By Philip Russom, TDWI Research Director for Data Management
This week, we at TDWI produced our fifth annual Solution Summit on Master Data, Quality, and Governance, this time on Coronado Island off San Diego. I moderated the conference, along with David Loshin (president of Knowledge Integrity). We lined up a host of great user speakers and vendor panelists. The audience asked dozens of insightful questions, and the event included hundreds of one-to-on meetings among attendees, speakers, and vendor sponsors. The aggregated result was a massive knowledge transfer that illustrates how master data management (MDM), data quality (DQ), and data governance (DG) are more vibrant than ever.
To give you a sense of the range of data management topics addressed at the summit, here’s an overview of some of the presentations heard at the TDWI Solution Summit for Master Data, Quality, and Governance:
Luuk van den Berg (Data Governance Lead, Cisco Systems) talked about MDM and DG tools and processes that are unique to Cisco, especially their method of “watermarking reports,” which enables them to certify the quality, source, and content of data, as well as reports that contain certified data.
Joe Royer (Enterprise Architect, Principal Financial Group) discussed how Principal found successful starting points for their DG program. Joe also discussed strategies for sustaining DG, different DG models, and how DG can accelerate MDM and DQ programs.
Rich Murnane (Director of Enterprise Data Operations, iJET International) described how iJET collects billions of data points annually to provide operational risk management solutions to their clients. To that end, iJET applies numerous best practices in MDM, DQ, DG, stewardship, and data integration.
Hope Johansen (Master Data Project Manager, Schlumberger). Because of mergers, Schlumberger ended up with many far-flung facilities, plus related physical assets and locations. Hope explained how her team applied MDM techniques to data about facilities (not the usual customer and product data domains!) to uniquely identify facilities and similar assets, so they could be optimized by the business.
Bruce Harris (Vice President, Chief Risk and Strategy Officer, Volkswagen Credit). VW Credit has the long-term goal of becoming a “Strategy Focused Organization”. Bruce explained how DG supports that business goal. As an experienced management executive who has long depended on data for operational excellence, Bruce recounted many actionable tips for aligning data management work with stated business goals.
Kenny Sargent (Technical Lead, Enterprise Data Products, Compassion International) described his method for “Validation-Driven Development.” In this iterative agile method, a developer gets an early prototype in front of business users ASAP to get feedback and to make course corrections as early as possible. The focus is on data, to validate early on that the right data is being used correctly and that the data meets business requirements.
Besides the excellent user speakers described above, the summit also had break out sessions with speeches by representatives from vendor firms that sponsored the summit. Sponsoring firms included: IBM, SAS, BackOffice Associates, Collibra, Compact Solutions, DataMentors, Information Builders, and WhereScape.
To learn more about the event, visit the Web site for the
2013 TDWI Solution Summit on Master Data, Quality and Governance.
Posted by Philip Russom, Ph.D.0 comments
By Philip Russom, TDWI Research Director
Think about everything you know about data management, including its constituent disciplines for integration, quality, master data, metadata, data modeling, event processing, data warehousing, governance, administration, capacity planning, hand coding, and so on. Now, write down everything you know on a series of index cards that are about the same size as playing cards. Next, do some reading and studying to determine the new things you need to learn about managing so-called “big data,” and write those on more index cards. Finally, shuffle the index cards and deal them into several large hands, as you would do with playing cards.
That’s pretty much what will happen to data management in the next several years, under the influence of big data and related phenomena like advanced analytics, real-time operation, and multi-structured data. You won’t stop doing the old tried-and-true practices, and the new stuff won’t replace the old best practices. You’ll play every card in the newly expanded deck, but in hands, suites, and straights that are new to you, as well as at unprecedented levels of scale, speed, complexity, and concurrency. And every hand dealt from the deck will require tweaking and tuning to make it perform at the new level.
The result is
Big Data Management, the next generation of data management best practices and technologies, driven by new business and technical requirements for big data and related practices for analytics, real time, and diverse data types. Big Data Management is an amalgam of old and new techniques, best practices, teams, data types, and home-grown or vendor-built functionality. One assumption is that all these are being expanded and realigned so businesses can fully leverage big data, not merely manage it. Another assumption is that big data will eventually assimilate into enterprise data.
To help user organizations understand and embrace the next generation of data management, TDWI has commissioned a report titled: “
Managing Big Data.” I will research and write this 36-page report. It will catalog new user practices and technical functions in Big Data Management, as well as explain how the older ones need to be adjusted to serve the new world of big data. This report will bring readers up-to-date, so they can make intelligent decisions about which tools, techniques, and team structures to apply to their next-generation Big Data Management solutions. TDWI will publish the report “Managing Big Data” on or about October 1, 2013.
========================================================
Got #BigData? How do you manage it? Share your experiences and opinions by taking the
TDWI survey for the upcoming report on “Managing Big Data,” If you complete the survey, TDWI will send you an email explaining how to download a free copy of the report in October.
Thanks! I really appreciate you taking the survey.
Posted by Philip Russom, Ph.D.0 comments
Blog by Philip Russom
Research Director for Data Management, TDWI
To help you better understand how Hadoop can be integrated into business intelligence (BE) and data warehousing (DW) and why you should care, I’d like to share with you the series of 27 tweets I recently issued on the topic. I think you’ll find the tweets interesting, because they provide an overview of these issues and best practices in a form that’s compact, yet amazingly comprehensive.
Every tweet I wrote was a short sound bite or stat bite drawn from my recent TDWI report “Integrating Hadoop in Business Intelligence and Data Warehousing.” Many of the tweets focus on a statistic cited in the report, while other tweets are definitions stated in the report.
I left in the arcane acronyms, abbreviations, and incomplete sentences typical of tweets, because I think that all of you already know them or can figure them out. Even so, I deleted a few tiny URLs, hashtags, and repetitive phrases. I issued the tweets in groups, on related topics; so I’ve added some headings to this blog to show that organization. Otherwise, these are raw tweets.
Status of Users’ Efforts at Integrating Hadoop into BI/DW
1. #TDWI SURVEY SEZ: Shocking 26% don’t know what #Hadoop is. Ignorance of #Hadoop too common in BI & IT.
2. #TDWI SURVEY SEZ: Mere 18% have had experience w/#HDFS & #Hadoop. Only 2/3rds of 18% have deployed HDFS.
3. Use of #Hadoop Distributed File System (#HDFS) will go from scarce to ensconced in 3 yrs.
4. #TDWI SURVEY SEZ: Only 10% have deployed #HDFS today, yet another 63% expect to within 3 yrs.
5. #TDWI SURVEY SEZ: A mere 27% say their organization will never deploy #HDFS.
Hadoop Technologies Used Today in BI/DW
6. #TDWI SURVEY SEZ: #MapReduce (69%) & #HDFS (67%) are the most used #Hadoop techs today.
7. #TDWI SURVEY SEZ: #Hive (60%) & #HBase (54%) are the #Hadoop techs most commonly used w/#HDFS.
8. #TDWI SURVEY SEZ: #Hadoop technologies used least today are: Chukwa, Ambari, Oozie, Hue, Flume.
9. #TDWI SURVEY SEZ: #Hadoop techs etc poised for adoption: Mahout, R, Zookeeper, HCatalog, Oozie.
What Hadoop will and won’t do for BI/DW
10. #TDWI SURVEY: 88% say #Hadoop for BI/DW (#Hadoop4BIDW) is opportunity cuz enables new app types.
11. #TDWI SURVEY: Can #Hadoop Distributed File System (#HDFS) replace #EDW? Mere 4% said yes.
12. #TDWI SURVEY: Can #Hadoop Distributed File System (#HDFS) augment #EDW? Mere 3% said no.
13. #TDWI SURVEY: Can #Hadoop Distributed File System (#HDFS) expand your #Analytics? Mere 1% said no.
Hadoop Use Case with BI/DW
14. #TDWI SURVEY: 78% of respondents say #HDFS complements #EDW. That’s leading use case in survey.
15. #TDWI SURVEY: Other #HDFS use cases: archive (52%), data stage (41%), sandbox (41%), content mgt (35%).
Hadoop Benefits and Barriers
16. #TDWI SURVEY: Best #Hadoop4BIDW benefits: #BigData source, #analytics, data explore, info discover.
17. #TDWI SURVEY: Worst #Hadoop4BIDW barriers: lacking skill, biz case, sponsor, cost, lousy #Hadoop tools.
Best Practices among Users who’ve deployed Hadoop
18. #TDWI SURVEY: Why adopt #Hadoop4BIDW? Scale, augment DW, new #analytics, low cost, diverse data types.
19. #TDWI SURVEY: Job titles of #Hadoop4BIDW workers: data developer, architect, scientist, analyst.
20. Organizations surveyed with #Hadoop in production average 12 clusters; median is 2.
21. Orgs surveyed with #Hadoop in production average 45 nodes per cluster; median is 12.
22. Orgs surveyed with #Hadoop in production manage a few TBs today but expect ~.5PB within 3yrs.
23. Orgs surveyed with #Hadoop in production mostly load it via batch every 24 hrs.
24. #TDWI SURVEY: Worst #Hadoop functions: security, admin tools, namenode, data quality, loading, dev tools.
BI/DW Tools etc. Integrated Today & Tomorrow with Hadoop
25. #TDWI SURVEY: BI/DW tools commonly integrated with #Hadoop: #analytics, DWs, reporting, webservers, DI.
26. Other BI/DW tools integrated with #Hadoop: analytic DBMSs, #DataViz, OpApps, marts, DQ, MDM.
27. #TDWI SURVEY: Machinery (13%) & sensors (8%) are seldom integrated w/#Hadoop today, but coming.
Want to learn more about big data and its management?
Take courses at the TDWI World Conference in Chicago, May 5-10, 2013. Enroll online.
For a more detailed discussion – in a traditional publication! – get the TDWI Best Practices Report, titled “Integrating Hadoop into Business Intelligence and Data Warehousing,” which is available in a PDF file via a free download.
You can also register online for and replay my TDWI Webinar, where I present the findings of the TDWI report “Integrating Hadoop into BI/DW.”
Philip Russom is the research director for data management at TDWI. You can reach him at [email protected] or follow him as @prussom on Twitter.
Posted by Philip Russom, Ph.D.0 comments
By Philip Russom, TDWI Research Director
[
NOTE -- My new TDWI report “Integrating Hadoop into Business Intelligence (BI) and Data Warehousing (DW)” (Hadoop4BIDW) is finished and will be published in early April. I will broadcast the report’s Webinar on April 9, 2013 at noon ET. In the meantime, I’ll leak a few of the report’s findings in this blog series. Search Twitter for #Hadoop, #TDWI, and #Hadoop4BIDW to find other leaks. Enjoy!]
Hadoop is still rather young, so it needs a number of upgrades to make it more palatable to BI professionals and mainstream organizations in general. Luckily, a number of substantial improvements are coming.
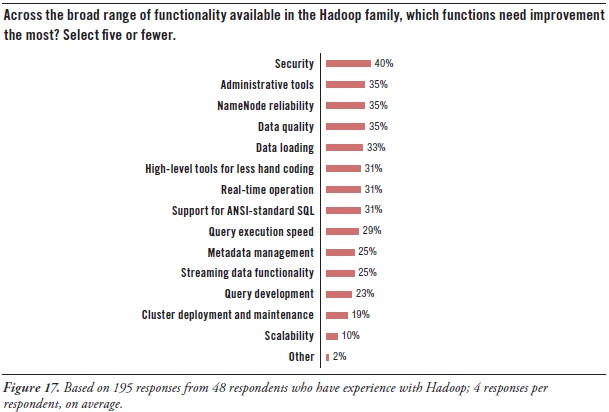
Hadoop users’ greatest needs for advancement concern security, tools, and high availability:
Security. Hadoop today includes a number of security features, such as file-permission checks and access control for job queues. But the preferred function seems to be Service Level Authorization, which is the initial authorization mechanism that ensures clients connecting to a particular Hadoop service have the necessary, pre-configured permissions. Furthermore, add-on products that provide encryption or other security measures are available for Hadoop from a few third-party vendors. Even so, there’s a need for more granular security at the table level in HBase, Hive, and HCatalog.
Administration. As noted earlier, much of Hadoop’s current evolution is at the tool level, not so much in the HDFS platform. After security, users’ most pressing need is for better administrative tools (35% in Figure 17 above), especially for cluster deployment and maintenance (19%). The good news is that a few vendors offer tools for Hadoop administration, and a major upgrade of open-source Ambari is coming soon.
High availability. HDFS has a good reputation for reliability, due to the redundancy and failover mechanisms of the cluster it sits atop. However, HDFS is currently not a high availability (HA) system, because its architecture centers around NameNode. It’s the directory tree of all files in the file system, and it tracks where file data is kept across the cluster. The problem is that NameNode is a single point of failure. While the loss of any other node (intermittently or permanently) does not result in data loss, the loss of NameNode brings the cluster down. The permanent loss of NameNode data would render the cluster's HDFS inoperable, even after restarting NameNode.
A BackupNameNode is planned to provide HA for NameNode, but Apache needs more and better contributions from the open source community before it’s operational. There’s also Hadoop SecondaryNameNode (which provides a partial, latent backup of NameNode) and third-party patches, but these fall short of true HA. In the meantime, Hadoop users protect themselves by putting NameNode on especially robust hardware and by regularly backing up NameNode’s directory tree and other metadata.
Latency issues. A number of respondents are hoping for improvements that overcome the data latency of batch-oriented Hadoop. They want Hadoop to support real-time operation (31%), fast query execution (29%), and streaming data (25%). These will be addressed soon by improvements to Hadoop products like MapReduce, Hive, and HBase, plus the new Impala query engine.
Development tools. Again, many users needs better tools for Hadoop, including development tools for metadata management (25%), query design (23%), and ANSI-standard SQL (31%), plus a higher-level approach that results in less hand coding (31%).
Want to learn more about big data and its management? Take courses at the TDWI World Conference in Chicago, May 5-10, 2013.
Enroll online.
Posted by Philip Russom, Ph.D.0 comments

By Philip Russom, TDWI Research Director
[
NOTE -- My new TDWI report “Integrating Hadoop into Business Intelligence (BI) and Data Warehousing (DW)” (Hadoop4BIDW) is finished and will be published in early April. I will broadcast the report’s Webinar on April 9, 2013 at noon ET. In the meantime, I’ll leak a few of the report’s findings in this blog series. Search Twitter for #Hadoop4BIDW, #Hadoop, and #TDWI to find other leaks. Enjoy!]
Number of HDFS clusters per enterprise. One way to measure the adoption of HDFS is to count the number of HDFS clusters per enterprise. Since far more people have downloaded HDFS and other Hadoop products than have actually put them to enterprise use, it’s best to only count those clusters that are in production use. The vast majority of survey respondents (and, by extension, most user organizations) do not have HDFS clusters in production. So, this report identified 32 respondents who do, and asked them about their clusters. (See Figure 13 above.)
When asked how many HDFS clusters are in production, 32 survey respondents replied in the range one to one hundred. Most responses were single digit integers, which drove the average number of HDFS clusters down to 12 and the median down to 2. Parsing users’ responses reveals that over half of respondents have only one or two clusters in production enterprise-wide at the moment, although one fifth have 50 or more.
Note that ownership of Hadoop products can vary, as discussed earlier, thereby affecting the number of HDFS clusters. Sometimes central IT provides a single, very large HDFS cluster for shared use by departments across an enterprise. And sometimes departments and development teams have their own.
Number of nodes per HDFS cluster. We can also measure HDFS cluster maturity by counting the number of nodes in the average cluster. Again, the most meaningful count comes from clusters that are in production. (See Figure 14 above.)
When asked how many nodes are in the HDFS cluster most often used by the survey respondent, respondents replied in the range one to six hundred and twenty, where one third of responses were single digit. That comes to 45 nodes per production cluster on average, with the median at 12. Half of the HDFS clusters in production surveyed here have 12 or fewer nodes, although one quarter have 50 or more.
To add a few more data points to this discussion, people who work in large Internet firms have presented at TDWI conferences, talking about HDFS clusters with approximately one thousand nodes. However, speakers discussing fairly mature HDFS usage specifically in data warehousing usually have clusters in the fifty to one-hundred node range. Proof-of-concept clusters observed by TDWI typically have four to eight nodes, whereas development clusters may have but one or two.
Want to learn more about big data and its management? Take courses at the TDWI World Conference in Chicago, May 5-10, 2013.
Enroll online.
Posted by Philip Russom, Ph.D.0 comments
By Philip Russom, TDWI Research Director
[
NOTE -- My new TDWI report “Integrating Hadoop into Business Intelligence (BI) and Data Warehousing (DW)” (Hadoop4BIDW) is finished and will be published in early April. I will broadcast the report’s Webinar on April 9, 2013. In the meantime, I’ll leak a few of the report’s findings in this blog series. Search Twitter for #Hadoop4BIDW, #Hadoop, and #TDWI to find other leaks. Enjoy!]
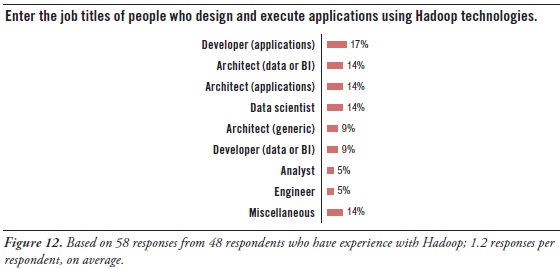
One way to get a sense of what kinds of technical specialists are working with HDFS and other Hadoop tools is to look at their job titles. So, this report’s survey asked a subset of respondents to enter the job titles of Hadoop workers. (See Figure 12 above.) Many users are concerned about acquiring the right people with the right skills for Hadoop, and this list of job titles can assist in that area.
Hadoop workers are typically architects, developers, data scientists, and analysts:
Architect. It’s interesting that the word architect appeared in more job titles than any other word, followed closely by the word developer. Among these, two titles stand out – data architect and application architect – plus miscellaneous titles like system architect and IT architect. Most architects (regardless of type) guide designs, set standards, and manage developers. So architects are most likely providing a management and/or governance function for Hadoop, since Hadoop has an impact on data, application, and system architectures.
Developer. Similar to the word architect, many job titles contained the word developer. Again, there’s a distinction between application developers and data (or BI) developers. Application developers may be there to satisfy Hadoop’s need for hand-coded solutions, regardless of the type of solution. And, as noted, some application groups have their own Hadoop cluster. The data and BI developers obviously bring their analytic expertise to Hadoop-based solutions.
Data Scientist. This job title has slowly gained popularity in recent years, and seems to be replacing the older position of business analyst. Another way to look at it is that some business analysts are proactively evolving into data scientists, because that’s what their organizations need from them. When done right, the data scientist’s job involves many skills, and most of those are quite challenging. For example, like a business analyst, the data scientist is also a hybrid worker who needs knowledge of both business and data (that is, data’s meaning, as well as its management). But the data scientist must be more technical than the average business analyst, doing far more hands-on work writing code, designing analytic models, creating ETL logic, modeling databases, writing very complex SQL, and so on. Note that these skills are typically required for high-quality big data analytics in a Hadoop environment, and the position of the data scientist originated for precisely that. Even so, TDWI sees the number of data scientists increasing across a wide range of organizations and industries, because they’re needed as analytic usage gets deeper and more sophisticated and as data sources and types diversify.
Analyst. Business analyst and data analyst job titles barely registered in the survey. Perhaps that’s because most business analysts rely heavily on SQL, relational databases, and other technologies for structured data, which are currently not well represented in Hadoop functionally. As noted, some analysts are becoming data scientists, as they evolve to satisfy new business requirements.
Miscellaneous. The remaining job titles are a mixed bag, ranging from engineers to marketers. This reminds us that big data analytics – and therefore Hadoop, too – is undergoing a democratization that makes it accessible to an ever-broadening range of end users who depend on data to do their jobs well.
Want more? Register for my Hadoop4BIDW Webinar, coming up April 9, 2013 at noon ET:
http://bit.ly/Hadoop13
Posted by Philip Russom, Ph.D.0 comments