LESSON - Company Directory Information and Customer Records: The Schibsted Case
By Per Anders Waaler, Senior Software Architect, and Davor Sutija, Vice President, Strategic Market Development, FAST
Introduction
All companies of a certain size or complexity face the same challenge: Vital information about the business is stored in multiple locations and in different formats. This goes for customer data as well as product data. Getting that single version of the truth about particular customer earnings or product groups becomes quite an effort. Thus enters the data warehouse.
Data warehouses, however, do not solve one challenge: that of merging data from disparate sources without common keys. Customer data is typically stored in several systems: CRM, ERP, call centers, and so on. For a company that has recently undergone a merger or acquisition, the challenge only increases.
Schibsted Search and Sesam.no
Imagine the challenges involved in being an Internet directory provider. In Norway, the base for Schibsted, a large publishing company, there are more than 20 different providers of subscription services. All telecommunications operators are obligated by law in this particular market to deliver at their own cost a list of subscribers to third parties that request such information. This legal requirement, however, does not mention nor guarantee data quality. As a publishing company, all such telecom record sources for Schibsted were external. Because of this, Sesam.no, Schibsted’s online local search and yellow pages/white pages service, probably faced even more challenges than most in merging their databases.
Schibsted Search’s goal was to present on the Web (at Sesam.no) all listings for a given company or person in a single GUI block, combining and cleansing multiple records. But even when the underlying telecom providers had the correct names for their subscribers, abbreviations and contractions abounded. For example, our own company, officially registered as Fast Search & Transfer, does business under the trade name FAST. Similar inconsistencies are especially prevalent in restaurant, retail, and other companies where a public trademark is not the name under which the company was registered.
By using multiple secondary and tertiary data fields, such as addresses and phone numbers, the link between the trade name and the corporate identity can be established. In addition, spelling errors and variations in word order that occur during data entry in call centers or online can be corrected automatically before publication using analogous tools.
The answer to our data quality issues, not only in data warehousing, but in all other aspects, is to build solutions using new tools such as the FAST Data Cleansing Solution to solve that issue. Regular database and programming logic could not do it for us.
Mikal Rohde, Schibsted Search
The Solution
Schibsted had already standardized on FAST as their search platform on the end user side of the Web, offloading database technologies that could not cope with the increasing traffic and ad hoc query load that an online enterprise generates, both in the number of users and the query complexity.
When we told Schibsted that they could also use the same technology for data cleansing, they were intrigued. As part of the FAST Data Cleansing Solution, adapters expose the FAST search engine as a database within leading ETL tools such as BusinessObjects Data Integrator and Informatica (when the complexity of the source data requires such a tool). The solution also includes embedded tools that can access popular RDBMS systems directly. In addition, FAST Data Cleansing can be called through custom APIs from any Java-enabled tool (TIBCO, webMethods, MQSeries, Oracle, and so on).
With this solution in place, we populated the FAST index from an arbitrarily large set of data sources, both structured and unstructured. Schibsted was interested in matching relevant directory listings to news stories and products using FAST’s unique relevancy ranking tools.
The steps in the cleansing operation are straightforward: a data source is first indexed in FAST, and then additional records/sources are matched one-to-many using lookups in the FAST index. This process not only executes strict matches obtained by running queries against a database, but more broadly, uses various fuzzy matching algorithms. This approach, which reduces words to their core and then matches all forms of that core word, delivers comparative results ranked according to relevance and user-defined rule sets. All of this can be done easily within an ETL tool framework, using the adapter or specialized cleansing GUIs.
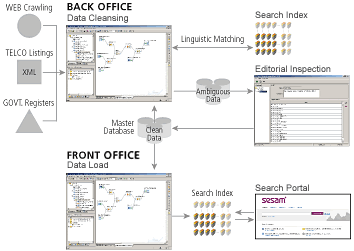
Data Cleansing Operation
- Read sources
- Track source changes
- Cleanse new/changed data against master
- Store result in database
- Allow for manual inspection GUI for unclear matches
- Update master and searchable apps with cleansed info
Different Scenarios
There are two basic scenarios that organizations face when attempting to merge data from multiple sources. In the first scenario, there is a master to cleanse against. This is easiest, but not the most common. In this scenario, we populate the FAST index with the master, and then cleanse other sources against that master, expecting to get a clear candidate for matching.
Scenario two is more typical. Here, there is no clear master, but instead a group of sources (such as a set of customer databases) that you want to cleanse against each other. The purpose is to find the same entity across disparate sources. In this scenario, we populate the master with one of the databases (chosen arbitrarily) and then cleanse that same set against itself to eliminate duplicates. Once any duplicates are removed, the cleansed set of database records acts as a master for further cleansing against the other repositories.
Cleansing Company Information
A typical scenario at Sesam.no was the cleansing of company information. This was accomplished using scenario one as described above. Since Norway provides a full listing and updates of all registered companies, this list can be used as the master to cleanse against. In the Oslo region alone, a metropolitan area of one million people, there are some 60,000 registered companies. Cleansing in most cases is done on a combination of company name, street, zip code, and municipality.
Take a look at the sample case described below. With a potential of 60,000 companies, given a misspelled company name and the city, we are able to find the correct entity. The solution handles other typical quality issues equally well, such as words switching place (first/last name versus last/first name), synonyms, and lemmatization (recognition and matching of different grammatical forms).
Sample case
Company name: beWise as (this is actually a misspelled version of bWise as)
Street: Not provided
Zip: Not provided
City: Oslo
Having populated the master index with all the 60,000 companies in Oslo,the (partial) result we get back as a candidate list using the fuzzy matching is:
| RANK |
Company |
Street |
Zip |
City |
Cleansed |
| 1 |
BWISE AS |
RADHUSGATA 9 |
151 |
OSLO |
1 |
| 2 |
STREETWISE AS |
LOKKEVEIEN 5 |
253 |
OSLO |
0 |
| 3 |
MACWISE AS |
ULLERNCHAUSSEEN 119 |
284 |
OSLO |
0 |
The cleansed flag is set based on thresholds given to the fuzzy lookup function.
When Schibsted and Sesam.no were awarded the Norwegian Data Warehouse Award for 2006, Mikal Rohde, CEO of Schibsted Search, said: “The answer to our data quality issues, not only in data warehousing, but in all other aspects, is to build solutions using new tools such as the FAST Data Cleansing Solution to solve that issue. Regular database and programming logic could not do it for us.”
The jury of the Data Warehouse Conference, hosted by Confex Norway, stated in their evaluation that the differentiating factor for the winning entry was their solution to the problem of data quality, which allowed their data warehouse to drive their entire online business.
This article originally appeared in the issue of .