 View online: tdwi.org/flashpoint
View online: tdwi.org/flashpoint





June 4, 2015
ANNOUNCEMENTS
NEW TDWI Checklist Report
Eight Tips for Modernizing a Data Warehouse
CONTENTS

5 Important Considerations for an Industry Data Model

Evolving Data Warehouse and BI Architectures: The Big Data Challenge

Who Is Using Advanced Analytics?
Mistake: Failing to Provide Big Data Governance

See what's
current in TDWI Education, Events, Webinars,
and Marketplace
5 Important Considerations for an Industry Data Model
Steve Dine and DeVon Doman
Datasource Consulting, LLC
A commercial off-the-shelf (COTS) data warehouse data model may seem like a silver bullet that will shorten project implementation time and eliminate a high degree of risk. The reality is that most—if not all—development tasks and activities must still be performed and may require more time and effort. The time and effort you save with the purchase of a data model or structure is generally only in the development of the data model itself. You will still need time to learn the new data model, determine which parts of the model can be implemented without change, and customize it to your company’s specific requirements.
In many cases, the COTS industry data warehouse (DW) models can also be purchased with ETL accelerators—extract, transform, and load mappings that have already been developed to populate the model. Given that more than 70 percent of the implementation hours of a DW project are devoted to the development of the ETL mappings, having them completed can offer significant time savings. However, as with the DW models, a significant amount of work is required to customize, tune, and unit test the mappings. Knowing these potential pitfalls up front will help you determine whether these solutions are right for you, and if so, you must ensure that a proper amount of time and adequate budget has been allocated to complete the project.
Here are five important considerations for the purchase of a data model and ETL accelerators:
1. Do not underestimate the time and effort needed to understand the new data model or the amount of business involvement required.
Each industry and business has its own vocabulary. When a vendor with a “standard” product uses industry-standard terms, a conflict of terms can occur and cause frustration and misunderstanding. Every table and data element of the purchased data model must have a definition and be understood within the context of your business. This means you must reconcile your business terms with the terms used in the product. Plus, organizations usually have their own business rules and metrics that take significant time and effort to surface and define.
In addition, allocate time to profile data from existing data sources to provide information on data volumes, data format, data integrity, null values, value ranges, uniqueness, and data patterns. This is critical information when mapping data elements to the new data structures. Be prepared to deal with missing values, overloaded attributes, duplicates, and data-type and data-length conflicts, which can take significant time to resolve.
2. Understand how extensions are accommodated.
The ease of extending data structures must be understood. No purchased data model will be used as-is. You will likely need to customize or extend the data model. Depending on the vendor, extension or modification to some or all data structures may not be allowed. If so, you may be required to architect an approach for extending data structures while seamlessly integrating with the “base” structures.
Some vendors may have built-in functionality for extending or modifying the data structure. This functionality may come in the form of extra generic columns already defined in a table or a set of parallel tables that can be used in conjunction with base tables. Depending on the product, more than one approach may be used to extend data structures.
3. Understand the impact of customizations on the product upgrade path.
When data models are purchased and an annual licensing or maintenance fee arrangement is made, upgrades to the data model may be provided by the vendor. The requirements for an automated upgrade must be understood. For example:
- Must certain tables remain unchanged?
- Will customizations be dropped, become invalid, or no longer needed?
- Do all upgrades have to be implemented?
- Is it possible to skip some upgrades?
If the product upgrade path is not understood, an upgrade will require an enormous amount of effort to make everything (i.e., ETL, reporting, and data extracts) work correctly.
4. Ask how the purchased data model handles hierarchies and reference data.
As vendors design solutions to appeal to many potential customers, they often create data structures that are either too generic or so targeted to an inflexible solution that it is difficult to load or use. Extensions to hierarchies can be particularly challenging. Have a good understanding of your existing hierarchies (geography, internal organizations, product, etc.) and try to assess the effort needed to fit into the vendor’s approach for implementing hierarchies. Make sure the reference data you use today has a place in the new data structure and that all needed data elements are (or can be) accounted for.
5. Don’t underestimate the time and effort required for effective testing.
Don’t be fooled into thinking that as long as your source data elements are mapped to the new data structure data elements, everything will work together correctly. This assumption must be validated. Purchasing a data model does not eliminate the need for thorough, rigorous testing to verify everything works as expected. Testing must be performed on the migration of source data into the new data structure, as well as on the new data structure itself. Both the content and the structure of the data must be tested. Just because data loads without error does not mean the data is valid and ready to use.
Summary
Utilizing a predesigned industry DW data model can save significant time and effort when embarking on a new DW implementation. However, when vendors talk about the time and effort saved by using their data model, it’s usually with the caveat that you must use their solution “as-is” or “out of the box.” Keep in mind that you will likely need to customize the data model, and any deviation is generally more complex to perform than on data design and ETL mappings you are already familiar with. Take the time to understand how much effort is required to implement and maintain the data model and how long it will take to map your existing data to the new model.
Steve Dine is the managing partner at Datasource Consulting, LLC. He has extensive hands-on experience delivering and managing successful, highly scalable, and maintainable data integration and business intelligence solutions. He is the former director of global data warehousing for a major durable medical equipment manufacturing company and currently works as a consultant for Fortune 500 companies. Steve is a faculty member at TDWI and a judge for the TDWI Best Practices Awards. Follow Steve on Twitter: @steve_dine.
DeVon Doman is the data architecture practice lead at Datasource Consulting, LLC. He has more than 30 years of IT experience, 15 years of which has been focused on strategy and delivery of business intelligence solutions. He has experience in a wide range of industries including high-tech manufacturing, healthcare, insurance, and transportation. DeVon has worked with some of the largest multinational companies in the world.


Evolving Data Warehouse and BI Architectures: The Big Data Challenge
Dai Clegg
It would be a mistake to discard decades of data warehouse architectural best practices under the assumption that warehouses and analytics stores for big data are not relational nor driven by data modeling (top-down or bottom-up).
That said, existing best practices are not enough. Following a period of some stability, the last decade has seen the emergence of MPP data warehouse appliances, then Hadoop and MapReduce, NoSQL databases, and real-time analytics, together with a host of variants, hybrids, and add-ons. The solution space—the collection of available options—has grown rapidly. Consequently, building an effective data warehouse and BI strategy has become even more complex. Meanwhile, the problem space has become more demanding. New sources of social media and machine-generated data have created opportunities to answer new questions.
Without underrating the value of its history, it is clear that data warehouse architecture is entering a new phase, and history is not enough.
Learn more: Read this article by downloading the Business Intelligence Journal, Vol. 20, No. 1

Highlight of key findings from TDWI's wide variety of research
Who Is Using Advanced Analytics?
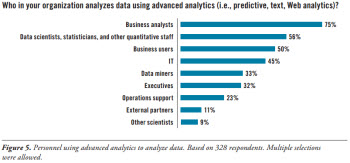
TDWI Research has uncovered a shift occurring in the builders of predictive models. Whereas in the past the builder was a statistician or other quantitative person, a current market move involves the business analyst in building models. It may be that models the business analyst builds have to be reviewed for quality control by a statistician or data scientist, but the move is apparent. In TDWI’s 2013 Best Practices Report on predictive analytics, over 80% of active users of predictive analytics stated that business analysts would build models. This group felt that knowledge of the business, knowledge of the data, and critical-thinking abilities were enough to build a model. Seventy-nine percent stated that statisticians would be the primary builders. The assumption was that business analysts would be utilizing (that is, building) more advanced analytics models.
In this survey on next-generation analytics, we asked, “Who in your organization is involved in actually analyzing data using advanced analytics (i.e., predictive, text, Web analytics)?” In this case, respondents cited the top three users as business analysts (75%), statisticians (56%), and business users (50%) (See Figure 5.) This, too, points to the fact that business analysts, for better or worse, are more often analyzing data utilizing advanced analytics. This is an important factor in next-generation analytics.
(Click for larger image)
Read the full report: Download the Next-Generation Analytics and Platforms (Q1 2015)


FlashPoint Rx prescribes a "Mistake to Avoid" for business intelligence and data warehousing professionals.
Mistake: Failing to Provide Big Data Governance
Krish Krishnan
Data governance has always been a sensitive subject in the world of data management. The first question is often whether data governance is appropriate for big data. We are still talking about “data,” so yes, we need a governance program no matter what kind of data we have: big, small, fast, wide, or deep—it doesn’t matter.
We need governance for this program because:
- Data and user security are still evolving in Hadoop.
- The data must be discovered and tagged before analysis; this can require several types of governance rules to be processed and applied to the data to get the correct results and eventually the appropriate analytic outcomes.
- The data is free form, and acquisition of this data requires strong governance on HCatalog and associated metadata processed and applied to the data.
- Executive sponsorship must be managed to successfully implement Hadoop. This can be executed as a part of your enterprise’s governance program.
- The use of taxonomies and ontologies, if not governed and managed, can cause a data processing overrun from acquisition to analytics on the Hadoop platform.
In current Hadoop implementations, we see issues and mistakes arising with governance. Further analysis of these issues reveals consistent ignorance about security, compression, metadata management, and integration of taxonomies and ontologies.
When presented with a road map for big data implementations and the maturity models available today (TDWI, EMC) where one core area is governance, teams agreed that paying attention to data governance could have made the difference between success and failure.
Governance is critical for the overall success of all data-driven and data-oriented programs, including Hadoop implementations. For your implementation to succeed, we recommend that to create a road map and a governance maturity model that will guide you from today into the future.
Read the full issue: Download Ten Mistakes to Avoid in Hadoop Implementations (Q1 2015)

