Data Integration Architecture: What It Does, Where It’s Going, and Why You Should Care
By Philip Russom
To a lot of people, the term data integration architecture sounds like an oxymoron. That’s because they don’t think that data integration has its own architecture. For example, a few data warehouse professionals cling to practices of the 1990s, when data integration was subsumed into the larger data warehouse architecture. Today, many data integration specialists still build one independent interface at a time, a poor practice that’s inherently anti-architectural. And a common misconception is that using a vendor product for data integration automatically assures architecture.
Here’s the dirty rotten shame of all this: If you don’t fully embrace the existence of data integration architecture, you can’t address how architecture affects data integration’s scalability, staffing, cost, and ability to support real time, master data management, SOA, and interoperability with related integration and quality tools. And all these are worth addressing.
This article makes a case for data integration architecture, to help data integration professionals design and deploy architectures that are strongly independent, future-facing, productive, scalable, and interoperable. The case is made by defining what data integration architecture does, where it’s going, and why you should care.
Complexity is the main reason why data integration needs architecture.
This article focuses on the available architectures for relatively complex data integration implementations. In these cases, data integration effects a flow of data from diverse source systems (like operational applications for ERP, CRM, and supply chain, where most enterprise data originates) through multiple transformations of the data to get it ready for loading into diverse target systems (like data warehouses, customer data hubs, and product catalogs). Heterogeneity is the norm for both data sources and targets, since these are various types of applications, database brands, file types, and so on. All these have different data models, so the data must be transformed in the middle of the process, and the transforms, themselves, vary widely. Then there are the interfaces that connect these pieces, which are equally diverse. And the data doesn’t flow uninterrupted or in a straight line, so you need data staging areas. Simply put, that’s a ton of complex and diverse stuff that you have to organize into a data integration solution.
Goals of Data Integration Architecture
Here’s where data integration architecture comes in. It imposes order on the chaos of complexity to achieve certain goals:
Architectural patterns as development standards. Most components of a data integration solution fall into one of three broad categories: servers, interfaces, and data transformations. With that in mind, we can venture a basic definition:
Data integration architecture is simply the pattern made when servers relate through interfaces.
The point of an architectural pattern is to provide a holistic view of both infrastructure and the implementations built atop it, so that people can wrap their heads around these and have a common vision for collaboration. Also, when you inherit someone else’s work, you get up to speed faster when they’ve followed development standards and established patterns. Well-run organizations have development standards, and architectural patterns should be among those.
Simplicity for reuse and consistency. As development standards and architectural patterns are applied to multiple data integration projects, the result is simplicity (at least, compared to ad hoc methods), which fosters the reuse of data integration development artifacts (like jobs, routines, data transforms, interfaces), which in turn increases consistency in the handling of data.
Harmony between common infrastructure and individual solutions. For a solution (like a data flow or a project) to be organized in a preferred architecture, the infrastructure (especially the data integration production server and the interfaces it supports) must enable that architecture.
Hub-and-spoke is the preferred architecture for most integration solutions.
The most common architectural pattern for data integration is hub-and-spoke architecture. In this architecture, inter-server communication and data transfer pass through a central hub, where an integration server manages communications and performs data transformations. When data integration solutions are built atop a vendor’s tool, the server at the hub is usually a vendor’s data integration server. With home-grown solutions, the server at the hub may be a database management system or a collection of handcoded routines. Hybrid systems combine these.
Most integration technologies are today deployed in a hub-andspoke architecture. This is true of the form of data integration known as extract, transform, and load (ETL). Variations of ETL—like TEL and ELT—may or may not have a recognizable hub. But it’s not just ETL. For example, hubs are common in deployments of enterprise information integration (EII). Replication usually entails direct interfaces between databases, without a hub; but high-end replication tools support a control server or other device that acts as a hub. Enterprise application integration (EAI) tools depend on message queue management, and the queue is usually supported by an integration server through which messages are managed.
Benefits of hub-and-spoke architecture
It provides a flexible architectural pattern. The hub-and-spoke concept is easy to understand and work with, yet can be expressed in infinite variations.
It fosters reuse. You typically develop an interface—called a spoke—from the hub to a given system and then reuse that interface as more systems need to communicate with the first one.
It reduces the number of interfaces. The practice of spoke reuse fostered by hub-and-spoke architectures dramatically reduces the number of interfaces you need to build and maintain.
To prove this last point, let’s compare hub-and-spoke architecture to its nemesis: point-to-point architecture. This is where IT systems communicate directly without a hub or other remediation. Most interfaces in point-to-point architecture are unique to a specific pair of IT systems and so are not easily reused. Also, point-to-point architecture is often developed through hand coding, which is not productive, thereby raising payroll costs. But the real problem arises when you push point-to-point architecture to an extreme. If you connect every IT system to all others in a collection of n systems, you end up with n!-n interfaces—and that’s a lot of interfaces!
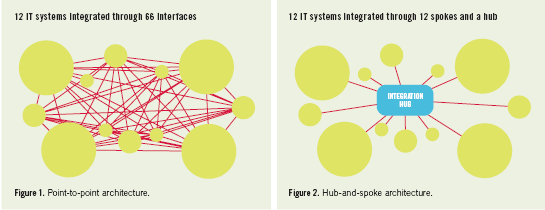
For example, Figure 1 illustrates how a collection of 12 IT systems is fully integrated via 66 individual interfaces (12!-12=66). Users often describe the resulting architectural pattern disparagingly as “spaghetti.” However, in Figure 2 we see that the same 12 IT systems can be fully integrated through 12 reusable spokes and a hub. The resulting architectural pattern is simple to design and maintain, due to the reduced number of interfaces. This shows how the choice of an integration architecture can impact development standards, reuse, developer productivity and related costs, and the number of interfaces to design and maintain.
Pure architecture is rare; distributed hybrids are common.
The hub-and-spoke concept is a handy symmetrical abstraction, but in the real world only the simplest of integration solutions comply with it 100%.
Point-to-point interfaces can complement hub-and-spoke architecture. Even when integration infrastructure has a hub through which most interfaces communicate, a few point-to-point interfaces that circumvent the hub can be useful. Such warts on the architecture make sense when you just need to copy data from point A to point B, and you don’t need the hub’s scheduling or data transformation capabilities. Also, a direct interface may be faster than going through the hub. After a bit of evolution, most architectures end up hybrids like this, anyway.
An integration server may become a performance bottleneck. If you keep the hub-and-spoke architecture pure with a data integration implementation, you force all data flows and data processing through a single server. (See Figure 3.) When large data volumes and/or highly complex transformations are involved, it’s common to avoid a purely centralized data integration architecture in favor of a distributed one that distributes data processing across more servers to assist with scalability. (See Figure 4.)
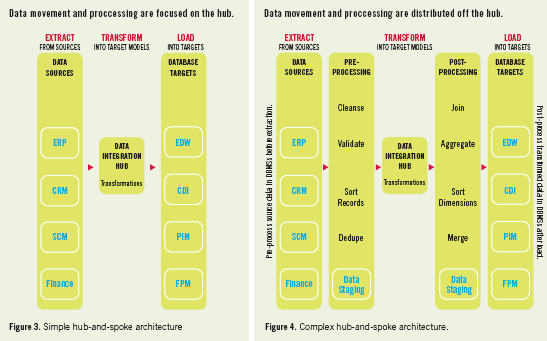
Source and target databases may take an active role in a distributed architecture. We think of source and target systems as passively handing data to a data integration implementation and receiving data from it. Yet, source and target systems usually include a database management system (DBMS) that’s capable of handling some of the data processing. When a DBMS has available capacity, it makes sense to put it to work pre-processing data before it leaves the source or post-processing data after loading it into a target (which is typical of ELT configurations). Either way, this reduces the load on the data integration server at the hub of the architecture. (See the far-left and far-right sides of Figure 4.)
A distributed data integration architecture may include multiple integration technologies. Besides the role of DBMSs just mentioned, distributed architectures often depend on data quality tools, sort tools, and hand-coded routines to pre- or post-process data, to perform unique operations not suited to the integration hub, or to simply offload the hub.
Scheduling time on the hub is a challenge. For example, a source system may have an optimal window for presenting data that happens to be at a moment when the integration server is engaged. Or you may need to transfer data via flat files. In these cases, the data integration architecture includes one or more data staging areas. This is where data is parked until another process picks it up; data may sit passively or be actively processed before entering the hub or after exiting it.
Data integration architecture is not the same as data warehouse architecture.
The simplified architecture shown in Figure 3 includes an enterprise data warehouse (EDW) as an outbound spoke from a data integration hub. The reality is that an EDW is itself a complex environment that includes many components that need an organizing architecture. For decades, data warehouse professionals have fought a religious war over data warehouse architectures. We all agree that a data warehouse needs an architecture, although we can’t agree which one!
Without taking a side in the EDW architecture debate, let’s note that most recent definitions of data warehouse architecture focus on data models and how they’re expressed in appropriate types of databases. Sometimes the resulting architecture has a hub, sometimes not. That’s different from data integration’s architectural focus on interfaces and data transformations, which almost always hinge on a hub. Obviously, data integration architecture must feed data into data warehouse architecture, so they overlap. Yet, the two have different foci and patterns and so should be considered separate.
Data integration is an autonomous practice, which needs its own architecture.
Many of the best practices and technologies of data integration originated in data warehousing in the early 1990s, and data integration continues to be a meaningful and growing segment within data warehousing. For these reasons, some data warehouse professionals continue to think of data integration architecture as a subset of data warehouse architecture. Yet, by the turn of the current century, data integration had begun its journey into independence and today should be considered an autonomous practice. Two recent trends corroborate this independence.
Operational data integration. This involves the migration, consolidation, synchronization, and upgrade of operational databases and applications. In other words, it’s a data integration practice that doesn’t involve data warehousing or business intelligence, the way that analytic data integration does. According to TDWI Research, both operational data integration and analytic data integration are growing, yet the operational practice is growing faster than the analytic one.
Data integration’s life outside data warehousing has corroborated its independence in recent years but also forced changes to how it’s funded and staffed. A struggle many organizations face is the fact that data integration specialists are usually members of a data warehouse team, which has specific funding and staffing. Pulling them away from analytic data integration work so they can do operational data integration work creates organizational conflicts.
Data integration competency centers. To avoid conflict, to assure that all work gets done, and to avoid redundant teams and infrastructure, many organizations have founded a data integration competency center. A competency center is a neutral organization that provides centralized shared services in support of a range of business initiatives and technical implementations—not just data warehousing. Furthermore, relative to architecture, a data integration competency center establishes development standards and architectural patterns; it encourages reuse; and it owns enterprise data integration infrastructure (which influences architecture). The rise of an independent team—as seen in competency centers—is further proof of data integration’s autonomy.
Data integration architecture is set to go service-oriented.
Data integration architecture is heading out on the leading edge by incorporating service-oriented architecture (SOA). Note that SOA won’t replace current hub-based architectures for data integration. Hubs will remain but be extended by services. The goal is to provide the ultimate spoke, namely the data integration service. For that to happen, the integration server at the hub has to support a data integration service registry.
The benefits of SOA to data integration architecture are enormous. After all, data integration is all about interfaces to heterogeneous systems coupled with sophisticated data transformation at the hub. SOA gives data integration a wider range of interface possibilities, and many of these allow it to participate in composite application architectures. For example, a data integration service can bring integrated data into a wide variety of applications, especially those for operational BI, embedded reporting, performance management, and dashboards. Depending on several factors, a data integration service may integrate data on demand for time-sensitive business practices like just-in-time inventory or customer service.
A data integration service is a generalized interface, so a data integration tool can call and be called in a reusable fashion from data quality or application integration tools, achieving greater interoperability with these. Progressively, data integration infrastructure is an enabler for data management practices like master data management (MDM), customer data integration (CDI), and product information management (PIM). A data integration service could provide functions for these that are easily embedded in various operational or analytic applications. As you can see, the architectural variations are increasing—in a positive way—as data integration embraces services.
Recommendations
Recognize that data integration architecture exists. Although it overlaps with data warehousing architecture and interacts with the entire business intelligence technology stack, data integration architecture is an autonomous structure demanded of an autonomous practice.
Give the autonomous practice of data integration autonomous staffing. Instead of scavenging the data integration specialists from your data warehouse team, consider establishing a data integration competency center.
Adopt hub-and-spoke architecture for most data integration implementations. After all, the hub reduces the number of interfaces and provides a pattern that everyone can understand and be productive with. And hub-and-spoke architecture is conducive with other worthy goals, like reuse, productivity, collaboration, and consistent development standards.
Don’t be doctrinaire about hub-and-spoke architecture. Otherwise, you’ll heap a heavy workload on the hub. To accommodate large data volumes and/or complex transformational processing, distribute the workload beyond the hub through various types of pre-processing and post-processing.
Embrace services. The data integration service extends existing hub-and-spoke architectures with new interfaces, so data integration hubs can embed functions into a wide range of traditional and composite application architectures.
This article originally appeared in the issue of .