LESSON - High Performance Technologies Add Up to Successful Business Intelligence
By Susan Garretson Friedman, Senior Technical Analyst, Syncsort Incorporated
Growth rates and new opportunities for all kinds of businesses, in particular banks and other financial institutions, mean they have to process skyrocketing amounts of data. In financial institutions, the data glut is further complicated by the need to comply with legislation such as the Basel II Accords, Check 21, Sarbanes-Oxley, and the USA PATRIOT Act or risk running afoul of government regulations. More financial institutions are also realizing that they need fast and accurate intelligence from their data to stay competitive in today’s real-time business world. Data management, and data governance, have become priorities. In 2005, according to a Knightsbridge Solutions white paper, these pressures led to financial institutions making major investments, totaling more than $1 billion industry-wide, in basic data infrastructure and data governance. Much of that money was spent trying to improve access to, and the quality of, real-time business intelligence.
The consulting group Gartner has been quoted in DM Review as recommending that organizations focus on the following financial reporting criteria:
- Collecting financial data
- Making financial details more accessible
- Drilling down on accounting reports
- Highlighting key analysis areas based on tolerance and financial metrics
- Segmenting reporting into significant elements
- Enabling workflow
- Offering frequent flash reporting
- Instilling a financial management mindset within the organization
Business intelligence (BI) offers enterprises the ability to meet all those criteria as well as the requirements for competitive analysis.
For processing data for BI analytics, the usual go-to software includes various ETL and data warehousing solutions. However, we have discovered that these tools do not always yield the peak performance that institutions need to maximize their intelligence gathering and minimize the processing time it takes to get it. Often an additional tool can contribute to speeding up the processing times of high volumes of data. In particular, the higher-level functions, such as high-performance joins, aggregations, string, time/date, arithmetic, and user-defined functions, can help enormously when combined with existing database or ETL software, or in speeding existing company-generated processes.
A Quick Overview
High-Performance Aggregation
Data warehouse experts agree that aggregates are the best way to speed warehouse queries. A query answered from base-level data can take hours and involve millions of data records and millions of calculations. With precalculated aggregates, the same query can be answered in seconds with just a few records and calculations.
High-performance aggregation simplifies the creation, administration, and execution of aggregation jobs. It summarizes data much faster than other aggregation methods such as C programs, SQL statements, or third-party, multi-purpose data warehouse packages. It provides the necessary flexibility to select the best aggregates for optimizing query performance.
High-Performance Joins
High-performance joins significantly improve the efficiency of preprocessing, retrieval, and updating in a dimensional data warehouse, providing the following significant benefits:
- Optimize data preparation
- Improve query performance
- Reduce the quantity of data that must be processed in response to a query
- Speed lookups and application matching
- Retrieve and summarize information more efficiently
- Minimize storage and throughput requirements
- Reduce elapsed time of change data captures and delta processing
Additional Functions
Additional data transformation capabilities include arithmetic functions, string functions, date/time functions, and user-defined values. User-defined values allow easy definition of tasks that enable powerful data transformations and perform complex processing.
Real-Life Examples
A number of our customers have found that adding these advanced, high-performance functions yields excellent results. One major investment bank experienced a 90 percent reduction in their customer management data processing time.
They wanted to improve the performance of a lengthy product/customer data management process that originally involved five major procedures, all written in Java. Legacy Java-based applications were consuming vast amounts of system resources and time due to recent increases in data volumes. The bank’s applications needed to be upgraded in order to reduce elapsed time for routine customer management processes. The processes included data extractions, joins, merges, reorganizations, and loads in a networked UNIX environment. The bank’s existing solution, using programs written in Java, took 30–32 hours to complete.
The solution: The Java procedures were converted to high-performance features in stages, eliminating the need for a separate database load step and allowing all files to be tabbed. Increased time savings were achieved as the additional stages were implemented: Total reduction in elapsed time was over 90 percent, from 30–32 hours to just 2–3 hours. The bank can now perform its routine customer management processes faster and more frequently.
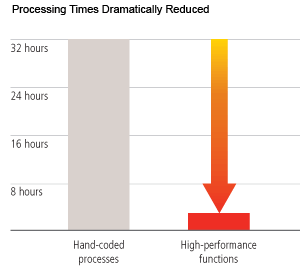
Major investment bank reduces customer management data processing time by 90%
At another leading financial institution, a specific group is responsible for processing customer data as part of a customer profitability project. The group designed a client profitability application for the project that examines customer account and product data in order to determine how much (and at what rates) the company’s products have earned for their investment clients. The application uses a Sun E10K system with 24 CPUs and 20 gigabytes of memory running Solaris 2.6.
As part of the application, the company keeps the current year’s data along with historical data from the two previous years in the operational data store (ODS). The ODS goes through about 50 billion calculations a month using Java, and then the information is stored in an Oracle 8i database. The data warehouse loads the output tables of that ODS, which contains all of the financial data. They then extract it through PL SQL into time periods that provide the financial data by customer account and product in edited numeric (EN) format.
The data from the time periods is processed using DataStage, which then outputs financial files by time periods as well as by product, customer, organization, and other types of keys. There are 36 files for regular time periods that are approximately 1 gigabyte each. There are also five summary time period files that are approximately 1.8 gigabytes each. The company then needs to create aggregates and order the data. The group responsible for the application found that DataStage’s aggregation and ordering features did not provide the performance and functionality that they needed. With DataStage alone, the process was taking 72 hours.
To improve this situation, the company selected high-performance functions to carry out the aggregates and ordering. Once the aggregates are complete, the database is brought down. The database administrator runs several statistics with the aggregated files and other DataStage files. The data is then loaded into the data warehouse and different divisions from around the world query the information using Oracle Reports and Oracle Discoverer. When they run the ETL process with the high-performance technology, the old data is still up, so they’re able to perform queries against the processor while running their ETL process. They were able to reduce the elapsed time to just 48 hours—an improvement of 33 percent.
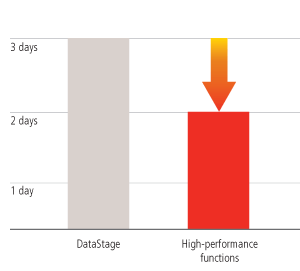
Leading financial institution cuts processing time for client profitability application by 33%
Conclusion
These are just two examples of the wide range of benefits that companies, and banking enterprises in particular, can reap from using high-performance joins, aggregates, date/time, arithmetic, and user-defined functions—and they show that using high-level functions really adds up to success.
This article originally appeared in the issue of .