 View online: tdwi.org/flashpoint
View online: tdwi.org/flashpoint





March 7, 2013
ANNOUNCEMENTS
Call for entries:
TDWI Best Practices Awards 2013
NEW TDWI E-Book:
Enhancing Your Data Warehouse: How Big Data Technologies Can Augment and Complement Your DW
NEW TDWI Checklist Reports:
Integrating Structured and Unstructured Data
Taking IT to the Next Level: Next-Generation Data Integration
CONTENTS

Operational Redesigns: How Your Data Warehouse Can Help
Making Predictive Analytics “Predictive”

Offloading Analytics: Creating a Performance-Based Data Solution

The Role of Hardware in HiPer DW
Mistake: Bad Practices in Data Naming and Definition

See what's
current in TDWI Education, Events, Webinars,
and Marketplace
Operational Redesigns: How Your
Data Warehouse Can Help
Patty Haines
Chimney Rock Information Solutions
Topics:
Business Intelligence, Data Management, Data Warehousing
Imagine this scenario. It’s time to retire your operational systems. Your enterprise has been chugging along with outdated systems that have been patched and re-patched so many times over the years that it is difficult to recognize them anymore, and it’s no longer easy to determine where the next patches should be made. Plans for redesigning the operational systems that are an integral part of your organization’s operational environment are in the works.
To increase the success and reduce the time required for the operational systems’ redesign, use your data warehouse for the project’s first steps. Whether fully or partially implemented (or not yet in existence), your data warehouse is an excellent place to begin the design of the new operational systems.
Your data warehouse contains valuable information about your organization and how your data is used. If your data warehouse does not yet exist, many tasks required to design and build it are valuable precursor tasks to the operational systems redesign project.
Several data warehouse tasks are key to support your operational systems redesign project.
1. Understand the data
To define and clarify the data required by the new operational systems, you must first understand your data: how it is used within your operational systems, what the data means, the quality of the data, and how it is shared and integrated between the multiple operational systems. Many data warehouse design and implementation tasks can be used to better understand data, including reviewing data descriptions, profiling data, and mapping data from the source operational systems to a generic target data model.
Data descriptions can usually be found within the operational systems’ data models. Because they are part of the technical environment, these definitions may have been created by the IT support team and may reflect a technical view of the data, but will provide an excellent start to understanding the data and categories of data currently used in the operational systems.
Data profiling (that is, evaluating the contents of data elements) will provide a better understanding of the data values within your data structures. This includes identifying maximum and minimum values; the percentage of blank, null, zero, and unique data values; data patterns; values that do not match the required data pattern; and data redundancy. By understanding data values in your operational systems, you can identify where data needs to be cleansed before it can be migrated into the redesigned operational systems. These tasks can be planned and completed prior to the redesign.
Data mapping helps you understand how data is used within your operational systems. Often, a piece of data has one name but is used for a purpose quite different from what its name implies, or the data has a different meaning based on the contents of other pieces of data. Data mapping consists of mapping source operational data elements to the target data model and applying transformation rules to either clean or enhance the source data in order to accurately reflect the target data element.
You can use your data warehouse to review data descriptions by reviewing metadata and the semantic and presentation layers of the data warehouse used directly by the business users. The data profiling tasks can easily be completed on the data warehouse tables using the query tool provided as the user interface to your data warehouse environment. Data mapping documents should already exist, providing definitions and rules needed to transform the operational data.
2. Identify operational system requirements
Operational requirements can be clarified and refined while your current data warehouse is being utilized by the business, or while the data warehouse is being built and data is analyzed. Business users will better understand tasks that should be part of the data warehouse/business intelligence environment, and which processes need to be part of the operational systems.
Data is integrated and consolidated from the multiple operational systems in the data warehouse, which will help identify where operational system data should be maintained and data models redesigned. Edits required to maintain quality data and drop-down values can be defined. Data required by the data warehouse from the operational systems, such as triggers and changed data indicators, can now be defined and clarified. Both structured and unstructured data can be considered as the complete set of data within your organization is analyzed.
3. Prepare the organization and team members
As the data warehouse is used and data is evaluated and grouped into categories, new support needs will be identified. Realigning team members to these new concepts and preparing teams for the larger operational systems redesign project can be completed prior to the project. Training needs can be identified and fulfilled within the newly structured organization in preparation for the redesign project.
The data governance organization can be defined, identifying data ownership and stewardship, along with their responsibilities. This will help the data governance team members be prepared to provide direction and guidance for the operational systems’ redesign.
4. Acquire tools
Tools can be reviewed and evaluated to determine the type of tools that will improve the success of the redesigned operational systems. This up-front task will help ensure tools are acquired and implemented when they are needed. This will help reduce possible delays in the redesign project to ensure the required tools are available and ready to be used in the project.
One goal of the operational systems’ redesign is to increase the effectiveness and efficiency of aligning data with business processes. This is an excellent time to leverage information for the highest business impact. There are numerous activities using your current data warehouse--or new tasks to begin building your data warehouse--that can improve the success and quality of your operational systems’ redesign. Many of these tasks relate to data: data quality, how it relates to other data, how its quality can be improved, and how it relates to business processes. The rewards will be worth the time needed to complete these preliminary tasks preparing the organization for the redesign project.
Patty Haines is founder of Chimney Rock Information Solutions, a company specializing in data warehousing and data quality. She can be reached at 303.250.3424.

Making Predictive Analytics “Predictive”
Thomas A. “Tony” Rathburn
The Modeling Agency
Topic:
Business Analytics
Much of the conversation surrounding predictive analytics tends to focus on advanced mathematics and sophisticated algorithms, as well as data-related issues--especially our current fascination with big data. Perhaps the most misunderstood aspect of predictive analytics is what makes it “predictive.”
Our analytics projects are intended to provide insights to help us understand the dynamics of the relationship between a set of conditions (our “input” or “independent” variable) and a behavior we are attempting to predict (our “output” or “dependent” variable). The key to developing a “predictive” model lies in the appropriate construction of records in training, test and validation data sets, and delivery applications.
Traditional Analytics
Traditionally, analysts build their record structures by identifying a variable of interest as the output variable in their models, and then perform a variety of techniques for the selection and transformation of candidate input variables. This work is done to prepare the data for the application of a selected algorithm to generate the formula that comprises our model.
The vast majority of the effort is focused on data extraction, data quality issues, transforming the data into a form consistent with the requirements and assumptions of the algorithm we intend to use, and ensuring that the sampled data is consistent with the current environment.
These are all important considerations. However, this literal extraction of data from the data warehouse is flawed by its time perspective of the relationship between the candidate input variables and the output variable. By constructing data sets in this manner, the relationship is between the current state of the output variable and the corresponding current state of the candidate input variables.
Analytics completed from this perspective may develop a series of complex relationships but will provide little actionable guidance and often leaves the project team in a quandary as members attempt to determine what appropriate implications can be gleaned from the completed analysis.
Completing an analytics project is akin to building a complex weather data set by capturing the current temperature, barometric pressure, wind speed, wind direction, time of day, and a variety of other candidate input variables, then looking out the window and recording whether it is sunny, raining, or snowing. Of course we can complete a weather analytics project on this data, but it generally offers little predictive capability.
The Predictive Perspective
To build a predictive model, our record must reflect the current state of the output variable and some prior state of the associated input variables. This approach is conceptually simple, but is critical in constructing our records. We collect the same data. Predictive analytics simply requires an appropriate time alignment of our output variable and our candidate input variables relative to our actual decision process.
To give your model predictive capability, we capture the current condition of the output variable we are attempting to predict, and lag our candidate input variables to their state at the time we make our predictions. From our weather example, we might capture today as being sunny and associate the values of the input variables from yesterday’s state.
This simple shift in the time relationship between the input variable component and the output variable we are attempting to predict allows our algorithms the potential to “predict” a future event from a particular point in time.
The lag we incorporate must be consistent with the time lag that the model will face in live decision making. It would be of little value to use the relationship described above when we intend to develop a prediction of the weather a week into the future. The relationship between the input variables and the output variable in our records must be appropriately lagged to reflect the decision window we will actually use in our live decision making.
Conclusion
Incorporating a predictive capability into our analytics projects is relatively simple and is recommended. In business and government, there are few examples where our preference would be to develop models of historical relationships.
The implementation of this simple strategy, however, is more complex from a data perspective. The data manipulation required to construct our records in this manner may be significant, as most of our data is not stored in this manner. Additionally, the lags required are unique to the perspective of each predictive analytics project, making it difficult for our data specialists to anticipate our needs at the enterprise level.
Acknowledging the customized needs of individual projects in the current environment of big data analytics further complicates this issue, because many organizations are faced with managing increasingly larger volumes of data and are focusing on an enterprise-level perspective of all relational characteristics.
Thomas A. “Tony” Rathburn is a senior consultant with The Modeling Agency and has over 25 years of predictive analytics development experience. Tony will present two new courses at the TDWI Chicago World Conference in May 2013.

Offloading Analytics: Creating a Performance-Based Data Solution
John Santaferraro
It’s a “big data” world and getting bigger every day. Everyone acknowledges the potential benefits of this data explosion, but the growing mountains of information can also overwhelm existing data warehouse infrastructure. Unless companies can effectively use the new data to gain greater insight, agility, and competitiveness than they could achieve with less data, big data means nothing more than increased infrastructure and storage costs--and tremendous disappointment.
The real center for value creation in big data is analytics. Unfortunately, efforts to run analytics on large data sets are choking existing data warehouse technology, which was designed for reporting, dashboards, and static analysis. This bottleneck tends to limit business analysts’ access to the system as well as how quickly they can find the answers they need. The answer is a straightforward and standards-based approach to accelerating performance. New technology, designed with analytic workloads in mind, makes it possible to offload analytics from the data warehouse to improve performance in both environments. The deployment of a performance-based data solution can free analysts to drive greater innovation and maximize investments in big data.
Read the full article and more: Download Business Intelligence Journal, Vol. 17, No. 4
Highlight of key findings from TDWI's wide variety of research

The Role of Hardware in HiPer DW
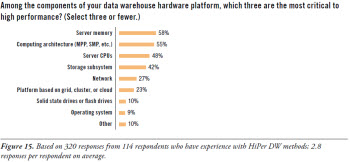
Let’s focus for a moment on the hardware components of a data warehouse platform. After all, many of the new capabilities and high performance of data warehouses come from recent advances in computer hardware of different types. To determine which hardware components contribute most to HiPer DW, the survey asked: “Among the components of your data warehouse hardware platform, which three are the most critical to high performance?” (See Figure 15.)
You may notice that the database management system (DBMS) is omitted from the list of multiple answers for this question. That’s because a DBMS is enterprise software, and this question is about hardware. However, note that--in other TDWI surveys--respondents made it clear that they find the DBMS to be the most critical component of a DW platform, whether for high performance, data modeling possibilities, BI/DI tool compatibility, in-database processing logic, storage strategies, or administration.
(Click for larger image)
Read the full report: Download High-Performance Data Warehousing

FlashPoint Rx prescribes a "Mistake to Avoid" for business intelligence and data warehousing professionals.

Mistake: Bad Practices in Data Naming and Definition
Dave Wells
Much of the confusion and uncertainty when working with data can be eliminated through good practices when naming and defining data. Trust in data, understandability, ease of use, and ease of integration all benefit from disciplined naming and definition practices. Eliminating synonyms, homonyms, ambiguity in definitions, and missing definitions substantially increases value and usefulness of data assets.
The first step in defining data is to assign each data item (entities and attributes) a formal data name. Informal, inconsistent, and meaningless names lead to uncertainty and degrade the quality of data. Names should be assigned using a standard that addresses structure, uniqueness, and clarity of meaning. Avoid the bad practices of data names that are meaningless, nonunique, and randomly structured. Establish data naming taxonomy, vocabulary, and structure. Name data items based on business language and according to a defined standard that includes rules for abbreviation of words.
Every named data item also needs to have a comprehensive definition. Good data definition practices ensure consistency, eliminate confusion, enhance communication, enable data consolidation, and improve overall data quality. Avoid poor practices of missing, meaningless, incomplete, and circular definitions. Instead, develop a rich and robust description for each data item. Describe data thoroughly to fully express the business-based meaning of the data. Good guidelines for data definition tell me what it is, tell me what it isn’t, and provide some examples.
Read the full issue: Download Ten Mistakes to Avoid In Data Resource Management (Q4 2012)

