
Timeline of an Agile Data Environment: A Detailed View (Part 3 of 3)
In the last part of our series, we examine the detailed activities of an analytics team before, during, and after a sprint. You can compare your team’s work flow to the activities list in this article to see opportunities to become even more agile.
- By Stan Pugsley
- March 6, 2019
In Part 1 of this series, we explored the benefits of using agile techniques, and some of the cultural changes, processes, and tools needed to make it work. In Part 2 we looked at the big picture of how to adapt agile practices to your team. Now let’s take a detailed look at how this would affect the day-to-day activities.
In the following timeline and discussion, we will assume that a project is going to last at least several months, involve four or more data engineers and analysts, and have a full-time dedicated product owner (see Part 2 for a discussion on how to adapt these processes to organizations of different sizes). For a project of that size, the flow of tasks could follow a timeline similar to this:
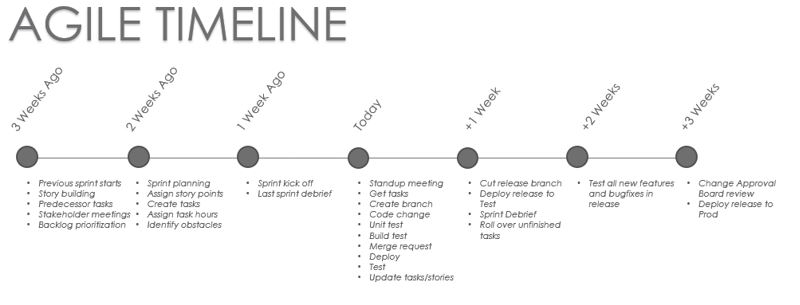
Preparing for a Sprint
Product management should always be working at least two weeks ahead of development teams. The product manager is actively gathering requirements and encapsulating them in user stories, which are then placed in the backlog in order of priority. Stories that need technical input and exploration should be assigned to a developer as an investigation story/task in the sprint ahead of when they are expected to be implemented. If business requirements are fuzzy or the implementation isn’t clear, a prototype story can be created in a previous sprint to allow another iteration. Business sponsors need to be actively involved in defining and prioritizing the stories.
Data and analytics projects present some unique challenges for building stories and sprints. In every project there are data sources, some of which provide easy access to data while others may be blocked by legal, technical, or organizational obstacles. Master data management requires a big picture view of how all of the data fits together and is difficult to start quickly and break into small pieces, and some projects get buried under a mountain of legacy reports that all need to be analyzed and replaced.
These factors tend to force teams into thinking they need to do months of analysis and fall into a waterfall approach, but it is critical to find small pieces that can be completed in one sprint, get started as soon as possible, and show tangible results in each sprint. Although the product manager and data architect continue to perform analysis and design as part of each sprint, don’t wait for a final design or plan. Get your developers started right away on the things they can do to show value and keep business stakeholders engaged.
For data warehouse projects, a bus matrix can be used to show how stories fit together. In general, each dimension and fact table should have its own story. Data modeling should be done as part of design stories at least one sprint ahead of their implementation. Data sourcing from files, databases, and APIs should be done a sprint ahead of data-model-building tasks. Dimensions should be listed as predecessors of fact tables. Notify DBAs or other admins well in advance if you will need resources or permissions.
For reporting projects, the overall look and feel and navigation structure should be done as part of a design story a sprint ahead of report implementation. Each report or dashboard should have its own story. Stories should describe the business need and avoid, if possible, prescribing the exact implementation. Get a style guide from marketing so that your look and feel is on brand. If you don’t have a style guide, create a story to prototype a template report that has the right look and feel for future use.
For data science projects, large models should be defined in an epic story, which can then be broken down into smaller stories for implementation. Prior to diving into data, a sprint should be devoted to designing a layout for how data will be organized, and how the project files will be organized. Messy data and messy files will lead to headaches later when it is difficult to define a set of files for a release.
Kicking Off a Sprint
The sprint should consist of the top stories from your backlog. Each story should have specific definition of the business problem, tasks for any data modeling or design work, tasks for development and tasks for unit testing. Hours should be estimated for every task. If you have poorly defined stories or tasks, don’t start on them! The key is only to accept stories that you know you can complete in one sprint.
A well-run agile environment and team would eliminate “shoulder tapping” or instant messaging from business stakeholders with new requests. Any new requests from stakeholders go into the backlog for future sprints. Urgent business needs would only break a sprint if approved by management, so a great way to start a sprint is to get verbal or written confirmation from each of the business and IT participants that they are clear on the scope of the sprint and agree to defer any changes until the next sprint.
Daily Activities During a Sprint
Every day should start with a standup meeting. Ideally, business stakeholders are involved with these meetings. Before standup you have looked at the task board, updated the status on the tasks you intend to work on that day, and updated any tasks that might have changed since yesterday.
Every code change, report change, or change to any file should be preceded by creating a branch off the main development branch. This branch should be linked to the story or task at hand. When you have finished making changes, you will test the code, make sure there are no errors, and submit a merge request. Another developer (not the author) should always review and approve merges in order to double-check all work and to ensure standards are followed.
Ideally the merge would be followed immediately by a deploy to the DEV environment. DevOps continuous deployment tool can make this simple and fast. This allows you to quickly spot errors and do testing against downstream models or visualizations.
Close the day by updating your tasks and stories.
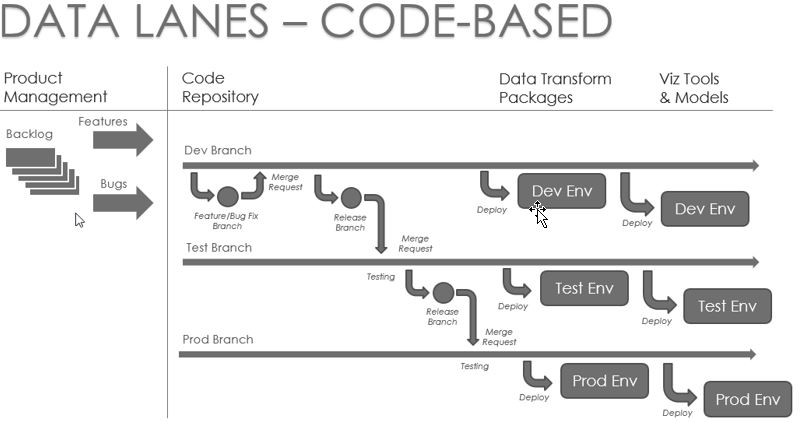
The following illustration shows the flow through stories, branches, and environments. This process looks extremely daunting if you lack the right tools to manage the process. But with some investment in DevOps capabilities, the journey of a change from a user story to a branch to deployment in DEV environment can flow naturally and be completed multiple times in one day. Then all other team members can start their next day with an up-to-date set of code and an up-to-date DEV environment.
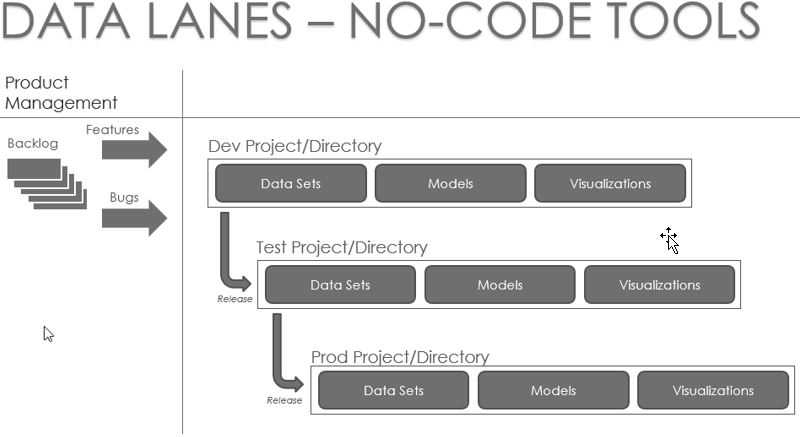
For no-code tools, the process is a little different. These tools include cloud-based all-in-one tools such as Qlik or Domo or hybrid graphical tools such as Tableau or Cognos where development is done locally but deployed in the cloud or on a server. These tools generally don’t work with third-party version control software, so version control becomes a series of processes and policies rather than tools. Release management becomes a series of steps that include formal testing by someone other than the developer, documented releases (when data, reports, and models are cloned into the new environment), and creation of backup copies.
Closing Out a Sprint
Finish your sprint by cutting a clearly labeled release branch (i.e. Release 3.1.0). Make sure that this branch is error free and that your ETL, reports, and models all run correctly. Push this release to your TEST environment for system and user testing during the next sprint. Every sprint should conclude with a post-mortem discussion of what went well in the sprint and what needs improvement. You will also need to plan activities for the next sprint.
Post-Sprint Activities
With all changes moved to a Test environment, your next sprint should have stories about testing and communicating the changes to users. Plan tasks to update documentation as needed and, if applicable, present your changes to a Change Approval Board (CAB) so members understand the overall impact of any change on the production environment. Whether you have a CAB or not, it is wise to cover your bases by documenting the change and getting signoff from management before moving into production. Finally, by the end of the next sprint you should deploy the change to the Prod environment and collect feedback from users.
Get Started Today
With this timeline and view of data lanes in mind, it’s time to assess how your team might need to change to become more agile and productive. The key concepts, no matter the size of your team or company, include:
- Divide your work into sprints and release data products in each sprint.
- Start only those tasks that you can complete in a sprint.
- Communicate often with the business before, during, and after each sprint. Produce something for them to see and use in every sprint.
- As much as possible, divide your data and reports into development lanes. Track the changes you make in each environment and move the changes in a controlled fashion to your PROD environment.
- Plan and prioritize activities that will go into each sprint at least 2-3 weeks in advance. Identify and clear obstacles so developers can be as productive as possible. Shield them from distractions so they can finish all tasks they start.
With an agile approach, your team will have a better, closer relationship with business sponsors, feel more confident in their ability to make tangible progress, and cooperate better as a team.
About the Author
Stan Pugsley is an independent data warehouse and analytics consultant based in Salt Lake City, UT. He is also an Assistant Professor of Information Systems at the University of Utah Eccles School of Business. You can reach the author via email.