Analytics and the Rebirth of the Mainframe
Mainframes have long provided powerful processing to enterprises, but lagged in their support of BI workloads. Learn how that's changed in recent years.
By Bob Potter and Bryan Smith, Rocket Software
The mainframe platform, known as System z in the IBM world, is without a doubt the most scalable, reliable and dependable transactional system in the world. It plays an important role in helping organizations manage their critical business intelligence work. Yet despite its workload power and prowess, the mainframe hasn't always been a suitable platform for business intelligence.
In this article, we examine the advantages and drawbacks of using the mainframe for BI workloads and explore how IBM has addressed the challenges.
Advantages of the Mainframe
Mainframes are designed to provide 99.999 percent availability thanks to hardware that allows for hardware and software upgrades without any application outages while allowing application access to all data. The scalability of this system "clustering" is undisputedly the best in the industry, and it is not uncommon to hear of an IBM customer who has not seen an unplanned application outage in years. "Crash and reboot" simply doesn't exist on mainframes.
That's why the largest global companies rely on mainframes for payroll processing, banking transactions, mutual fund deposits, flight reservations, and telephone billing transactions. In fact, they are almost always the best choice when ultra-high availability and scalability are desired, making the mainframe's support of BI operations so attractive.
The Mainframe's Data Dilemma
When it comes to analytics for data-driven decision making, the data stored on the mainframe -- typically in IMS hierarchical structures, COBOL copybooks, VSAM files, and DB2 tables -- are considered "locked up" and not easily accessible. Even if that data were easily accessible, the CPU cycles required to extract, transform, and move that data to more purpose-built non-mainframe analytic platforms is expensive. The system-of-record data created and stored on the mainframe is generally the most valuable data in any large enterprise, and IBM knows this. Most of the big data acquisitions IBM made in recent years have not been mainframe centric. Cognos, SPSS, Ascential Software, Vivisimo, and Netezza primarily ran on non-z/OS systems, but all products could connect to the treasure trove of data on System z.
The connectivity strategy was key for all the technologies offered by those companies, and Ascential actually provided the DataStage ETL (extract, transform, and load) product whose purpose was to deliver big batches of system-of-record data to data warehouse systems.
Nobody really likes ETL. It's messy, brittle, technical, and requires skilled labor to develop applications, yet it's a necessary way of life for delivering data to analytic platforms, often referred to as systems of analytics. The process (see Figure 1) is often the same in all use cases. You connect to the operational source system, or system of record, run an data extraction and load into a staging area -- typically an operational data store (ODS) -- and finally run another job that loads aggregated data into an enterprise data warehouse (EDW).
It doesn't stop there. Many companies extract data from the EDW and load it into report-centric data marts (DM) or OLAP cubes. This represents three ETL workflows with some level of data transformation in each step. The workflows and data flows associated with ETL batch processing are, by their very nature, prone to errors, introduce latency, and make data governance difficult because the data is being manipulated in some way, which often contaminates the authenticity of the original transactional source data.
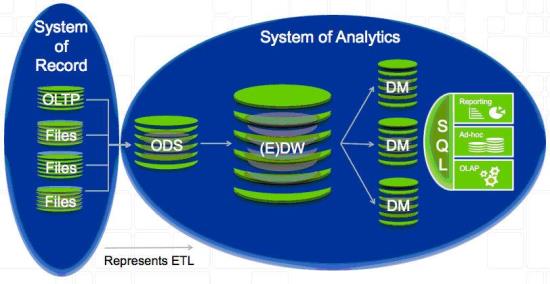
Figure 1: A traditional data warehouse architecture.
Moving data off the mainframe is expensive. You have to buy expensive ETL software and must employ (expensive) ETL developers.
Those expenses pale compared to the expense of an EDW platform, which can cost tens of millions of dollars. We respect these analytic platforms because you can get insight from well-managed and integrated data. However, they're expensive to buy, implement, run, and maintain. There will always be a market for purpose-built scalable EDWs when your environment requires mixed analytic workloads of heterogeneous data.
There are good examples of moving workloads to Hadoop for certain types of processing such as sorting. Hadoop clusters are inexpensive and some of the tooling vendors (such as Syncsort) have done a good job of moving the data back and forth affordably.
The problem is: what if you want to analyze company data that lives on your company's mainframe?
Solving the Data Dilemma
Big Blue got things moving in the right direction about eight years ago when it introduced the zSeries Integrated Information Processor. The zIIP was designed to give mainframe shops a less expensive way to run database and/or data processing workloads natively on System z. The idea was that these workloads would run on the zIIP specialty engine, which was inexpensive compared to expensive, general-purpose mainframe processors.
The idea was a good one, and some vendors rewrote their tools and applications to take advantage of this clever packaging. IBM also gave its customers an amazing gift -- the zIIPs never carried an additional charge when mainframes were upgraded. The result: economical processing on the mainframe!
Improving Query Performance
Something more compelling happened about four years ago after IBM bought Netezza, which was an x86-based data warehouse appliance for complex read-only analytic query processing: they figured out how to move that appliance to System z on z/OS sharing the same backplane as DB2. The concept is as simple as it is powerful. The appliance, called the IBM DB2 Analytics Accelerator, is attached to the mainframe as a DB2 component. DB2 tables are selected to be "accelerated" tables, which are then copied into the appliance, and the existing DB2 query engine decides whether a query submitted to DB2 would run better on the base DB2 table or against the accelerated table located in the appliance.
A DB2 analytic query that used to take two hours can now run in 40 seconds! It wasn't just the query performance that was game changing. A user didn't have to wait 24 to 48 hours to get the data in a highly normalized form for analytic processing. IBM went a step further and introduced an advanced load function for intercepting the DB2 Load utility to provide one of two options:
1. To perform a dual-load of external data to both the DB2 base table and the accelerated table, thus making the data available to the appliance faster
2. To perform a load of the data into the appliance using backups and the DB2 transaction log to populate consistent data across multiple tables without any write outage to the DB2 base tables
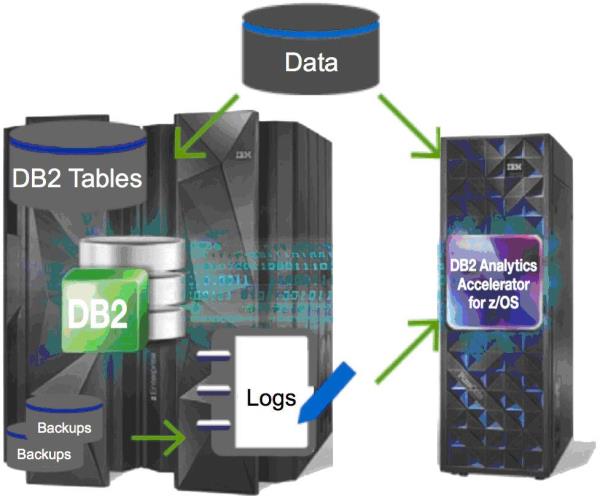
Figure 2: IBM DB2 Analytics Accelerator Loader.
Beyond DB2
All of this is fine, but what if BI data is not in a DB2 relational table structure? What if I want to analyze data in VSAM files and in IMS? IBM and its partners have diligently worked on data virtualization technology that creates integrated views of the data that is consumable by BI tools that rely on SQL as the query interface. We define data virtualization as enabling data structures that were designed independently to be leveraged together from a single source in real time and without data movement. In this way, data can be integrated "in place," enabling virtual views of heterogeneous data source and content in real time. Data virtualization allows organization to move analytics to the data instead of always moving data to the analytics engine.
One of the last pieces to the "keep BI on the mainframe" story is the reporting and dashboarding business end users demand. Cognos is a good enterprise business intelligence platform that scales to thousands of simultaneous users, but what if an end user wants something easier for ad hoc reporting and data visualization that runs natively on the mainframe? For years, IBM has offered the DB2 Query Management Facility (QMF), which is a separately chargeable feature of DB2. In recent years, Big Blue has modernized the UI away from green screen to elegant desktop and mobile visual data representation. The licensing is calculated by the size of the platform instead of the number of end users.
The Mainframe's Rebirth
Why are all of these offerings a rebirth? It's simple. Enterprises have spent time, effort and money building expertise around the people, tools, and utilities for System z, particularly z/OS. This phenomenon is why companies are changing the way they think about the mainframe. In the past, it may have been fashionable to move data off the mainframe. Now it's becoming cool to leave it where it belongs.
Bryan Smith is vice president of R&D and CTO and focuses on IBM mainframe solutions at Rocket Software, a global software developer of mainframe tools and solutions for the world's leading businesses for 24 years. You can contact him at [email protected].
Bob Potter is senior vice president and general manager of Rocket Software's business information/analytics business unit. He has spent 33 years in the software industry with start-ups, mid-size, and large public companies with a focus on BI and data analytics. You can contact him at [email protected].