By Philip Russom, TDWI Research Director
[NOTE -- My new TDWI report about High-Performance Data Warehousing (HiPer DW) is finished and will be published in October. The report’s Webinar will broadcast on October 9, 2013. In the meantime, I’ll leak a few of the report’s findings in this blog series. Search Twitter for #HiPerDW to find other leaks. Enjoy!]
FIGURE 1.
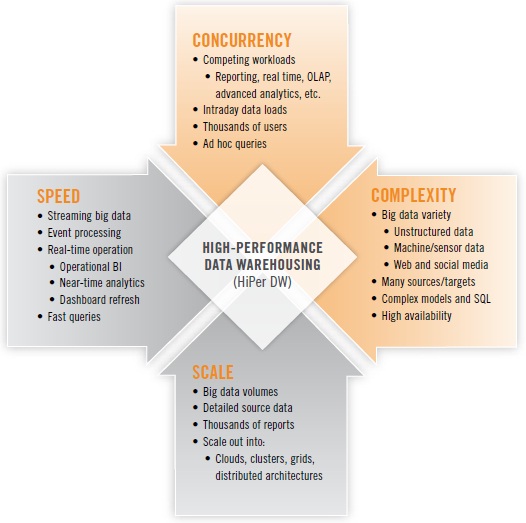
High-performance data warehousing (HiPer DW) is primarily about achieving speed and scale, while also coping with increasing complexity and concurrency. These are the four dimensions that define HiPer DW. Each dimension can be a goal unto itself; yet, the four are related. For example, scaling up may require speed, and complexity and concurrency tend to inhibit speed and scale. The four dimensions of HiPer DW are summarized in Figure 1 above.
Here follow a few examples of each:
SPEED. The now-common practice of operational BI usually involves fetching and presenting operational data (typically from ERP and CRM applications) in real time or close to it. Just as operational BI has pushed many organizations closer and closer to real-time operation, the emerging practice of operational analytics will do the same for a variety of analytic methods. Many analytic methods are based on SQL, making the speed of query response more urgent than ever. Other analytic methods are even more challenging for performance, due to iterative analytic operations for variable selection and reduction, binning, and neural net construction. Out on the leading edge, events and some forms of big data stream from Web servers, transactional systems, media feeds, robotics, and sensors; an increasing number of user organizations are now capturing and analyzing these streams, then making decisions or taking actions within minutes or hours.
SCALE. Upon hearing the term “scalability,” most of us immediately think of the burgeoning data volumes we’ve been experiencing since the 1990s. Data volumes have recently spiked in the phenomenon known as “big data,” which forces organizations to manage tens of terabytes – sometimes hundreds of terabytes, even petabytes – of detailed source data of varying types. But it’s not just data volumes and the databases that manage them. Scalability is also required of BI platforms that now support thousands of users, along with their thousands of reports that must be refreshed. Nor is it just a matter of scaling up; all kinds of platforms must scale out into ever larger grids, clusters, clouds, and other distributed architectures.
COMPLEXITY. Complexity has increased steadily with the addition of more data sources and targets, not to mention more tables, dimensions, and hierarchies within DWs. Today, complexity is accelerating, as more user organizations embrace the diversity of big data, with its unstructured data, semi-structured data, and machine data. As data’s diversity increases, so does the complexity of its management and processing. Some organizations are assuring high performance for some workloads (especially real time and advanced analytics) by deploying standalone systems for these; one of the trade-offs is that the resulting distributed DW architecture has complexity that makes it difficult to optimize the performance of processes that run across multiple platforms.
CONCURRENCY. As we scale up to more analytic applications and more BI users, an increasing number of them are concurrent—that is, using the BI/DW/DI and analytics technology stack simultaneously. In a similar trend, the average EDW now supports more database workloads – more often running concurrently – than ever before, driven up by the growth of real-time operation, event processing, advanced analytics, and multi-structured data.
Want more? Register for my HiPer DW Webinar, coming up Oct.9 noon ET.
Read other blogs in this series:
Defining HiPerDW
High Performance: The Secret of Success and Survival
0 comments
By Philip Russom, TDWI Research Director
[
NOTE -- My new TDWI report about High-Performance Data Warehousing (HiPer DW) is finished and will be published in October. The report’s Webinar will broadcast on October 9, 2013. In the meantime, I’ll leak a few of the report’s findings in this blog series. Search Twitter for #HiPerDW to find other leaks. Enjoy!]
Data used to be just data. Now there’s big data, real-time data, multi-structured data, analytic data, and machine data. Likewise, user communities have swollen into thousands of concurrent users, reports, dashboards, scorecards, and analyses. The rising popularity of advanced analytics has driven up the number of power users, with their titanic ad hoc queries and analytic workloads. And there are still brave new worlds to explore, such as social media and sensor data.
The aggressive growth of data and attendant disciplines has piled additional stresses on the performance of systems for business intelligence (BI), data warehousing (DW), data integration (DI), and analytics. The stress, in turn, threatens new business practices that need these systems to handle bigger and faster workloads. Just think about modern analytic practices that depend on real-time data, namely operational BI, streaming analytics, just-in-time inventory, facility monitoring, price optimization, fraud detection, and mobile asset management. Many of the latest practices apply business analytics to leveraging big data, which is a performance double whammy of heavy analytic workloads and extreme scalability.
The good news for BI, DW, DI, and analytic practices is that solutions for high-performance are available today. These solutions involve a mix of vendor tools or platforms and user designs or optimizations. For example, the vendor community has recently delivered new types of database management systems, analytic tools, platforms, and tool features that greatly assist performance. And users continue to develop their skills for high-performance architectures and designs, plus tactical tweaking and tuning. This report [to be published in October 2013] refers this eclectic mix of vendor products and user practices as high-performance data warehousing (HiPer DW).
In most user organizations, a DW and similar databases bear much of the burden of performance; yet, the quest for speed and scale also applies to every layer of the complex BI/DW/DI and analytics technology stack, as well as processes that unfold across multiple layers. Hence, in this report, the term high-performance data warehousing (HiPer DW) encompasses performance characteristics, issues, and enablers across the entire technology stack and associated practices.
HiPer DW Solutions combine Vendor Functionality with User Optimizations
Performance goals are challenging to achieve. Luckily, many of today’s challenges are addressed by technical advancements in vendor tools and platforms.
For example, there are now multiple high-performance platform architectures available for data warehouses, including massively parallel processing (MPP), grids, clusters, server virtualization, clouds, and SaaS. For real-time data, databases and data integration tools are now much better at handling streaming big data, service buses, SOA, Web services, data federation, virtualization, and event processing. 64-bit computing has fueled an explosion of in-memory databases and in-memory analytic processing in user solutions; flash memory and solid-state drives will soon fuel even more innovative practices. Other performance enhancements have recently come from multi-core CPUs, appliances, columnar storage, high-availability features, Hadoop, MapReduce, and in-database analytics. Later sections of this report will discuss in detail how these and other innovations assist with high performance.
Vendor tools and platforms are indispensible, but HiPer DW still requires a fair amount of optimization by technical users. The best optimizations are those that are designed into the BI and analytic deliverables that users produce, such as queries, reports, data models, analytic models, interfaces, and jobs for extract, transform, and load (ETL). As we’ll see later in this report, successful user organizations have pre-determined standards, styles sheets, architectures, and designs that foster high performance and other desirable characteristics. Vendor tools and user standards together solve a lot of performance problems up front, but there’s still a need for the tactical tweaking and of tuning of user-built BI deliverables and analytic applications. Hence, team members with skills in SQL tuning and model tweaking remain very valuable.
Want more? Register for my HiPer DW Webinar, coming up Oct.9 noon ET:
http://bit.ly/HiPerDWwebinar
Posted by Philip Russom, Ph.D.0 comments
By Philip Russom, TDWI Research Director
[NOTE: The following article was published in the TDWI Trip Report of May 2012.]
The Technology Survey that TDWI circulated at the recent World Conference in Chicago asked attendees to answer a few questions about analytic database management systems and how these fit into their overall data warehouse architecture. Here’s some background information about analytic databases, plus a sampling of attendees’ responses to the survey:
A “database management system” (DBMS) is a vendor-built enterprise-class software package designed to manage databases, whereas a “database” is a collection of data managed by a DBMS. Hence, an “analytic DBMS” (ADBMS) is a vendor-built DBMS designed specifically for managing data for analytics. ADBMSs are most often optimized for “Extreme SQL,” which involves complex queries that scan terabytes of data or routines that may include thousands of lines of SQL. SQL aside, some ADBMSs support other in-database analytic processing, such as MapReduce, no-SQL parsing methods, and a variety of user-defined functions for data mining, statistical analysis, natural language processing (NLP), and so on. Some vendors package or market their ADBMSs as data warehouse appliances, columnar DBMSs, analytic accelerators, in-memory DBMSs, and cloud/SaaS-based platforms.
Half of organizations surveyed (52%) have no ADBMS. There are good reasons why some organizations don’t feel the need for a specialized analytic DBMS. (See Figure 1.) Many organizations stick close to reporting, OLAP, and performance management, for which the average enterprise data warehouse (EDW) is more than capable. Others simply haven’t matured into the use of advanced analytics, for which most ADBMSs are designed. Still others have a powerful EDW platform that can handle all data warehouse workloads, including those for advanced analytics. Among the half of respondents that do have one or more ADBMSs, most have between one and five; multiple ADBMSs can result when multiple analytic methods are in use, due to diverse business requirements for analytics. Also, analytics tends to be departmental by nature, so ADBMSs are commonly funded via departmental budgets; and multiple departments investing in analytics leads to multiple ADBMSs.
FIGURE 1. Based on 75 respondents. Approximately how many standalone ADBMS platforms has your organization deployed? 52% = Zero
37% = One to five
8% = Six to ten
3% = More than ten
Half of organizations surveyed (46%) run analytic workloads on their EDW. The EDW as a single monolithic architecture is still quite common, despite the increasing diversity of data warehouse workloads for analytics, real-time, unstructured data, and detailed source data. (See Figure 2.) Even so, a third of respondents (34%) offload diverse workloads to standalone DBMSs (often an ADBMS), typically to get workload-specific optimization or to avoid degrading the performance of the EDW. If you compare Figures 1 and 2, you see that half of respondents don’t have an ADBMS (Figure 1) because they run analytic workloads on their EDW (Figure 2).
FIGURE 2. Based on 74 respondents. Which of the following best characterizes how data warehouse workloads are distributed in your organization? 46% = One monolithic EDW that supports all workloads in a single DBMS instance
34% = One EDW, plus multiple, standalone DBMSs for secondary workloads
20% = Other
Most respondents consider an ADBMS to be a useful complement to an EDW. Even some users who don’t have an ADBMS feel this way. (See Figure 3.) According to survey results, an ADBMS provides analytic and data management capabilities that complement an EDW (56%), enables the “analytic sandboxes” that many users need (57%), and optimizes more analytic workloads than the average EDW (58%).
FIGURE 3. Based on 219 responses from 72 respondents. What are the potential benefits of complementing an EDW with an ADBMS? (Select all that apply.)
58% = Optimized for more analytic workloads than our EDW
57% = Enables the “analytic sandboxes” that many users need
56% = Provides analytic and data mgt capabilities that complement our EDW
46% = Isolates ad hoc analytic work that might degrade EDW performance
33% = Manages multi-Tb raw source data for analytics better than EDW
29% = Handles real-time data feeds for analytics better than EDW
22% = Takes analytic processing to Big Data, instead of reverse
3% = Other
Posted by Philip Russom, Ph.D.0 comments
By Philip Russom, TDWI Research Director
High performance continues to intensify as a critical success factor for user implementations in data warehousing (DW), business intelligence (BI), data integration (DI), and analytics. Users are challenged by big data volumes, new and demanding analytic workloads, growing user communities, and business requirements for real-time operation. Vendor companies have responded with many new and improved products and functions for high performance—so many that it’s hard for users to grasp them all.
In other words, just about everything we do in DW, BI, DI, and analytics has some kind of high-performance requirement. Users want quick responses to their queries, analysts need to rescore analytic models as soon as possible, and some managers want to refresh their dashboards on demand. Then there’s scalability, as in the giant data volumes of big data, growing user communities, and the overnight refresh of thousands of reports and analyses. Other performance challenges come from the increasing adoption of advanced analytics, mixed workloads, streaming data, and real-time practices such as operational BI.
Across all these examples, you can see that high-performance data warehousing (HiPerDW) is all about achieving speed and scale, despite increasing complexity and concurrency. This applies to every layer of the complex BI/DW/DI technology stack, as well as processes that unfold across multiple layers.
Luckily, today’s high-performance challenges are being addressed by numerous technical advancements in vendor tools and platforms. For example, there are now multiple high-performance platform architectures available for your data warehouse, including MPP, grids, clusters, server virtualization, clouds, and SaaS. For real-time data, databases and data integration tools are now much better at handling streaming big data, service buses, SOA, Web services, data federation, virtualization, and event processing. 64-bit computing has fueled an explosion of in-memory databases and in-memory analytic processing in user solutions; flash memory and solid-state drives will soon fuel even more innovative practices. Other performance enhancements have recently come from multi-core CPUs, appliances, columnar storage, high-availability features, MapReduce, Hadoop, and in-database analytics.
My next Best Practices Report from TDWI will help users understand new business and technology requirements for high-performance data warehousing (HiPerDW), as well as the many options and solutions available to them. Obviously, performance doesn’t result solely from the data warehouse platform, so the report will also reach out to related platforms for analytics, BI, visualization, data integration, clouds, grids, appliances, data services, Hadoop, and so on. My upcoming TDWI report (to be published in October 2012) will provide tips and strategies for prioritizing your own adoption of high-performance features.
Please help me with the research for the HiPerDW report, by taking its survey, online at:
http://svy.mk/HiPerDW. And please forward this email to anyone you feel is appropriate, especially people who have experience implementing or optimizing the high performance of systems for BI/DW/DI and analytics. If you tweet about HiPerDW, please use the Twitter hash tag #HiPerDW. Thank you!
Posted by Philip Russom, Ph.D.0 comments
Blog by Philip Russom
Research Director for Data Management, TDWI
All kinds of people have recently weighed in with their definitions and descriptions of so-called “big data,” including journalists, industry analysts, consultants, users, and vendor representatives. Frankly, I’m concerned about the direction that most of the definitions are taking, and I’d like to propose a correction here.
Especially when you read the IT press, definitions stress data from Web, sensor, and social media sources, with the insinuation that all of it is collected and processed via streams in real time. Is anyone actually doing this? Yes, they are, but the types of companies out there on the leading edge of big data (and the advanced analytics that often go with it) are what we usually call “Internet companies.” Representatives from older Internet companies (Google, eBay, Amazon) and newer ones (Comshare, LinkedIn, LinkShare) have stood up at recent TDWI conferences and described their experiences with big data analytics; therefore I know it’s real and firmly established.
So, if Internet companies are successfully applying analytics to big data, what’s my beef? It is exactly this: a definition of big data biased toward best practices in Internet companies ignores big data best practices in more mainstream companies.
For example, I recently spoke with people at three different telcos – you know, telephone companies. For decades, they’ve been collecting big data about call detail records (CDRs), at the rate of millions (sometimes billions) of records a day. In some regions, national laws require them to collect this information and keep it in a condition that is easily shared with law enforcement agencies. But CDRs are not just for regulatory compliance. Telcos have a long history of success analyzing these vast datasets to achieve greater performance and reliability from their utility infrastructure, as well as for capacity planning and understanding their customers’ experiences.
Federal government agencies also have a long history of success with big data. For example, representatives from IRS Research recently spoke at a TDWI event, explaining how they were managing billions of records back in the 1990s, and have recently moved up to multiple trillions of records. (Did you catch that? I said trillions, not billions. And that’s just their analytic datasets!) More to the point, IRS data is almost exclusively structured and relational.
I could hold forth about this interminably. Instead, I’ve summarized my points in a table that contrasts a mainstream company’s big-data environment with that of an Internet-based one. My point is that there’s ample room for both traditional big data and for the new generation of big data that’s getting a lot of press at the moment. Eventually, many businesses (whether mainstream, Internet, or whatnot) will be an eclectic mix of the two.
|
Traditional Big Data |
New Generation Big Data |
|
Tens of Terabytes,
sometimes more |
Hundreds of Terabytes,
soon to be measured in Petabytes |
|
Mostly structured and relational data |
Mixture of structured, semi-structured, and unstructured data |
|
Data mostly from traditional enterprise applications: ERP, CRM, etc. |
Also from Web logs, clickstreams, sensors, e-commerce, mobile devices, social media |
|
Common in mid-to-large companies:
Mainstream today |
Common in Internet-based companies:
Will eventually go mainstream |
|
Real-time as in Operational BI |
Real-time as in Streaming Data |
I’m sorry that I’m foisting yet another definition of big data on you. Heaven knows, we have enough of them. But I feel we need a less Internet-biased definition in preference of one that’s broad enough to encompass big-data best practices in mainstream companies, as well. For one thing, let’s give credit where credit is due; and a lot of mainstream companies are successful with a more traditional definition of big data. For another, we run the risk of alienating people in mainstream companies, which could impair the mainstream adoption of big-data best practices. That, in turn, would stymie the cause of leveraging big data (no matter how you define it) for greater business leverage. And that would be a pity.
So, what do you think? Let me know!
===============================
Some of the material of this blog came from my recent Webinar: “Big Data and Your Data Warehouse.” You can replay it from TDWI’s Webinar Archive.
Want to learn more about Big Data Analytics? Attend the TDWI Forum on Big Data Analytics, coming in Orlando November 12-13, 2012.
Posted by Philip Russom, Ph.D.0 comments
Blog by Philip Russom
Research Director for Data Management, TDWI
To raise an awareness of what the Next Generation of Master Data Management (MDM) is all about, I recently issued a series of 35 tweets via Twitter, over a two-week period. The tweets also helped promote a TDWI Webinar on Next Generation MDM. Most of these tweets triggered responses to me or retweets. So I seem to have reached the business intelligence (BI), data warehouse (DW), and data management (DM) audience I was looking for – or at least touched a nerve!
To help you better understand Next Generation MDM and why you should care about it, I’d like to share these tweets with you. I think you’ll find them interesting because they provide an overview of Next Generation MDM in a form that’s compact, yet amazingly comprehensive.
Every tweet I wrote was a short sound bite or stat bite drawn from TDWI’s recent report on Next Generation MDM, which I researched and wrote. Many of the tweets focus on a statistic cited in the report, while other tweets are definitions stated in the report.
I left in the arcane acronyms, abbreviations, and incomplete sentences typical of tweets, because I think that all of you already know them or can figure them out. Even so, I deleted a few tiny URLs, hashtags, and repetitive phrases. I issued the tweets in groups, on related topics; so I’ve added some headings to this blog to show that organization. Otherwise, these are raw tweets.
Defining the Generations of MDM
1. #MDM is inherently a multigenerational discipline w/many life cycle stages. Learn its generations in #TDWI Webinar
2. User maturation, new biz reqs, & vendor advances drive #MDM programs into next generation. Learn more in #TDWI Webinar
3. Most #MDM generations incrementally add more data domains, dep’ts, data mgt tools, operational apps.
4. More dramatic #MDM generations consolidate redundant solutions, redesign architecture, replace platform.
Why Care About NG MDM?
5. Why care about NexGen #MDM? Because biz needs consistent data for sharing, BI, compliance, 360views.
6. Why care about NexGen #MDM? Most orgs have 1st-gen, homegrown solutions needing update or replacement.
The State of NG MDM
7. #TDWI SURVEY SEZ: #MDM adoption is good. 61% of surveyed orgs have deployed solution. Another 29% plan to soon.
8. #TDWI SURVEY SEZ: #MDM integration is not so good. 44% of solutions deployed are silos per dept, app, domain.
9. #TDWI SURVEY SEZ: Top, primary reasons for #MDM: 360-degree views (21%) & sharing data across enterprise (19%).
10. #TDWI SURVEY SEZ: Top, secondary reasons for #MDM: Data-based decisions (15%) & customer intelligence (13%).
11. #TDWI SURVEY SEZ: Other reasons for #MDM: operational excellence, reduce cost, audits, compliance, reduce risk.
12. #TDWI SURVEY SEZ: Top, primary #MDM challenges are lack of: exec sponsor, data gov, cross-function collab, biz driver.
13. #TDWI SURVEY SEZ: Other challenges to #MDM: growing reference data, coord w/other data mgt teams, poor data quality.
MDM’s Business Entities and Data Domains
14. #TDWI SURVEY SEZ: “Customer” is biz entity most often defined via #MDM (77%). But I bet you knew that already!
15. #TDWI SURVEY SEZ: Other #MDM entities (in survey order) are product, partner, location, employee, financial.
16. #TDWI SURVEY SEZ: Surveyed organizations have an average of 5 definitions for customer and 5 for product. #MDM
17. #TDWI TAKE: Multi-data-domain support is a key metric for #MDM maturity. Single-data-domain is a myopic silo.
18. #TDWI SURVEY SEZ: 37% practice multi-data-domain #MDM today, proving it can succeed in a wide range of orgs.
19. #TDWI SURVEY SEZ: Multi-data-domain maturity is good. Only 24% rely mostly on single-data-domain #MDM.
20. #TDWI SURVEY SEZ: A third of survey respondents (35%) have a mix of single- and multi-domain #MDM solutions.
Best Practices of Next Generation MDM
21. #TDWI TAKE: Unidirectional #MDM improves reference data but won’t share. Not a hub unless ref data flows in/out
22. #TDWI SURVEY SEZ: #MDM solutions today r totally (26%) or partially (19%) homegrown. Learn more in Webinar http://bit.ly/NG-MDM #GartnerMDM
23. #TDWI SURVEY SEZ: Users would prefer #MDM functions from suite of data mgt tools (32%) or dedicated #MDM app/tool (47%)
24. #TDWI Survey: 46% claim to be using biz process mgt (BPM) now w/#MDM solutions. 32% said integrating MDM w/BPM was challenging.
25. #TDWI SURVEY SEZ: Half of surveyed organizations (46%) have no plans to replace #MDM platform.
26. #TDWI SURVEY SEZ: Other half (50%) is planning a replacement to achieve generational change. Learn more in Webinar http://bit.ly/NG-MDM
27. Why rip/replace #MDM? For more/better tools, functions, arch, gov, domains, enterprise scope.
28. Need #MDM for #Analytics? Depends on #Analytics type. OLAP, complex SQL: Oh, yes. Data/text mining, NoSQL, NLP: No way.
Quantifying the Generational Change of MDM Features
29. #TDWI SURVEY SEZ: Expect hi growth (27% to 36%) in #MDM options for real-time, collab, ref data sync, tool use.
30. #TDWI SURVEY SEZ: Good growth (5% to 22%) coming for #MDM workflow, analytics, federation, repos, event proc.
31. #TDWI SURVEY SEZ: Some #MDM options will be flat due to saturation (gov, quality) or outdated (batch, homegrown).
Top 10 Priorities for Next Generation MDM
32. Top 10 Priorities for NG #MDM (Pt.1) 1-Multi-data-domain. 2-Multi-dept/app. 3-Bidirectional. 4-Real-time. #TDWI
33. Top 10 Priorities for NG #MDM (Pt.2) 5-Consolidate multi MDM solutions. 6-Coord w/other disciplines. #TDWI
34. Top 10 Priorities for NG #MDM (Pt.3) 7-Richer modeling. 8-Beyond enterprise data. 9-Workflow/process mgt. #TDWI
35. Top 10 Priorities for NG #MDM (Pt.4) 10-Retire early gen homegrown & build NexGen on vendor tool/app. #TDWI
FOR FURTHER STUDY:
For a more detailed discussion of Next Generation MDM – in a traditional publication! – see the TDWI Best Practices Report, titled “Next Generation Master Data Management,” which is available in a PDF file via a free download.
You can also register for and replay my TDWI Webinar, where I present the findings of the Next Generation MDM report.
Philip Russom is the research director for data management at TDWI. You can reach him at [email protected] or follow him as @prussom on Twitter.
Posted by Philip Russom, Ph.D.0 comments