BI Search and Text Analytics
- By Philip Russom, Ph.D.
- May 9, 2007
New Additions to the BI Technology Stack
By Philip Russom
Quantifying the Data Continuum
Before drilling into BI search and text analytics, we need to review the spectrum of available data sources. After all, the “data continuum” has direct import on the scope of reports and other documents indexed by search or mined by text analytics.
The data continuum breaks into three broad areas.
- Structured data. At one extreme of the data continuum, structured data is commonly found in database management systems (DBMSs) of various types.
- Unstructured data. The other extreme includes documents of mostly natural-language text, like word-processing files, e-mail, and text fields from databases or applications.
- Semi-structured data. The area between the two extremes includes semi-structured data in spreadsheets, flat files in record format, RSS feeds, and XML documents. Many of these media are used with cross-enterprise data-exchange standards like ACORD, EDI, HL7, NACHA, and SWIFT.
Some data sources are hybrids that are hard to categorize. Despite the three broad types of data sources, the continuum includes sources that can manage both structured and unstructured data. For example, a row in a database table has a well-defined record structure that defines fields of mostly numeric data types. Yet, the same record may also have fields that are character data types, like text fields or binary large objects (BLOBs). Likewise, a report may contain structured data (or a query that fetches structured data), as well as report metadata and text in headings that can be searched. RSS feeds are especially problematic, since they can transport a variety of information, ranging from prose (unstructured) to transactions (semi-structured).
In recent years, market research conducted by various software vendors and consulting firms has attempted to quantify the relative percentage split between structured and unstructured data in the average user organization. Most estimates name unstructured data the unqualified winner at 80–85%, leaving structured data in a distant second place at 15–20%.
However, TDWI Research finds that unstructured data is not as overwhelming in volume as previously thought. In an Internet survey conducted in late 2006, TDWI asked each respondent to estimate “the approximate percentages for structured, semi-structured, and unstructured data across your entire organization.” (See the top bar in Figure 1.) Averaging the responses to the survey puts structured data in first place at 47%, trailed by unstructured (31%) and semi-structured data (22%). Even if we fold semi-structured data into the unstructured data category, the sum (53%) falls far short of the 80–85% mark claimed by other research organizations. The discrepancy is probably due to the fact that TDWI surveyed data management professionals who deal mostly with structured data and rarely with unstructured data. All survey populations have a bias, as this one does from daily exposure to structured data. Yet, the message from TDWI’s survey is that unstructured data is not as voluminous as some claim.
Unstructured and Structured Data in Warehouses Today
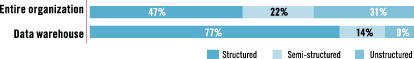
Figure 1. Little unstructured or semi-structured data makes its way into data warehouses today. Based on 370 respondents.
Now that we have a new and different quantification of the unstructured segment of the data continuum, what should we do about it? We should all pare down our claims about unstructured data volumes, but we should not change our conclusions about what needs to be done. In other words, regardless of how the numbers add up, we all know that the average user organization has a mass of textual information that BI and DW technologies and business processes are ignoring. And this needs to change.
Why can’t data warehousing professionals go on ignoring unstructured data? Among the many good reasons, two stand out:
- The view of corporate performance seen from a data warehouse is incomplete unless it represents (in a structured way) facts discovered in unstructured and semi-structured data.
- BI platforms today commonly manage thousands of reports, and techniques borrowed from unstructured data management (i.e., search) can make reports a lot more accessible.
To quantify the situation, TDWI asked each survey respondent to estimate “the approximate percentages for structured, semi-structured, and unstructured data feeding into your organization’s data warehouse or BI processes.” (See the bottom bar in Figure 1.) The survey responses reveal that structured data accounts for a whopping 77% of data in the average data warehouse or other BI data store, darkly overshadowing semi-structured (14%) and unstructured data (9%). Indeed, little data originating in unstructured or semi-structured form makes its way into data warehouses today, despite large quantities of it elsewhere in an organization. (Figure 1 compares these.)
The dearth of unstructured data in the warehouse isn’t surprising, considering that almost all best practices in data warehouse modeling demand structured data. Likewise, we analyze and report off of data warehouse data using tools that see data only through the eyes of SQL, which in turn demands data in relational or multidimensional structures. As we’ll see in detail later in this report, you have to impose structure on unstructured data before it’s usable with a BI/DW technology stack.
New Data Warehouse Sources from the Data Continuum
As we’ve seen, the data continuum divides into three broad segments for structured, semi-structured, and unstructured data. In turn, each of these segments is populated by various types of systems, files, and documents that can serve as data sources for a data warehouse or other BI solution. These range from flat files, to databases, to XML documents, to e-mail, and so on.
Which Types of Data and Source Systems Feed Your Data Warehouse?
(Select all that apply for both today and in three years.)
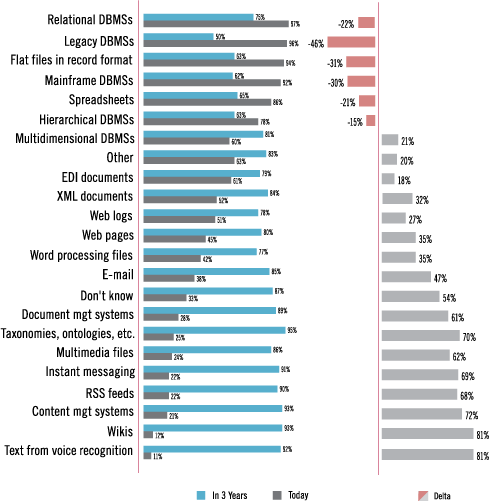
Figure 2. Based on 370 respondents.
To understand which of these are feeding data into data warehouses today—and in the near future—TDWI asked, “Which types of data and source systems feed your data warehouse?” Survey respondents selected those in use today, as well as those they anticipate using in three years. Figure 2 charts survey responses for both today and the future; it also calculates the expected rate of change (or “delta”). Judging by users’ responses to this question, the kinds of data sources for the average data warehouse will change dramatically in the next few years:
- Unstructured data sources will soon be more common for data warehouse feeds. The survey predicts the greatest increases with technologies that convey natural language information in text (aka unstructured data), like voice recognition (up 81% in three years), wikis (81%), content management systems (72%), taxonomies (70%), instant messaging (69%), and RSS feeds (68%). Admittedly, some of these show a high rate of change because they’re starting from almost nothing, as with voice recognition and wikis (11% and 12% today).
- Semi-structured data sources will increase moderately. This includes stalwarts like XML and EDI documents (up 32% and 18% in three years, respectively). The new kid on the block is the RSS feed, which contains both semi- and unstructured data. Most RSS feeds transport prose (unstructured data as text), but are beginning to carry transactions as semi-structured data in markup documents. Either way, 22% of survey respondents claim that their data warehouse accepts RSS feeds today, and 90% anticipate integrating data from RSS feeds in three years. This makes sense, because RSS feeds operate in near real time over the Web, and many organizations are looking for faster and broader ways to deliver alerts, time-sensitive data, and transactions.
- Miscellaneous unstructured sources will increase moderately, too. These are mostly files containing text, like e-mail (up 47% in three years), word-processing files (35%), Web pages (35%), and Web logs (27%). Their increase will be moderate because they’re already established.
- Some sources of structured data may decline, but the category will keep its hegemony. Survey respondents anticipate reducing data extraction from various older types of database management systems (DBMSs), namely those that are hierarchical (-15% in three years), mainframe (-30%), legacy (-46%), and flat files in record format (-31%). Indeed, these are legacy platforms that are ripe for retirement or migration. But survey respondents also anticipate extracting less data from spreadsheets (-21% in three years) and relational DBMSs (-22%). While the decline of legacy databases as data warehouse sources seems plausible, TDWI Research is deeply skeptical about the decline in relational databases and spreadsheets claimed by survey respondents. Since these are so deeply ingrained in BI and in IT in general—and are spawning new instances constantly—their decline seems very unlikely.
The general trend—toward more unstructured data sources. Survey responses show that priorities along the data continuum will soon shift relative to data warehouse sources, with some data sources declining and others rising. Although respondents may have been overly optimistic about the rate of change they will embrace, the survey clearly signals a shift toward using more semi-structured and—especially—unstructured data sources. The trend is plotted conceptually in Figure 3, and the shift can be visualized as an increase in the types of data sources plotted in the middle or on the right side of the graph. Another way to see it is that the wide majority of data warehouse feeds today come from the left end of the graph. These won’t go away, but instead will be joined incrementally by more data sources toward the right end.
Data and Source Types Plotted on the Data Continuum
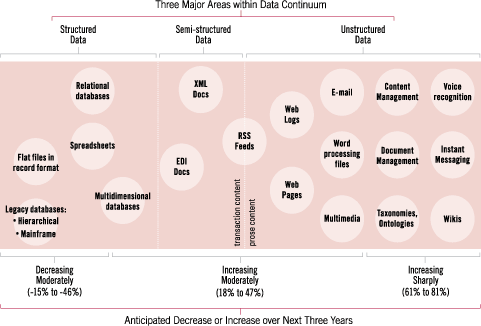
Figure 3. The data clearly signals a shift toward using more semi-structured and–especially–unstructured data sources.
Ramifications of Increasing Unstructured Data Sources
The evolving list of data sources means changes for DW/BI practices. Data warehousing professionals should be aware of these and prepare for them:
- Unstructured and semi-structured data must be transformed into structured data. Note that sources of unstructured and semi-structured data will be increasingly tapped for data warehousing, but that doesn’t mean that much of this raw data will actually go into a data warehouse. In most cases, this source data will need to be parsed for entity extraction or otherwise transformed into structures that are meaningful in a data warehouse or to a reporting tool.
- Data integration will need to change substantially. The wide majority of data integration routines for data warehousing today interface with structured data sources and transform the data accordingly before loading it into the data warehouse. Assuming that unstructured sources will increase, data integration for the data warehouse will need to reinvent itself in the next few years.
- Data modeling could face a similar transformation, but not as extreme. A few data models in data warehouses will require adjustments to accommodate the structured data coming from unstructured data sources. Since the data is usually structured by the time it arrives in the data warehouse environment, adjustments should be slight. Similar adjustments are required when users want to copy unstructured data into a warehouse.
- Training—and learning—are in order. Data warehousing professionals currently have little or no experience with unstructured or semi-structured data sources. Likewise, experience is rare with search and text analytic tools. So additional training is needed, and—due to minimal experience—the learning curve will be long and flat.
Philip Russom is the senior manager of research and services at TDWI, where he oversees many of TDWI’s research-oriented publications, services, and events. He can be reached at [email protected].
This article was excerpted from the full, 32-page report by the same name. You can download this and other TDWI Research free of charge at http://tdwi.org/research/list/index.aspx.
The report was sponsored by Business Objects, Cognos, Endeca, FAST, Hyperion Solutions Corporation, and Sybase, Inc.
Next
Previous
Back to Table of Contents
About the Author
Philip Russom, Ph.D., is senior director of TDWI Research for data management and is a well-known figure in data warehousing, integration, and quality, having published over 600 research reports, magazine articles, opinion columns, and speeches over a 20-year period. Before joining TDWI in 2005, Russom was an industry analyst covering data management at Forrester Research and Giga Information Group. He also ran his own business as an independent industry analyst and consultant, was a contributing editor with leading IT magazines, and a product manager at database vendors. His Ph.D. is from Yale. You can reach him by email ([email protected]), on Twitter (twitter.com/prussom), and on LinkedIn (linkedin.com/in/philiprussom).