
 View online: tdwi.org/flashpoint
View online: tdwi.org/flashpoint




November 5, 2015
ANNOUNCEMENTS
NEW Data Innovations Showcase
Why Your Data Integration Strategy Must Be Cloud-First
NEW TDWI Assessment
Hadoop Readiness Assessment and Guide
NEW 2015 BI Benchmark Report
Organizational and Performance Metrics for Business Intelligence Teams
NEW Best Practices Report
Emerging Technologies For Business Intelligence, Analytics, and Data Warehousing
NEW Ten Mistakes to Avoid
Ten Mistakes to Avoid In Predictive Analytics Efforts
CONTENTS

Data Engineering: A New Way to Manage and Process Data

Recruiting Analytics Talent: Attracting, Retaining, and Growing a Critical Yet Scarce Resource

Mistake: Failure to Frame the Business Problem

See what's
current in TDWI Education, Events, Webinars,
and Marketplace
Data Engineering: A New Way to Manage and Process Data
Krish Krishnan
Independent BI Analyst, Consultant, and Educator
As I’m writing this article, in the fall of 2015, my memory travels back to 1991—the first year of my exposure to client-server programming with FoxPro, dBase, Windows C++, Oracle, and Visual Basic (not the .net version, just plain old vanilla). All the efforts from then until 1998 centered around delivering applications that would and could execute on databases and return computed result sets. We did Matlab and graph computing but had limited means to achieve the success we are capable of today. Along the way, we drove business intelligence (BI) with business objects, Cognos, MicroStrategy, and Excel, but these reports were always batch oriented and delivered to the specifics of one organizational team. Then came the analytical models and associated applications led by SAS and SPSS.
Fast forward to 2015 and we have substantial advances at our disposal with the availability of infrastructure, database technologies, in-memory applications, analytics, visualization and mashups, virtualization, and more. For all our progress, however, fundamental questions remain unanswered: What is the business value from data and all these efforts? What do we need to deliver?
In my opinion, these questions should be analyzed by closely examining what we’ve been doing and which links are missing. The focus areas to consider are:
- What is the data we are discussing about?
- Where do we get this data?
- What is the quality of the data and the acceptable margin of error?
- How do we analyze this data?
- Who defines the data development life cycle?
- What are the analytics to execute on this data?
- What are the key rules to execute when integrating this data into the enterprise data architecture?
- Does this data impact the master data process?
- Who defines the metadata for this data?
- What data lineage information needs to be captured and managed for this data?
As a practitioner, your first reaction is likely to be, “Wait, we do think about all these areas when we build our data warehouse and analytical systems.” Yes, you think about all these areas, but do you practice them as part of your enterprise data architecture? Ninety-nine percent of the time, the answer is no, and 1 percent of the time it’s yes. Why didn’t we bother to think of data and its ecosystem as separate from the infrastructure layers? Why do we always jump to draw the conceptual model and see where it takes us? Because we had to fit the data into the underlying infrastructure (i.e., the database), we looked at the ecosystem in only one way. To accommodate the database requirements of structured data and its life cycle, we followed this cycle:
(Click for larger image)
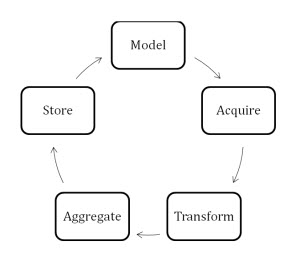
In this trap that we set and fall into, we ignore the following in different stages of processing:
- Business requirements from the data
- The type of data and the associated analysis
- Lineage of data
- Transformation rules applied
- Master data management impacts
- Business metadata
Typically, what we do when the actual reports and analytics are executed is abysmal. We patch data in the different systems that need to be integrated and eventually execute the end-state deliverables. The issue starts when the executive asks why or how the numbers are high or low or different from what was expected, and there starts another set of exercises to find the details. The blame is placed on BI failing or analytics being a total waste of time, and the final state here leads to silos of information architecture that stand up to deliver that business value but fall short of some cycle of execution within the entire ecosystem. That cycle, which leads to all these issues, is the missing definition of the business value of data.
Now the bigger questions come: Who defines the business value of data and how is it managed? Where is the overall change needed? How does an enterprise evolve? This is where we introduce the concept of data engineering. We need to process and transform data from a design and implementation perspective without worrying about the infrastructure. Is this possible and is this real? Are we going to succeed with this direction? The answer is yes—but how?
To ensure that we are talking about the right outcomes, let’s examine what the industry is discussing today:
- “We are on the cusp of a tremendous wave of innovation, productivity, and growth, as well as new modes of competition and value capture—all driven by big data as consumers, companies, and economic sectors exploit its potential,” assert James Manyika et al. in Big Data: The Next Frontier for innovation, Competition, and Productivity, a comprehensive research study by the McKinsey Global Institute.
- Alexander Linden, research director at Gartner, maintains that extracting value out of data is not a trivial task, and one of the key elements of any such “making sense out of data” program is the people, who must have the right skills. (See Why Should CIOs Consider Advanced Analytics.) Data scientists are not traditional business analysts; rather, they are professionals with the rare capability to derive mathematical models from data to reap clear and hard-hitting business benefits. They need to network well across different business units and work at the intersection of business goals, constraints, processes, available data, and analytical possibilities:
- Many of our most advanced clients are experimenting with the positions of chief data officers (CDOs) or chief analytics officers (CAOs). Sometimes the CDO/CAO will directly command a (virtual) data science lab. We think those labs must be orchestrated virtually, with the (citizen) data scientists distributed throughout the organization.
- Data science is the discipline of extracting nontrivial knowledge from often complex and voluminous data to improve decision making. It involves a variety of core steps, including business and data understanding and data modeling.
- Descriptive analytics tools answer the question what happened? They do this by querying data and summarizing key performance metrics, such as a report of annual sales by region.
These industry discussions and ideas are highly valid but still tend to miss the outcome and delivery. Data engineering needs to be implemented and brought as a practice into the overall information and analytics architecture programs—a brief discussion of which follows.
Data Engineering
As shown in the figure below, we are talking about introducing layers of engineering architecture for data where we can apply all the business rules, transformation rules, lineage information, data processing, and capture auditing requirements. The mechanisms of doing this layer include traditional techniques like extract, transform, and load (ETL) and changed data capture (CDC), but these techniques have not taken off in a big way as the data that is handled is highly structured and not all of it is captured.
(Click for larger image)
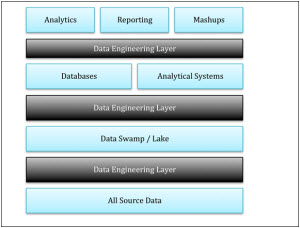
In the new ecosystem’s layers of data engineering, we propose the following types of processing:
- From source into data swamp: We can serialize the data into files, add lineage information to job processing systems, and collect and enrich metadata information. This data will consist of structured, semi-structured, and unstructured data in multiple formats.
- Within the data swamp: We can apply rules of processing and data enrichment to the data in the swamp layer and create data lakes. The layer of processing and engineering will execute the underlying data discovery and operational analytics programs. Additional data enrichment and master data identification aspects can be implemented during this stage. This data will consist of structured, semi-structured, and unstructured data in multiple formats.
- Data lake: The outcomes of data discovery, tagging, operational analytics, and business rules processing provide the data to be architected into the data lake layer. This data will consist of structured, semi-structured, and unstructured data in multiple formats.
- Databases and analytical systems: This is the structured layer of data storage that is provided today. Applying data engineering in this architecture will create different layers of rules that enable lineage, aggregations, enrichment, and transformations. These layers provide us multiple benefits including performance, security, encryption, and life cycle. This will include ETL, CDC, unstructured and text analytics engines, rules engines, and algorithms.
There are several changes that need to happen in this architecture. The most important are:
- Transformation of data is not driven by infrastructure but managed by rules and associated lookups along with their implementation.
- Infrastructure will be utilized to store and compute data in the same layers, but this approach should not and will not change the data engineering layers.
- Analytics will be processed across the different layers and therefore will drive enterprise decision insights.
Outcomes from data engineering include:
- Defined layers of data processing and management
- Independent processing from infrastructure
- Heterogeneous frameworks and processing architectures
- Data lineage
- Auditing and compliance
- Data definition and life cycle
- Improved master data and metadata management
Summary
This topic, while engaging, is confusing and complex due to its emerging segments and will evolve in the next few years. The implementation of the first iterations of data engineering is in data science teams. This exercise will provide us foundational layers that are needed to enhance and identify in data engineering.
If you are interested in learning more about data engineering, please stay in touch and also watch future TDWI programs for associated announcements.
Krish Krishnan is a recognized expert in the strategy, architecture, and implementation of high-performance big data analytics, data warehousing, and business intelligence (BI) solutions. As an independent analyst and consultant, he regularly speaks at industry-leading conferences, writes for trade publications, and offers guidance to start-ups and venture capital firms. He has authored three books, four e-books, and over 395 white papers, articles, viewpoints, and case studies on BI, analytics, and related topics. He publishes with the BeyeNETWORK. Krish will be teaching at upcoming TDWI conferences in Orlando and Las Vegas.


Recruiting Analytics Talent: Attracting, Retaining, and Growing a Critical Yet Scarce Resource
Greg Corrigan
Human resources experts will tell you the analytics professional is one of the hardest job categories for them to find, attract, and retain. The stakes are high. Hiring the right person(s) can change the game for your business. Hiring the wrong person, or worse—letting the position go unfilled for too long—can leave you playing catch-up with competitors who have figured it out.
This article helps HR professionals, hiring managers, senior leaders, and recruiters source analytics talent. As a senior analytics leader with over 20 years of experience in hiring analytics talent, building high-performing analytics teams, and growing individual talent, I will share best practices in all aspects of hiring and retaining this precious commodity. We discuss the role of analysts, their characteristics, where to find the best candidates, and how to evaluate resumes and assess candidates’ leadership potential, among other topics.
Learn more: Read this article by downloading the Business Intelligence Journal, Vol. 20, No. 3.
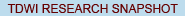
Highlight of key findings from TDWI's wide variety of research

Organization of BI Programs
The majority of business intelligence (BI) programs report to a line of business, as compared to reporting to IT. In 2015, 53 percent of respondents answered to business leaders, including the CEO, business unit heads, finance, operations, and sales and marketing. This is a pronounced increase from 2012, when 47 percent of programs reported to the business, and 2009, when 40 percent did.
In contrast, the portion of BI programs reporting to IT or information management leaders declined to a new low of 47 percent in this survey series. Clearly, the BI industry has recognized that the best value from BI is realized when IT and business professionals collaborate closely in implementing and iterating BI environments. In fact, TDWI regularly hears BI professionals reject being characterized as “IT” because they went into BI to be closely involved with the business process, and that involvement is best aligned when reporting to the business they serve. Other trends, including a departmental focus for many analytics initiatives and cross-pollination of business and IT skills across today’s professionals, also contribute to this ongoing shift.
(Click for larger image)
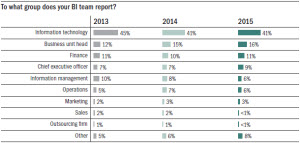
Although nearly two-thirds (64 percent) of BI environments are geared to support the enterprise, departmentally focused systems appear to be gaining in popularity. Twelve percent of BI environments support a department in 2015, up from recent years. This aligns with the trend of BI programs reporting to the business, as departmental BI environments typically have a discrete focus on optimizing customer relationship management, sales, support, supply chain, and other areas.
In a related trend, analytics applications have a natural bias toward a specific department. For example, sales and marketing wants to own and control customer analytics, just as a procurement department or supply chain team wants to own supply and supplier analytics. As the number of analytics applications rises, it shifts the focus toward departmental BI, DW, and analytics.
(Click for larger image)
Read the full report: Download the 2015 TDWI BI Benchmark Report: Organizational and Performance Metrics for Business Intelligence Teams.


FlashPoint Rx prescribes a "Mistake to Avoid" for business intelligence and data warehousing professionals.
Mistake: Failure to Frame the Business Problem
Fern Halper
A first step in any analysis is determining the business problem to solve. Arguably, this is one of the most critical steps in analysis. It is important to start with the end goal in mind. Some organizations make the mistake of jumping into predictive analytics without thinking about the business problem or what the analysis is supposed to accomplish. They don’t frame the problem.
When you frame a business problem, you are putting a structure around it. You are articulating the problem to be solved. This often includes thinking about the kinds of decisions you’re going to make from the analysis and how your business will use the results of the analysis. For instance, declining product revenue might be a problem in your organization. However, you need to tease this fact out more to pinpoint the problem you want to solve. Perhaps you know that declining revenue is associated more with your business customers than your residential customers. Now you can start to focus on business customers. You can ask, “Which business customers should I make a special offer to in order to increase revenue in time period by amount?”
It is also a good idea to pick an initial problem that is relatively visible and offers easy access to the data. It can also make sense to choose a problem where you have past results and, ideally, metrics. For example, in the case of customer churn, you might have past churn figures for a certain class of customer, what you implemented to reduce churn, and how well it worked. Additionally, you can show how your models might have done better at predicting churn using past data.
Read the full issue: Download Ten Mistakes to Avoid In Predictive Analytics Efforts (Q3 2015).

