Q&A: How True Virtualization Addresses Data Integration Issues
Techniques and technologies around data integration are changing in response to real-time needs, explains Informatica's director of product marketing Ash Parikh, and data virtualization has become more important. In this interview, he explains virtualization issues such as how virtualization has evolved as a stronger solution than federation, and how MDM fits into the virtualization picture. Parikh, who speaks often on the topics of service-oriented architecture and distributed computing, also offers some best practices for data virtualization.
At Informatica, Parikh is responsible for driving the company's product strategy around real-time data integration and SOA. He has over 17 years of industry experience in product innovation and strategy at companies including PeopleSoft, BEA Systems, and Sun Microsystems.
BI This Week: What changes are taking place in data integration, especially as it pertains to real-time BI?
Ash Parikh: Today, IT is faced with some serious challenges. Businesses need new data much faster than IT can deliver. The first is that the data the business needs is often not in a data warehouse or a single application. Instead, it's everywhere -- across the enterprise, beyond the firewall, and in the cloud. Of late, we are also seeing the need to tap into and make sense of vast amounts of data from new and disparate sources, such as social network data, weblogs, and device and sensor data, as well as scientific data such as genomic and pharmaceutical data.
The second challenge is that there is significant back-and-forth between business and IT, which simply takes too long. The case for more agile BI has been well made in a 2010 TDWI article, Making the Case for Agile Business Intelligence, by Stephen Swoyer. The article references a report and survey from Forrester Research: Agile BI: Best Practices for Breaking Through the BI Backlog.
According to the Forester survey, 66 percent of BI requirements change on a daily to monthly basis. Also, 71 percent of respondents said they have to ask data analysts to create custom reports for them, and 36 percent of custom report requests require a custom cube or data mart to answer the request. Furthermore, 77 percent of respondents said it takes days or even months to get BI requests fulfilled.
Clearly, if businesses are to benefit from BI, the underlying data integration process needs to be optimized wherever possible. We need to let the business own the data and define the rules while IT somehow retains control. We must also look for ways deliver better business-IT collaboration in order to reduce waste and minimize delays throughout the process. Only then will we be able to successfully and consistently deliver data when and how it is needed by the business for operational reporting.
If we turn to data virtualization as a solution, how does it compare to data federation? In what cases is virtualization a better choice, and why?
I'd like to refer to a very good TDWI blog on this subject by Wayne Eckerson, The Evolution of Data Federation. Data federation has been around for a long time but has failed to become deeply entrenched in enterprise-grade data architectures. That's because it does one thing and only one thing well -- federate data from several heterogeneous data sources in real time without physical data movement.
However, in its simplicity, data federation overlooks the complexity of enterprise-grade data integration requirements. It typically offers SQL- or XQuery-based data transformations. That leaves a gaping void because enterprise-grade deployments often require rich ETL-like complex transformations.
Data federation architectures may also call out to external Web services for things like simple address standardization. However, when sophisticated data quality transformations are called for, post-processing and staging are required, so that any time advantage gained is then lost. Also, there is no way to physically materialize the virtual view if it's needed at a later date.
Finally, as the blog points out, data federation was never designed to address the fundamental need for optimizing the data integration process. Instead, it is often too developer-centric, failing to involve the business user early and often in the data integration process, which can help minimize delays. Simply putting old wine in a new bottle has not helped either, as Eckerson's commentary states: "Today, data federation vendors prefer the label of data virtualization, capitalizing on the popularity of hardware virtualization in corporate data centers and the cloud."
The real question to be asked is this, Eckerson says: "What if you could get all the advantages of both data federation and data integration in a single toolset?" The answer: "If you could have your cake and eat it, too, you might be able to apply ETL and data quality transformations to real-time data obtained through federation tools." This would be "true" data virtualization.
How does true data virtualization complement and work with an existing data warehouse?
Consider the following scenario. The executive management team at a large electronics retail chain needs to report to the board about a sudden increase in customer support complaints. Rapid investigation is required; to understand the situation, new data needs to be quickly added to a report to better analyze call-center performance. The desired report requires CUSTOMER data in the data warehouse to be instantly combined with SUPPORT data in operational systems as well as CUSTOMER SENTIMENT data in social media networks.
In this scenario, data virtualization quickly augments the CUSTOMER data in the data warehouse by delivering a virtual view on demand across these multiple heterogeneous data sources. There is no physical data movement involved. Analysts, IT architects, and developers analyze and profile the federated data, rapidly uncovering any issues. A full palate of data quality transformations, such as matching, cleansing, and enrichment, as well as masking, are then applied to the federated data in flight, in real time, without post-processing or staging.
The business users are involved early and throughout the process in defining rules. That means data-related service-level agreements (SLAs) around data access, freshness, quality, retention, and privacy are validated and met easily and quickly. The report then queries the new virtual view that combines all the relevant data on demand.
The report is delivered without unnecessary delays and the results are validated up front, thus eliminating any rework. Months later, the virtual view is physically persisted into the data warehouse for compliance purposes.
The business got the data it wanted when it was needed and IT retained control of the process. True data virtualization can thus hide and handle the complexity involved in quickly augmenting the data warehouse with new data, delivering more agile BI.
How does master data management (MDM) work with data virtualization?
MDM, by definition, is about master data -- the "golden record" of data, if you will. That means data such as CUSTOMER, PRODUCT, or ORDER -- data that is not meant to change. However, when a user wants all data related to CUSTOMER, a critical piece that may be missing is transactional data, which is not readily available in the MDM hub.
This transactional data might consist of records of the customer's interactions, such as Web site visits, call center episodes, and other transactional data. If a customer service representative is to truly serve the customer on the other end of the line, then having easy and immediate access to this "complete view" of the customer is paramount.
In his blog Whatever Happened to EII, Rob Karel of Forrester Research notes that "architects designing solutions to manage complex enterprise content management (ECM) and master data management (MDM) strategies also consider data federation as a legitimate means to bridge information silos." As in the case of data warehouse augmentation, data virtualization provides a superior approach to simple, traditional data federation for quickly combining master data and transactional data and delivering the complete view of the customer. Stakeholders can quickly collaborate and agree on data definitions and their respective attributes. Business and IT can also iteratively assess and improve data quality on the fly. The resulting complete view, delivered as a virtual view, can be accessed in any way, by any consuming application.
What are some best practices for data virtualization in the industry?
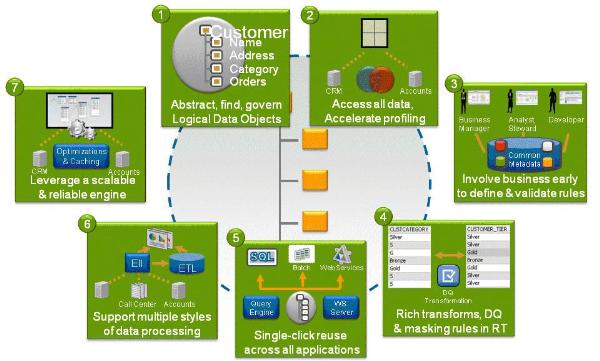
True data virtualization should be built from the ground up, ideally on a comprehensive data integration platform that truly understands the complexity of data warehouse architectures. It must be based on lean integration principles so that the data integration process can be optimized to reduce delays and minimize waste. It must support a model-driven and service-oriented approach for defining and delivering data services that can be fully reused for any consuming application and across any project, without any rework. That means there must be no re-building of data integration logic and no re-deployment.
Further, true data virtualization must provide graphical, role-based tools that share common metadata. It must be able to profile and analyze federated data without the need for post-processing or staging, and it must ensure early and on-going business user involvement and enable analysts and architects to define and validate rules around the data. These rules must be sophisticated -- rich ETL-like data transformations, all forms of data quality, data privacy, data retention, data freshness -- and must be able to be enforced on the fly to the federated data.
Needless to say, performance is paramount; data virtualization must provide high-performance connectivity to all data, a powerful query engine, a Web services server, caching, and all the various optimizations one would expect from a data federation server. It must also support physical materialization of virtual views to a persistent data store. Finally, true data virtualization must be flexible enough to support use cases across BI, MDM, and SOA (service-oriented architecture).
In summary, the graphic [Editor's note: see below] showcases the data virtualization best practices for fast and direct access, increased reuse, improved agility, and governance.
About the Author
Linda L. Briggs writes about technology in corporate, education, and government markets. She is based in San Diego.
[email protected]