
Don’t Let Your Data Lake Become a Swamp (Part 2 of 2)
What, exactly, does the infrastructure look like that we need so data lakes can support analytical processing?
- By Bill Inmon
- March 24, 2016
People use big data to create data lakes. By doing so, they can store data cheaply over a long period of time. The hope is that the data that is stored will be used for analytical processing. People hire expensive data scientists to help them extract the data from the data lakes. Then people wake up one day to discover that they can’t use data lakes to do analytical processing or that the cost of the data scientists is so high that the business value is not worth it.
The fact is that the data stored in the data lakes does not support analytical processing to any great extent. In fact, people find they can hardly locate the most trivial piece of data in their data lakes.
In Part 1 of this discussion we examined the problems with storing data in data lakes and what had to be done in order to create a foundation of analytical processing. An infrastructure needed to be superimposed over the data stored in data lakes if the data lake is to be used for serious analytical processing, by the data scientists or anyone else.
In this article, we continue our discussion by looking at what, exactly, does the infrastructure look like that we need so data lakes can support analytical processing?
Non-Repetitive Data
The data found in data lakes can be generally divided into two classes: repetitive data and non-repetitive data. For repetitive data to be turned into a foundation for analytical processing, you need another infrastructure that includes:
- The metadata definition of the structure of the records found in repetitive record
- The historical tracking of the changes to the metadata of the records found in repetitive data
- The transformation mapping that is required to turn the metadata into an integrated file
- The source and lineage of the data that has found its way into the data lake
Once the repetitive data in the data lake has this infrastructure defined, the raw repetitive data is transformed into integrated data that can then be used as a basis for analysis.
Non-repetitive data needs a transformation of data as well. However, the transformation for non-repetitive data is an entirely different kind of transformation that that used for repetitive data. The transformation for non-repetitive data requires that non-repetitive data be passed through textual disambiguation. The output of the textual disambiguation process is text and context that has been transformed into a form that is fit for storage inside a database. The process of textual disambiguation includes such functions as:
- Taxonomy/ontology classification
- Stop word processing
- Homographic resolution
- Proximity resolution
- Alternate spelling resolution
- Custom variable resolution
- Acronym resolution
- Inline contextualization
In fact, there are many other aspects to the transformation of non-repetitive data.
Once the raw text has been placed into a contextualized format inside a database, the non-repetitive data is fit for analysis.
In both cases, raw data -- either repetitive or non-repetitive raw data -- data in the data lake needs to be fundamentally transformed before it is fit for analytical processing.
There are two basic architectural choices you need to make. Either the analyst can transform the subset of data need for analysis before it is analyzed each time an analysis is performed or the analyst can transform all the data once and have this transformed data available for analysis at any time.
Figure 1 shows the choices:
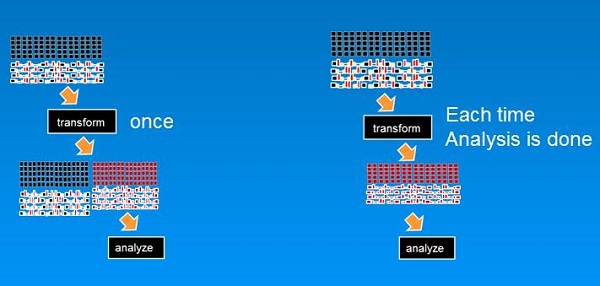
Either option works. There are, however, different tradeoffs associated with each choice.
Transforming Needed Data Before Analysis
First let’s consider the option of transforming the data each time you need a fresh analysis.
The pros associated with this option are that only a limited amount of permanent storage is necessary and the transformation process can be customized for each analysis.
The cons associated with this option include:
- A transformation needs to be performed before analysis can commence. This delay may be unacceptable to the end user because the transformation requires considerable set-up time and execution time.
- A significant amount of repeatable processing is needed each time an analysis is needed. This requires considerable machine resources.
- There is a good chance the transformation done for one analysis will not match the transformation done for a preceding analysis. When there is a discrepancy between the transformations, the results of analysis across multiple analyses may not be consistent.
- You need to perform the transformation consistently from one analysis to the next.
- You need to carefully document the transformation process and algorithms used.
Transforming All Data Once
The other alternative is to perform the transformation once, then store the transformed data. Succeeding analysis is performed against the transformed data. In this case, transformation is done only once for all analytics work.
The benefits of this option include:
Analysis can be done immediately. There is no need to do a transformation before the analysis is done
The transformation performed for an analysis is ALWAYS consistent with the transformation done for any other analysis. There is never a conflict between any two analyses caused by a difference in transformations because there is only one transformation.
One downside of this option is that more permanent storage is required.
Summary
There are then two basic ways of performing transform and analysis. There is no right way or wrong way. Instead, there are tradeoffs associated with each choice.
Whichever choice you make, you must transform data-lake data before any analysis is performed.
The choice is yours -- create data lakes that become corporate white elephants or create data lakes that have an infrastructure that supports analytical processing.
About the Author
Bill Inmon has written 54 books published in 9 languages. Bill’s company -- Forest Rim Technology -- reads textual narrative and disambiguates the text and places the output in a standard data base. Once in the standard data base, the text can be analyzed using standard analytical tools such as Tableau, Qlikview, Concurrent Technologies, SAS, and many more analytical technologies. His latest book is Data Lake Architecture.