13 Optimized parallel file processing environment
It should be noted again that the technical implementation of each of these two approaches is highly dependent on the selected data integration technology package.
Other Parallel Processing Design Considerations
Parallelization design is also based on a combination of the following factors:
- The degree of parallelization must be a divisor or multiple of the number of available CPUs in the server.
- The number of potential logical partitions in the CPU must be accounted for in determining the logical constraint in terms of processing capability.
- The total data volumes and frequencies are another factor in the formula in terms of the size of the data compared with the size of the network pipe. Frequency refers to how often the data is being pushed through that network pipe.
Optimizing parallel performance includes the following:
- Selecting an intelligent key for partitioning of data
- Avoiding hot spot data access
Parallel processing, like other complex design techniques, is not a “one and done” task. Usually, a good first cut at a parallel design is required based on the parameters discussed previously. However, each environment with its data volumes, frequencies, and types of processing will be different and require its own set of metrics for parallel processing. This is the reason that after the initial test, there will be a number of performance tuning cycles based on test runs with test data in the development environment.
Parallel Processing Pitfalls
Setting up parallel processing must be a well-thought-through design process. Poorly designed parallel processing environments often perform less efficiently than a finely tuned sequential process.
When implementing parallel processing, the entire work flow must be considered to prevent creating bottlenecks along the path, as displayed in Figure 9.14.
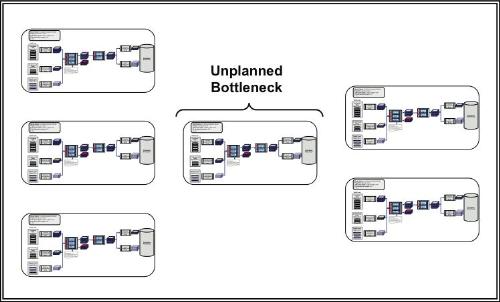
Figure 9.14 Examples of parallel processing issues
The final comment on parallel processing is that it should be apparent that in order to run data integration processes in parallel, it is critical to have the jobs as modular as possible, the common theme in the early part of this chapter.
Key Parallelism Design Task Steps
The two steps for designing parallelism into the data integration design are as follows:
1. Designing parallelism between data integration processes—In this step, the data integration job flow is reviewed for opportunities for running multiple jobs simultaneously and, where appropriate, configures those jobs for parallelism. Steps in this activity include the following:
a. Review the entire job flow.
b. Identify and configure those data integration processes for parallel processing.
c. Test (in the development environment) parallel process, tune any potential bottlenecks.
d. Configure job schedule and/or data integration software package parameters (package-specific).
2. Designing parallelism within a data integration process—This step parallelizes the processes within a data integration process. Steps in this activity include the following:
a. Review any subprocesses or components within a data integration process.
b. Review the input files for segmentation for parallel processing.
c. Plan test for running parallelization within a data integration process.
d. Configure job schedule and/or data integration software package parameters (package-specific).
Anthony Giordano is a partner in IBM's Business Analytics and Optimization Consulting Practice and currently leads the Enterprise Information Management Service Line that focuses on data modeling, data integration, master data management, and data governance. He has more than 20 years of experience in the Information Technology field with a focus in the areas of business intelligence, data warehousing, and Information Management. In his spare time, he has taught classes in data warehousing and project management at the undergraduate and graduate levels at several local colleges and universities.
This excerpt is from the book Data Integration Blueprint and Modeling: Techniques for a Scalable and Sustainable Architecture by Anthony David Giordano, published by Pearson/IBM Press, Dec. 2010, ISBN 0137084935, Copyright 2011 by International Business Machines Corp. Used by permission. For more information, please visit www.ibmpressbooks.com.