Operational Data Integration
- By Philip Russom, Ph.D.
- April 25, 2007
By Philip Russom, Senior Manager, TDWI Research
This article introduces one of the hottest and fastest-growing practices in data integration today: operational data integration. Before we look at different manifestations of operational data integration—like database consolidations, migrations, upgrades, and so on—let’s distinguish it from analytic data integration and explain why you should care.
Distinguishing Enterprise, Analytic, and Operational Data Integration Practices
Enterprise data integration—defined as every imaginable use of data integration—divides into two broad practice categories (see Table 1):
- Analytic data integration is applied most often to data warehousing (DW) and business intelligence (BI). It’s also applied (less often) to initiatives like customer data integration (CDI) or master data management (MDM).
- Operational data integration manifests as implementations, projects, or initiatives commonly described as the consolidation, collocation, migration, upgrade, or synchronization of operational databases. This article will look at each of these in detail later.
As a rule of thumb, the database targets distinguish the two practices of analytic data integration and operational data integration. For example, if data integration feeds an analytic database like a data warehouse or mart, then it’s most likely an analytic practice. If it feeds or creates a database supporting an operational application, then it’s probably operational data integration. Of course, data integration tools and techniques enable both practices, and some enterprise initiatives—like operational business intelligence and master data management—straddle the fence to bring the two practices together.
As a quick aside, let’s remember that data integration uses a variety of techniques and tool types, including enterprise application integration (EAI); enterprise information integration (EII); extract, transform, and load (ETL); replication; and miscellaneous utilities.
| ENTERPRISE DATA INTEGRATION |
| Analytic Data Integration |
Operational Data Integration |
| Initiatives commonly supported: |
Initiatives commonly supported: |
| Data warehousing (DW) |
Database consolidation |
| Business intelligence (BI) |
Database collocation |
| Initiatives less commonly supported: |
Database migration |
| Customer data integration (CDI) |
Database upgrade |
| Master data management (MDM) |
Database synchronization |
Table 1. A taxonomy of data integration practices.
IT professionals implement these techniques with vendor tools, hand coding, or functions within database management systems. It’s true that some techniques and tools are closely associated with particular initiatives, like ETL with data warehousing or replication with database synchronization. Yet, all the techniques and tool types under the broad rubric of data integration operate similarly: they copy data from a source, merge data coming from multiple sources, and alter the resulting data model to fit the target system it will be loaded into. Because of the similar operations, industrious users can apply just about any tool (or combination of tools) to any data integration implementation, initiative, or project.
You should care about the distinction between analytic and operational data integration practices because the two have different technical requirements and organizational support:
- Technical requirements. Analytic data integration usually involves hefty transformational processing to create time series and other dimensional data structures required of a data warehouse. Analytic data integration also supports dozens of data sources and targets coordinated via a hub-and-spoke architecture. By comparison, operational data integration is simple, involving light data model transformations between relatively few data sources and targets (sometimes only one source and one target) connected via point-to-point interfaces. These are the main reasons why ETL and EII—with their unique transformational capabilities and hub architectures—are the preferred techniques for analytic data integration, as well as why the simple interfaces with light transformations found in replication, EAI, and hand-coded practices are sufficient for most implementations of operational data integration.
- Organizational support. Analytic data integration is usually staffed by the data warehouse team and funded by its sponsor, whereas operational data integration projects are often staffed by a data management or applications group within IT with sponsorship from line-of-business managers and others associated with the applications. As the number of operational data integration projects has increased in recent years, IT management and others have drawn data integration specialists from the data warehouse team to perform operational work. This is a problem, because it sets back the goals of data warehousing and goes against the grain of organizational structures and funding. Staffing both camps with data integration specialists is a common solution, despite the resulting redundancy of personnel. To avoid such redundancy, some corporations create a data integration competency center, which staffs both analytic and operational data integration practices as a single resource via shared services.
Problems that Operational Data Integration Addresses
Before describing operational data integration implementation types, let’s step back and consider why these are necessary.
Redundant data and non-standard databases are the main problem. For example, when data repeats across multiple databases, it’s hard to keep the databases synchronized. Likewise, data may reside in a legacy database that is beyond its prime or in a database brand that is simply not the corporate standard. To put it another way, these are problems because they increase IT costs and inhibit unified visibility into business processes. In a related trend, many organizations today try to “do more with less” and centralize both IT and business operations. These situations eschew redundancy and promote standards; thus, they seek solutions via database consolidations, migrations, and so on.
Redundant and non-standard applications are a problem, too. An implementation sometimes focuses on an operational application that’s a legacy needing migration to a more modern brand or an application instance that’s redundant and should be consolidated with other instances. Because there’s a database in the application’s technology stack, some form of operational data integration is required to migrate or consolidate the database.
Implementations of Operational Data Integration
Now that we’ve defined analytic and operational data integration practices and explained why you should care, let’s look at some of the benefits and challenges of common implementations.
Database Consolidation. This is where IT personnel consolidate multiple, similar databases (often with redundant content) into a single one, with a single data model. If a single database isn’t a realistic goal, then data is at least consolidated into fewer databases. The most common project is probably the consolidation of redundant CRM or ERP applications and their databases. As another example, many organizations have multiple mid-tier databases containing slightly different views of customer data, and these are ripe for consolidation. On the analytic side of data integration, consolidations are a popular way to reduce the number of redundant data marts.
The upside of database consolidation is that it reduces IT maintenance costs by consolidating data into fewer servers. Furthermore, it increases visibility into business processes by putting “data eggs” in fewer baskets. The downside is that consolidation is extremely intrusive, in that it kills off the consolidated systems. Their owners, sponsors, and users may resist passing control, typically to a central organization, and these people are usually forced to change business processes associated with the consolidated systems.
Database Collocation. Collocation and consolidation are similar. In a database consolidation, diverse data models are merged into a single data model in a single database instance. This is hard work, so sometimes it’s faster and easier to collocate databases. Collocation copies multiple databases into a single instance of a database management system (DBMS), typically on a single hardware server, without merging the data models. In other words, one DBMS instance manages multiple databases. While collocation reduces IT maintenance costs, it doesn’t solve the information silo problem like database consolidation does.
Database Migration. In a migration, database brand A gets migrated to brand B. Typical examples include migrating a database from a mainframe to a less expensive open system, from a legacy platform to a more easily supported one, or from a non-standard brand to one that’s a corporate standard. Migrating to a newer or standard database increases the flow of information among systems by making data access and integration easier. This way, database migration contributes to advanced integration goals, like real-time or on-demand information delivery.
Like consolidation, migration is intrusive, because it kills off the original system, forcing changes to business processes and applications. With database migrations off of legacy platforms (especially the mainframe), you need to check contracts before committing. Sometimes issues of licensing, leasing, depreciation, or amortization can halt the retirement of an old or non-standard system. And beware that database migration is something of a myth; it’s more like new development when the target system doesn’t exist and must be designed and built from scratch.
Database Upgrade. This is where version X of a database brand is upgraded to version X+1 of the same brand. A database upgrade can be a discrete project or an interim step within larger operational data integration implementations. For instance, it might make sense to upgrade all databases to the same release before consolidating them. And upgrading a legacy or non-standard database to the most recent version first can make it easier to migrate. Sometimes multiple upgrades are required, say from version 6 to 7, then from version 7 to 8.
But is a database upgrade really data integration? Yes, it can be. For instance, when customizing a packaged application alters its database’s data model, upgrading the application requires operational data integration to upgrade the database. Furthermore, when a new version of a DBMS changes how it stores data, a database upgrade can require transformational processing to get the data into a model optimized for the new version. Finally, when IT decides to improve a data model in tandem with an upgrade, some form of operational data integration is required.
Database Synchronization. The types of operational data integration we’ve seen so far—database consolidations, collocations, migrations, and upgrades—move whole databases in one-off pro-jects that rarely require that integration infrastructure be left in place. Database synchronization is different, in that it leaves databases in place and exchanges data among them, which requires a permanent integration infrastructure for daily data feeds. The downside of synchronization is the initial cost and maintenance cost of the infrastructure. The upside, however, is that synchronization is non-invasive because it leaves database investments and the business processes that depend on them intact. In fact, when it’s not possible to consolidate or migrate databases, managing redundant data usually involves keeping it synchronized across related databases.
High-end implementations of database synchronization include transformational processing and many-to-many data movement, and so ETL is a popular choice. But the reality is that most implementations move data only from one database to one other with little or no transformation. For these, replication and even EAI are suitable techniques.
All other implementation types considered here are inherently one-way and latent. But database synchronization can address unique requirements for two-way data movement or real-time information delivery. Two-way data synchronization has the added burden of resolving conflicting data values, which is best done with high-end replication or ETL tools, or possibly an EAI tool. Real-time data synchronization is usually done with replication, or sometimes with EAI.
Operational Data Integration Implementations Compared
So far, we’ve seen that database consolidations, migrations, and upgrades can address the problems of redundant and non-standard databases, thereby reducing IT administrative costs and increasing business visibility into operational data. When these aren't possible, database synchronization and collocation can alleviate some problems in a less invasive way.
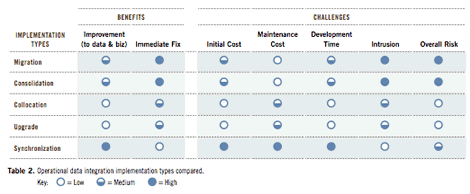
That's the good news, and it's great to have options. The bad news is that—given the long list of options—it's sometimes difficult to decide which type of operational data integration implementation (or combination) is most appropriate for a particular situation. Table 2 assesses the benefits and challenges of the operational data integration implementation types discussed in this article. The assumption is that selecting one or more implementation types involves a trade-off between benefits and challenges. For example:
- Database migration and consolidation are great immediate fixes that can add value to data, despite high risk because of their highly intrusive nature.
- Collocation and upgrades are low-risk because they're cheap, fast, and relatively non-intrusive. But they add little or no visible value to data and business processes.
- Database synchronization improves data content tremendously in a non-intrusive way, but suffers high initial costs (especially when you first put in integration infrastructure) and administrative costs over time (because you must maintain the infrastructure).
You needn't agree with all the assessments in Table 2, because you can adapt it to reflect your own assessments and those of your colleagues. You might also expand the table to include other implementation attributes that matter to you, like which data integration techniques (ETL, EII, EAI, etc.) are best suited to each implementation type and how applicable each is in your organization (perhaps based on preexisting tools and expertise). Regardless of how you adapt it, a table based on consensus-driven assessments can give the decision-making process more consistency and efficiency. In addition, it will serve as an established vocabulary to get communication and collaboration started.
Recommendations
Segregate operational data integration from analytic data integration. The two involve different types of implementations (or projects, if you will), although both can be done with similar techniques and tool types, like ETL, replication, EAI, and so on. And the two usually have separate sponsorship, funding, and staffing. A possible exception to this recommendation is to bring the two practices together in a data integration competency center.
Address redundant or non-standard databases. This is done with various implementations of operational data integration, namely database consolidation, collocation, migration, upgrade, and synchronization. These projects are worth doing, because reducing the number of redundant databases and moving data to standard databases reduces IT administrative costs and increases visibility into business processes.
Expect to apply multiple implementations of operational data integration. For example, database collocations and upgrades are typical prerequisites for database migrations and consolidations—or vice versa, in some cases. And some databases may need synchronization after they've been migrated or consolidated.
Realize that database consolidations and migrations aren't always possible. After all, these are highly invasive. But database collocation and synchronization get similar results less intrusively. Apply your alteration of Table 2 to selecting an operational data integration implementation type or a combination of types.
About the Author
Philip Russom, Ph.D., is senior director of TDWI Research for data management and is a well-known figure in data warehousing, integration, and quality, having published over 600 research reports, magazine articles, opinion columns, and speeches over a 20-year period. Before joining TDWI in 2005, Russom was an industry analyst covering data management at Forrester Research and Giga Information Group. He also ran his own business as an independent industry analyst and consultant, was a contributing editor with leading IT magazines, and a product manager at database vendors. His Ph.D. is from Yale. You can reach him by email ([email protected]), on Twitter (twitter.com/prussom), and on LinkedIn (linkedin.com/in/philiprussom).