Lesson from the Experts: Scaling Very Large Data Warehouses in an MPP and Grid World
Corporate data warehousing has seen dramaticincreases in volume and complexity over the last several years. Increasingly stringent regulatory requirements coupled with dramatic business success stories have catapulted organizations towards low-cost DW appliances to manage VLDW (very large data warehouse) projects. Indeed, VLDW projects in the hundreds of terabytes are increasingly commonplace. There are considerationsbeyond speed and price, however. The processes,methods, and resources required to successfully realize an enterprise VLDW deployment on these appliance technologies must keep pace with the eye-popping performance metrics.
Jesse Fountain, Microsoft Principal Group Program Manager, SQL Server Customer Advisory Team (formerly VP, Pre-Sales Services, DATAllegro)
Corporate data warehousing has seen dramatic increases in volume and complexity over the last several years. Increasingly stringent regulatory requirements coupled with dramatic business success stories have catapulted organizations towards low-cost DW appliances to manage VLDW (very large data warehouse) projects. Indeed, VLDW projects in the hundreds of terabytes are increasingly commonplace. There are considerations beyond speed and price, however. The processes, methods, and resources required to successfully realize an enterprise VLDW deployment on these appliance technologies must keep pace with the eye-popping performance metrics.
The hardware platform can quickly become the smallest piece of a VLDW budget. Data quality, security, monitoring, ETL, business intelligence, and administration are likely, but not exhaustive, aspects of one of the most challenging IT projects a business will face. While the scope of a VLDW project can seem overwhelming, there are some key considerations that can help realize the potential of the newer MPP database technology:
- Adopt an iterative project methodology such as agile or spiral.
- Choose an integrated hardware environment that supports your development methodology.
- Identify and leverage the strengths of the database platform. For example, higher speed loading is useful only if your infrastructure supports it.
- Ensure that training and functional practices are adopted that support and leverage the new technology.
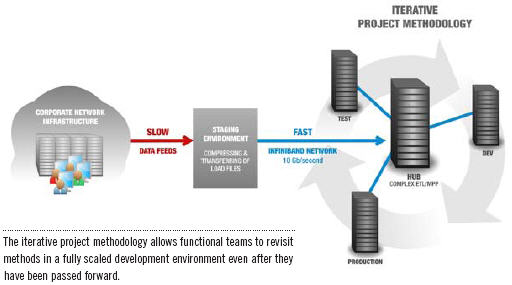
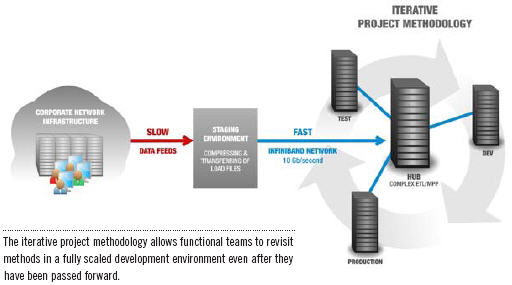
Hardware is Only a Part of the Project Solution
The promotion of iterative methodologies for data warehouse project development has been an important industry shift in recent years. Nearly every purveyor of warehouse hardware or services touts a methodology that supports iterative prototyping, rescoping, and decoupling of project phases in a meaningful way. Yet, revisiting the project scope and design based on results from iterative prototyping exercises can quickly bog down a project timeline. A chief reason for this is contention, availability, and scale of development environments. Very few companies can afford test and development environments that are representative of their production counterparts given legacy hardware prices. Yet many organizations fail to consider the effect hardware choices can have for project delivery.
Data warehouse appliances are fundamentally resource-rich, providing dedicated network resources, shared nothing CPU, IO, and storage at a price point that makes scale-out realistic. They create a solid foundation for project teams to focus on iterative development practices. Loosely coupled systems with high-bandwidth connectivity can isolate individual project teams from each other’s mistakes while driving collaboration and information sharing at VLDW scale.
Hardware and Methodology Aligned
DATAllegro offers high-speed grid connectivity between DW appliances. Grid offers alternative solutions to VLDB ETL and project management issues that would be unthinkable in a traditional environment. Consider our customer with a 100+ terabyte production system. That production appliance is mirrored by a same-size development/staging system and a smaller (if you consider 12 terabytes small) fully dedicated test appliance. All of this resides within the same 10 Gb/second grid-connected network. This environment allows the practice of an iterative project methodology to be realized. Instead of taking days to provide a small sample of production data in a test environment, more substantial samples are generated and copied to the test or development systems in minutes. This allows functional teams the luxury of revisiting methods in a fully scaled development environment even after they have been passed forward to other teams or promoted to production.
A telling example from another project of similar scale illustrates how valuable this can be. Several subject areas of a core data model had already been deployed to production when a situational test team uncovered the need for a significant change. The data model was the core dependency for other major functional teams such as ETL and BI, and any changes would be very costly in time and effort. In this case the team was able to promote the changes to one of two development systems first. This gave each functional team a chance to fully evaluate the effect of the changes in a full-scale environment. In the end, changes were still required, but the working prototype allowed each functional team a chance to provide input and offer time-saving modifications. The overall effect on the project was significantly reduced while navigating one of the most difficult challenges in iterative development.
Capitalizing on Super-Fast Appliance Data Loaders
Loading at rates that exceed one terabyte per hour has become passé in the DW appliance market in the last few years. Nearly every appliance vendor can now demonstrate rates at or above this mark with most types of data. What is often overlooked (at least until the appliance arrives in the data center) is that these load rates are nearly always overkill for existing corporate network infrastructure. The data has to come from somewhere, and the legacy source systems and network are typically resourceconstrained, expensive, and not in-scope for upgrade in context of a data warehouse project. Given this, it is very important that appliance vendors provide a solution that goes beyond flashy load rates.
More than one DW appliance vendor now provides a dedicated “load staging” server as centerpiece of load operations. This approach provides an expansive and scalable staging area for preload staging and export operations. In addition, the server typically sits inside the appliance’s private network, providing direct, uncontested access to the appliance’s high-speed bulk load capability.
An issue common to VLDW deployments illustrates why positioning this type of staging resource within the appliance “stack” is so important. Lower priority source data files can sit for hours in the ETL staging environment behind higher priority files or database tasks. Delays in source system or ETL process are commonplace and leave little time to catch up on these lower priority files. Furthermore, loads to the data warehouse are effectively limited to network transfer rates from the ETL staging system to the data warehouse platform. To address this problem and leverage the higher potential load rates of the newer DW appliance technologies, data transfers from the ETL staging environment to the data warehouse are decoupled. This is accomplished by compressing and transferring load files to the staging server(s) as soon as they are complete in the ETL stage environment, rather than waiting for database loader availability. While some files invariably need to be loaded immediately, it becomes far easier to catch up on lower priority files as they leverage the full bandwidth of the dedicated appliance network and bulk loader.
MPP Expertise Is Important
Similar to Teradata in concept, the more successful DW appliances are massively parallel, distributed systems. This means that data is uniformly shared (distributed) across many discrete (typically shared nothing) units of work. Compared to an SMP system such as Oracle, this provides many performance advantages for VLDW deployment. However, a basic theory of MPP systems provides a useful illustration in this case; a parallel operation is only as fast as its slowest unit of work. This is also true of the practice of deploying a data warehouse on an MPP system. The environment is only as fast as the methods and procedures that define the environment will allow.
A common barrier encountered in VLDW projects is the counterintuitive nature of many MPP system best practices. For example, index-supported operations often underperform IO optimized full scans. Furthermore, full scans take on new meaning in a distributed, MPP system. Parallel scanning provides full-table scan operations in the time it takes to perform a scan for the largest distribution of a table (as little as 1/192 of the data on a large system). Partitioning, a common performance paradigm for distributed systems, also fundamentally differs from indexing strategies. Partitioning relies on the context of user queries (specifically restrictions). Index-based strategies focus on join criteria and the physical characteristics of the data. These are just a few brief examples that underscore the importance of expertise and training for a VLDW project.
The Right Mix of Hardware and Solution
Wrapping endless methodology and bottomless resources around the wrong hardware solution is just as unlikely to deliver a successful VLDW as providing the fastest hardware in the world with no solutions or experience. Although it is true that DW appliances have proven the ability to scale active data warehouses into the hundreds of terabytes while achieving dramatic performance improvements, developments in the methodology and practices used to deploy these massive environments are equally important. Although it is common to ask “how fast” when evaluating these systems it is just as important to ask “how.”
For more information about DATAllegro, click here.
Next
Previous
Back to Table of Contents