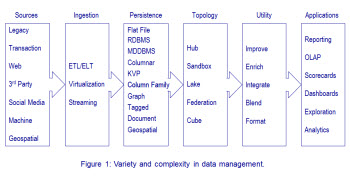
From data sources to applications, the world of data management is substantially more challenging today than in the early days of business intelligence when we worked primarily with structured enterprise data and relational databases.
Variety and complexity of data and processing create new challenges. The demands of agility and reduced time to value add further difficulties. With new challenges, we need to think about the problem differently. It is time for data pipelines that move data efficiently and store data sparingly.
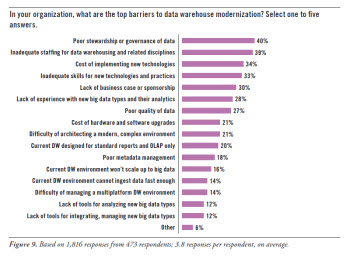
The increase in data management complexity begins with the variety of data sources, including many sources of data external to the enterprise. New sources drive changes in how we ingest and persist data, in topology by which we organize data, and in techniques to increase data utility. All of these changes are necessary to expand use and reuse of data. Figure 1 illustrates many of the factors contributing to added complexity.
(Click for larger image)
Handling Complexity and Demand for Speed
Methods of data persistence have expanded rapidly with the emergence of NoSQL databases. In simpler times we stored most data in relational databases and occasionally used XML or other tagged data storage methods. Today we also work with key value stores, document stores, graph databases, and columnar and big table databases. Choosing the optimum storage method for various kinds of data requires more consideration than when RDBMS was the default.
Topology for data management is especially challenging. The data warehouse—once the centerpiece of enterprise data integration—is now just a single component of a complex data environment that may include multiple data warehouses together with any combination of data lakes, data sandboxes, federated and logical data warehouses, and much more.
Data utility is a difficult topic because quality and usefulness of data are directly related to the goals and needs of the individuals using data—suitability to purpose. With the variety of data users and many distinct use cases, there is no “one size fits all” data structure that suits the needs of everyone. Single-point integration for many uses (the data warehouse approach) meets some needs. Individual data blending per use case (the self-service approach) meets other needs. Balancing methods while achieving consistency and honoring governance constraints can be especially difficult.
The variety of use cases for data is both the catalyst and the beneficiary of added complexity. Data applications that range from basic reporting to advanced analytics demand choices and flexibility of data sources, data structures, data access methods, and data preparation techniques.
In addition to complexity, we have the pressures of demand for speed. Analytics is often a real-time endeavor where the timeline from data to insight must be highly compressed. Eliminating delay and waste between data sources and data applications is essential. The number of points at which data is stored along the path from source to application increases cycle time when getting from questions to answers.
Yet data must be stored to prevent loss of information, lack of history, and failure to meet needs. Storing data many times, however, creates a long path from data to value. When needed data is first staged, warehoused, and then extracted to an analytics sandbox before analysis begins, time to value is directly affected. Figure 2 illustrates typical data stores that contribute to a long data-to-value path.
(Click for larger image)
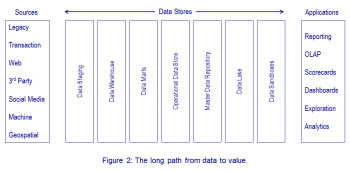
Which data to store—and in which data stores to allocate it—are architectural questions and design challenges. Trade-offs of speed, reliability, accessibility, and maintainability are key considerations.
Utilizing Data Pipelines
Accelerating the data-to-value chain, however, takes more than simply reducing the number of points at which data is stored. Rethinking how we move data is essential. Traditional data warehouse design looks at data movement as data flows. Standard data flows move data through ETL and ELT processes with the goal of storing data in a warehouse or data mart with access by many people and processes. This approach is optimized to store data, not to use data.
We need to rethink design principles for data movement—think data pipeline instead of data flow. Data flow to a single point of integration (data warehouse) is no longer enough. The variety of users and use cases creates the need to have many data pipelines—perhaps as many as one per use case. A pipeline delivers data to the point of consumption, not to a reservoir from which it can be drawn. The pipeline is optimized to use data, not to store data. Figure 3 illustrates the concept of multiple data pipelines.
(Click for larger image)
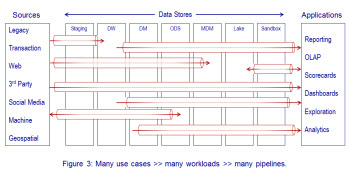
Design data pipelines for fast, efficient movement of data from source to business application. Store data when needed to capture and retain history. Store data when there is a clear and certain need for many people or processes to access a single, standard data structure. Focus on data movement instead of data storage. Move data as quickly as is practical from where it is stored to where it is needed. You’ll serve the business well and step up to many of the challenges inherent to today’s complex world of data.
Dave Wells is actively involved at the intersection of information management and business management. He is a consultant, educator, and author dedicated to building meaningful connections throughout the path from data to business value. Knowledge sharing and skill building are Dave’s passions, carried out through consulting, speaking, teaching, and writing. He is a continuous learner—fascinated with understanding how we think—and a student and practitioner of systems thinking, critical thinking, design thinking, divergent thinking, and innovation.
TDWI Onsite Education: Let TDWI Onsite Education partner with you on your analytics journey. TDWI Onsite helps you develop the skills to build the right foundation with the essentials that are fundamental to BI success. We bring the training directly to you—our instructors travel to your location and train your team. Explore the listing of TDWI Onsite courses and start building your foundation today.
|