
3 Things to Know About Reinforcement Learning
How do you teach machine learning new tricks? These techniques gleaned from math frameworks, gaming, and human trial-and-error interactions can help guide your AI model training.
- By Ranjana Moolya
- October 19, 2020
One of the most commonly used machine learning methods is reinforcement learning. It basically follows the trial-and-error approach for making decisions while training any model.
I’ll discuss three of the most essential things about reinforcement learning in this article:
- What reinforcement learning is
- Commonly used reinforcement learning techniques
- Practical applications of reinforcement learning
Introducing Reinforcement Learning
Let’s consider this example: You’re on a phone call and the signal strength of your mobile network is weak. You search for a location until the person you’re speaking with can hear you properly. Then you say that yes, you’re in a good network area. There was no sign nearby to tell you about that location -- you discovered that location by trial and error.
This is similar to how reinforcement learning works. You’ll hear the terms agent, reward, and environment. To understand these terms better, we’ll use the same example.
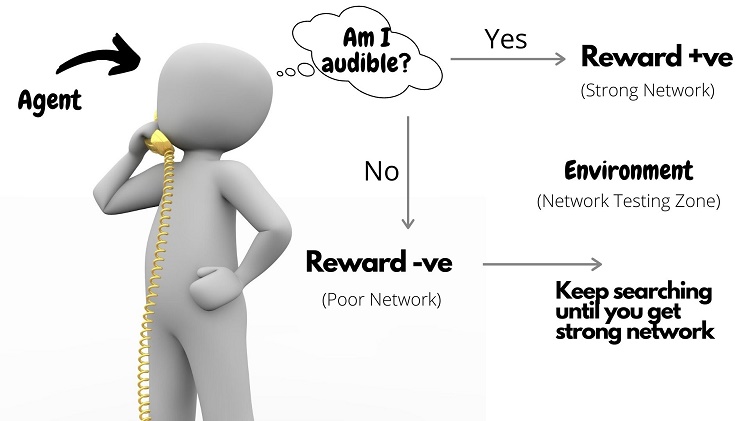
- Agent: The person looking for a good mobile network
- Reward: Strong mobile network signal
- Environment: The surrounding area
The agent keeps moving around in its testing environment to search for strong signal strength. If the signal strength is good then the reward is considered positive whereas the poor signal is negative. The stronger the signal, the more positive the reward.
In this reinforcement learning system, we aim to maximize the positive reward. How, exactly, does learning takes place in this example?
When you finally found a good network zone, you will likely remember that location. In the future, if you make another call, would you choose to go to that spot directly or would you repeat the process of searching for strong signal strength again? By returning to the “good spot,” you save time and effort. That’s how learning occurs -- from the experiences and the results. In reinforcement learning, the more experiences (searches) are added as memory, the faster you get your targeted results (strong signal spots).
Consider x to represent the location, R(x) is the reward the agent will gain depending on the current location x.
In the reinforcement learning system, the model is unaware of the reward it’s going to receive. Also, the model is not supervised – that is, it’s not told about what action to perform. It’s up to the model to explore different x values in its environment and observe the resulting reward R.
Moreover, there is no fixed set of x values. The agent is responsible for choosing a location x and the agent keeps learning from the mistakes (in our example, picking a poor signal location). The model keeps the history of actions performed, rewards received, and makes decisions and takes action accordingly.
This is how reinforcement learning is used for training a model.
Common Reinforcement Learning Techniques
Q-learning is an off-policy reinforcement learning technique (the Q stands for quality). In an off-policy approach, there are no fixed states (such as the direction of motion in our cell-signal example). The agent can move from one state to any other state (i.e, from one location to another, such as from north to south/east/west/northeast/northwest/etc.).
In Q-learning, the agent is trained iteratively to get the maximum rewards for an action it performs in any circumstance or state. The agent uses Q-values and stores them in a table in the form of Q(s, a) (where s stands for state and a stands for action).
Basically, the agent does the following things repeatedly in every interval:
- Observes current state s
- Performs action a
- Examines the resulting state s
- Receives reward immediately
- Based on which updates the Q-value of the last interval.
The agent learns from these Q-values and consequently decides the optimal strategy.
Markov Decision Processes (MDP)
MDP is a mathematical framework used to solve a reinforcement learning problem.
In MDP, the agent chooses an action based on future states and future rewards.
Let’s understand MDP by the following example:
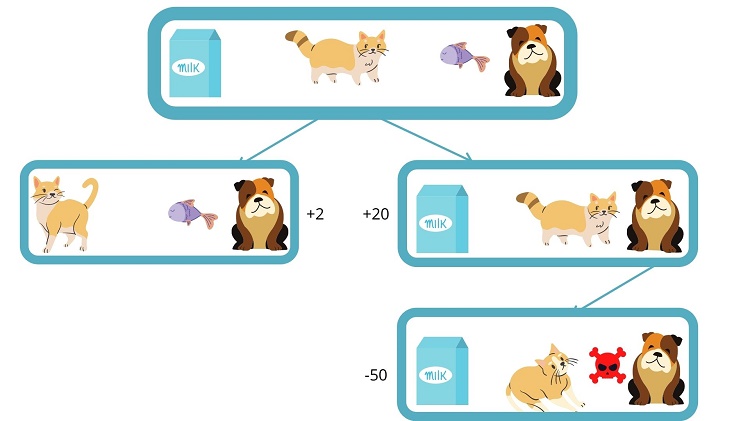
Initially, the cat (agent) has two options to consider. One – eat the fish (by moving to the right) or drink the milk (by moving to the left).
Suppose the cat decides to move to the left and drink the milk. In this case, the cat enters a new state and receives a two-point reward.
If, instead, the cat moves to the right and eats fish, the cat enters a state where it receives 20 points as a reward. However, in this new state, the cat is now next to the dog, and in this new state, the cat is attacked by the dog and loses 50 reward points.
The cat stores these events in its memory in both the cases, and when it goes for training the third time, the agent is aware of the rewards it’s going to get after performing an action. So it takes decisions accordingly.
This is how the agent learns from future rewards and states.
Practical Applications of Reinforcement Learning
One example -- in the delivery service industry -- is delivery management. As described in the paper Reinforcement Learning for Solving the Vehicle Routing Problem, a single vehicle serves multiple customers with finite demands. There is a depot location where the vehicle goes for loading new items. MDP finds the optimal route for the fastest delivery.
Here, customer and depot locations are randomly distributed in a fixed area. The vehicle’s starting point was the depot location. Initially, it served one random customer, and the shortest total route distance was given a high reward. When the vehicle was loaded with multiple packages, after each package was delivered, the vehicle’s remaining load was evaluated and the next customer chosen after applying an algorithm to keep track of the most probable paths and to find one with the minimum overall tour length.
An example in the gaming industry is Atari 2600 games. As described in the paper Playing Atari with Deep Reinforcement Learning, reinforcement learning is applied to seven Atari games, out of which an agent is found to perform better than the human expert in three of those games.
Here, the neural network (agent) is trained with the help of the Q-learning technique. The agent is made to interact with an emulator (it’s a simulation of the environment in the game) and it’s provided with the video input where it observes the images and performs an action. After performing the action it observes the emulator’s state and receives a game score (reward). It keeps a sequence of actions, observations, game scores as memory and learns the game strategies accordingly.
A Final Word
We’ve described how reinforcement learning is being used to develop artificial intelligence solutions by iteratively training the agents (models) using techniques such as Q-learning and MDP.
In the delivery service example, we saw that by using MDP, the agent succeeds in making intelligent decisions by figuring out the shortest route. In the gaming example, deep learning (neural network) is combined with reinforcement learning technique (Q-learning) for learning best strategies, and this technique is referred to as deep reinforcement learning.
To learn more, check out Deep Reinforcement Learning, A Beginner's Guide to Deep Reinforcement Learning, or What You Need to Know About Deep Reinforcement Learning.
About the Author
Ranjana Moolya is the SEO intern at Flinkhub where she is responsible for content marketing, content writing, and on-page SEO activities. She is an electronics engineering graduate. You can reach the author via email.
.