Integrating Canonical Message Models and Enterprise Data Models (Part 3 of 3)
Although an enterprise data model (EDM) can be used to facilitate messaging (as described in Part 2 of this series), this way of using an EDM does not achieve the same results that would be achieved by using the EDM to instantiate databases.
By Dr. Tom Johnston, Chief Scientist, Asserted Versioning, LLC
The first of Chisholm’s use cases for enterprise data models (EDMs) is for “instantiating databases.” However, as we saw in Part 1, although EDMs are sometimes used as a paper reference model, most databases within an enterprise are imperfect and incomplete instantiations of their EDMs, so data about the same “things” is often stored in different ways across those databases. Consequently, when that data is exchanged between those databases or assembled from multiple databases in query result sets, those differences must be resolved.
For many years, a point-to-point approach to resolving those differences has been taken, more by default than by conscious choice. For any data exchanges between a sending and a receiving database, resolving differences meant mapping the source data into the format required by the target database. Consequently, the two databases were tightly coupled. A change in how the data was stored in either database meant that the data exchanges involving that data would fail unless the mapping was revised.
The second of Chisholm’s use cases for EDMs is to “facilitate messaging.” Employing a hub-and-spoke paradigm, in which point-to-point translations are replaced by translations into and out of a canonical format, the messaging layer of Service-Oriented Architectures reduces the number of translations required for databases to communicate with one another.
The corporate EDM takes on the role defined by this second use case by defining a complete canonical format for corporate data to which each canonical message must conform. Because asynchronous messaging no longer requires a physical store-and-forward database, and because synchronous messaging never required one in the first place, the corporate EDM becomes realized as a virtual corporate database, not as a never-to-be-attained physical one. Its physical realization is in the messages which conform to it.
I point out again, as I did in Part 2, that the hub-and-spoke architecture in which the EDM is a virtual hub, is itself a semantic architecture, not a physical one. Suppose that all the connections between a set of communicating databases are physically implemented as point-to-point connections, some connections exchanging data as real-time messages and others as batch extract, transform, and load processes. As long as all these exchanges translate all data coming out of source systems into an EDM-defined canonical format, and accept only data in canonical format as input flowing into target systems, the benefits of canonical format messaging will be realized. Thus, the architecture mediating the semantics may be completely different from the architecture mediating the physical exchanges.
With either of Chisholm’s use cases for EDMs, the basic problem remains: because the communicating databases themselves are not EDM consistent, mapping will be necessary for them to communicate with one another.
Because the corporate EDM is now a messaging model as well as a database model, it should include the definition of the mappings that mediate message exchanges between databases and not just the definition of an idealized database. Let’s call this the “extended EDM,” or “E-EDM,” and the new part that includes mapping definitions the “Rules Dictionary” component of the E-EDM.
The Mapping Rules Dictionary
Each mapping rule describes a translation either from a source database to the virtual EDM, or else from the virtual EDM to a target database. These rules are illustrated in Figure 1, in which the EDM is marked as the underlined database.
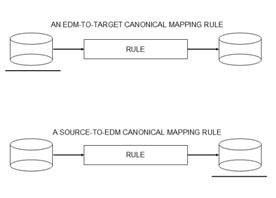 Figure 1. Mapping rules
Figure 1. Mapping rules
A source-to-target mapping combines a source-to-EDM rule and an EDM-to-target rule. This is illustrated in Figure 2.
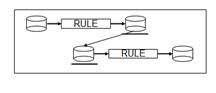 Figure 2. A source-to-target mapping
Figure 2. A source-to-target mapping
One way of designing end-to-end rules is to proceed from both ends back towards the middle. First, there is usually a preferred source for the data needed by the target database. All messages from that source that include at least all that data are selected. These are candidates for the mapping from the source to the virtual EDM. Next, all messages whose target format is used by the target database, and which includes at least all the data needed for that message, are selected. Finally, source-to-EDM and EDM-to-target mappings are matched such that the EDM content of the former fully contains the EDM content of the latter.
The result is a complete source-to-target mapping of the desired message content from the preferred source system, delivering the data in a format recognizable to the target system.
Frequently, however, no such pair of rules can be found. In those cases, one option is to write a new source-to-EDM and/or a new EDM-to-target mapping. With a sufficiently robust set of rules already in the Rules Dictionary, another option is to chain together a set of already-existing rules. This second option is illustrated in Figure 3.
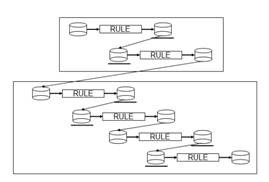 Figure 3. Chaining mapping rules
Figure 3. Chaining mapping rules
Other topologies of mapping rules are also possible. For example, a rule may use multiple sources to produce one EDM-compliant target, or multiple EDM-sources to produce one non-EDM target. It is beyond the scope of this article to examine such additional topologies, but once again I emphasize that these are topologies of semantic relationships, not of physical ones.
The E-EDM
Figures 4 shows the major components of an EDM extended to include a Rules Dictionary. The enterprise data model diagram is more than a diagram, of course, because it includes the semantics that distinguish primary keys from all other attributes, foreign keys from all other attributes, that express the minimum and maximum cardinality of relationships, that define datatypes for attributes, and whose entities represent interpreted mathematical relations.
The Data Dictionary provides definitions for all instances of the major components of the data model, those components being entities, attributes, relationships, and domains. The Mapping Rules Dictionary has already been described, although far too briefly.
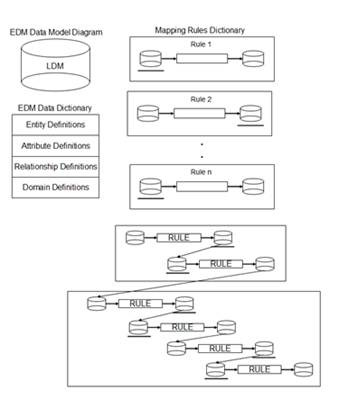 Figure 4. An enterprise data model extended to include mapping rules
Figure 4. An enterprise data model extended to include mapping rules
For every message sent from a specific database, the E-EDM’s Rules Dictionary includes the rule required to translate the message into an EDM-consistent format. For every message received by a specific database, the E-EDM Rules Dictionary includes the rule required to translate that message from an EDM-consistent format into one recognizable by the target database. This set of rules constitutes the “semantic Web” which makes a semantically consistent whole out of the set of communicating databases. (Note: this has nothing to do with the “semantic Web” as an Internet infrastructure, except that both refer to a web of semantic relationships.)
The Semantics of the Rules Dictionary
I pointed out in Part 2 that as long as we do not re-engineer communicating databases to conform to a canonical data model, we leave untouched the problem of both semantic and syntactic mismatches between those databases -- the semantic mismatch problem being by far the more difficult one. Mapping rules don’t eliminate those mismatches, they merely paper them over. Thus, both of Malcolm’s use cases for an EDM leave us with the semantic mismatch problem.
The use of an EDM as a canonical message model does provide this benefit, though, and it breaks the semantic mismatch problem between two databases into a set of small chunks. Each chunk is one message between those databases. Far preferable would be to redefine the semantics of the participating databases so that there were no more semantic mismatches among them. This, in turn, suggests that there is a difference between eliminating semantic mismatches and resolving them.
There is indeed such a difference. That difference, and the complex work of eliminating or resolving semantic mismatches, are the points at which semantics becomes relevant to data and to information technology. Unfortunately, it seems to me, semantic technology has focused far too much on the technology and far too little on the semantics, but that, and its relevance to an E-EDM Rules Dictionary, is a story for another time.
- - -
 Tom Johnston has a doctorate in Philosophy, with a concentration in logic, semantics, and ontology. He has worked with business IT for over three decades and, in the latter half of his career, as a consultant for over a dozen major corporations. He is the author of nearly 100 articles in IT journals and is the co-author of Managing Time in Relational Databases (Morgan-Kaufmann, 2010). Information on the Asserted Versioning Framework, the bitemporal data management software offered by Tom’s company, is available here.
Tom Johnston has a doctorate in Philosophy, with a concentration in logic, semantics, and ontology. He has worked with business IT for over three decades and, in the latter half of his career, as a consultant for over a dozen major corporations. He is the author of nearly 100 articles in IT journals and is the co-author of Managing Time in Relational Databases (Morgan-Kaufmann, 2010). Information on the Asserted Versioning Framework, the bitemporal data management software offered by Tom’s company, is available here.
Tom offers seminars on the management of temporal data at client sites that utilize client data issues to illustrate important temporal concepts. You can contact the author at [email protected].