 View online: tdwi.org/flashpoint
View online: tdwi.org/flashpoint





July 5, 2012
ANNOUNCEMENTS
New TDWI Checklist Reports:
Satisfying New Requirements for Data Integration
Seven Steps to Actionable Personal Analytics and Discovery
New TDWI E-Book:
Big Data Integration
CONTENTS

Big-Data Integration: A Status Report

Business Intelligence and Data Warehousing on a Limited Budget

Making the Right Deployment Decisions
Mistake: Operating Without a Plan

See what's
current in TDWI Education, Events, Webinars,
and Marketplace
Big-Data Integration: A Status Report
Mike Ferguson
Intelligent Business Strategies
Topic:
Data Management
If you are investigating big-data technologies for analytics on multi-structured or high-volume data, you will soon realize that the technologies require the development of batch MapReduce applications written in languages such as Java and Python in order to load data into Hadoop and analyze it. This is somewhat different from traditional data warehousing approaches, in which development involves the use of ETL tools that generate code (e.g., Java, SQL, PL/SQL) to capture, transform, integrate, and load data to build data warehouses and data marts.
On the front end, the contrast appears stark: data scientists are analyzing data in Hadoop using analytical programming languages, such as R, versus IT professionals and business users who are using BI tools that generate SQL, X/Query, or MDX to query, analyze, and report on data in data warehouses and data marts.
At a glance, the two worlds seem like chalk and cheese. With such a shortage of data scientists, many companies are naturally asking how they can leverage their investment in existing technologies, such as data integration tools, to capture and integrate multi-structured data rather than having to start from scratch and hand code everything.
It’s a fair question, and the truth of the matter is that although we started from a position of developing hand-coded MapReduce applications to run on Hadoop (and other NoSQL data stores), things are changing rapidly. The idea that you have to code it all yourself is quickly dying as data integration technology vendors aggressively move to announce support for big-data environments.
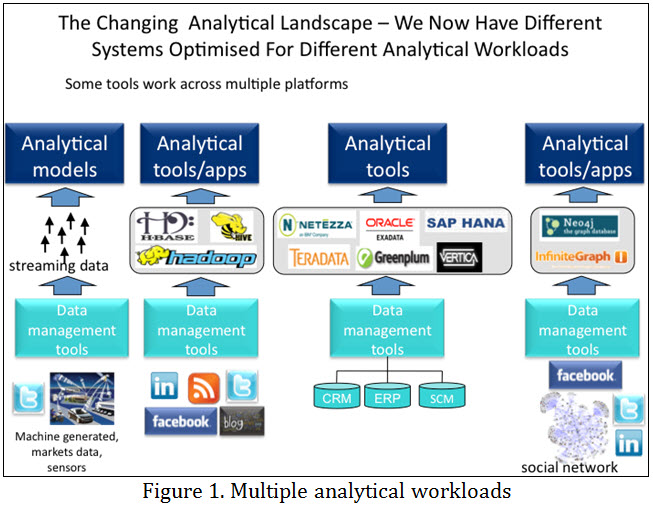
When it comes to analytics, the first thing to recognize is that we are now moving toward different systems optimized for different analytical workloads. Today, we are dealing with streaming data in motion, the Hadoop stack with its Hadoop Distributed File System (HDFS), analytical relational database management system (RDBMS) appliances, and other NoSQL DBMSs (e.g., graph DBMSs), as shown in Figure 1.
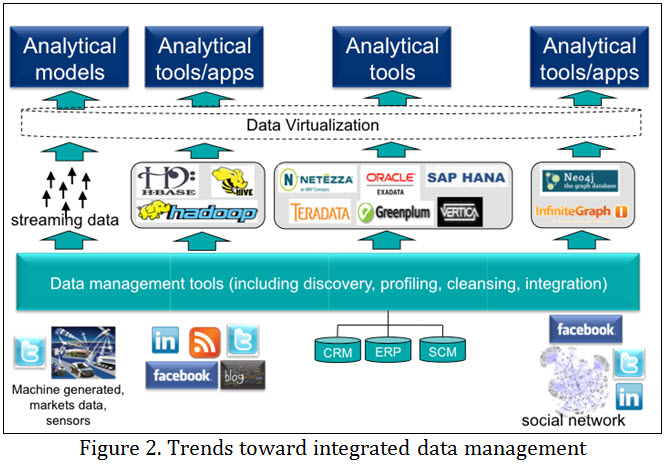
Data integration often differs for each type of analytical system, with different technologies being used to capture, transform, and integrate data before loading (or before analyzing it as it materializes, in the case of event stream processing). However, the trend is for data integration tools to move beyond cleaning, transforming, and integrating data before populating RDBMS-based data warehouses and data marts, and instead manage data flows into multiple data stores and simplify access to data across the entire analytical ecosystem, as shown in Figure 2. This also means managing the movement of data between these environments.
(Click for larger image)
(Click for larger image)
You don’t have to look far to see evidence of this trend. Data integration tools are now offering built-in support for big-data platforms. This support is primarily focused on Hadoop distributions but also stretches to other NoSQL DBMSs such as Cassandra and MongoDB (e.g., Pentaho Data Integrator).
Two types of data integration tools that support big data (shown in Figure 2) will be or have already been announced:
- ETL tools that clean and integrate data from multiple data sources before storing it in one or more target systems. Examples include DataFlux Data Management Platform and IBM InfoSphere Information Server.
- Data virtualization tools that present virtual views of data in multiple underlying data stores as if it were already integrated in a single DBMS. Data integration in this case is done at runtime on receipt of SQL queries on virtual data. Examples include Composite Software Information Server and Denodo Platform.
With respect to ETL support for big-data integration, the focus is naturally around Hadoop, where the issues are:
- Loading data into Hadoop, including HDFS, Hive, and HBase
- Discovering data in Hadoop to understand relationships in multi-structured data
- Cleaning and transforming data within Hadoop
- Using analytics within data integration workflows to analyze data in Hadoop
- Extracting data from Hadoop into an RDBMS
To process data in Hadoop, the trend among ETL vendors is to use the ETL tool to generate HiveQL, which, in turn, is translated into MapReduce jobs to process Hadoop data. Oracle Data Integrator (ODI) already does this using a JDBC Hive connector and an ODI file-to-hive knowledge module. This trend will continue.
ETL vendors (including Oracle, Informatica, Pervasive, Talend, and Pentaho) support loading data into Hadoop clusters. Depending on the Hadoop distribution, some vendors also support changed data capture during Hadoop load processing. For example, Talend can stream changed data directly into MapR’s Hadoop distribution via MapR’s Direct Access NFS feature.
Automated discovery of data relationships--the ability to automatically highlight data of interest and assess data quality in unmodeled Hadoop data--is not well supported. Few vendors are able to do this today, although some capability exists. Data cleansing of Hadoop data is supported in some ETL tools, such as Talend Big Data Studio.
Vendors are also trying to accelerate ETL processing on Hadoop, which can be an issue when processing large volumes of data. Pervasive (with DataRush for Hadoop) and Syncsort (with DMExpress Hadoop Edition) have focused on this problem, respectively exploiting massive parallelism to undertake specific transformation and sort activities. Pentaho Data Integrator also supports data compression to accelerate ETL processing.
To deal with text, ETL vendors are pushing text analytics into ETL processing to parse text data in Hadoop using MapReduce. For example, Informatica’s HParser provides a tool to develop transformations, then deploy and run them on Hadoop to produce tabular data, which could be loaded into Hive tables for analysis.
Some vendors are also opening their ETL tools to MapReduce developers to make use of ETL transformations such as a mapper, combiner, and/or reducer. In addition, transforming data using Pig Script is also possible within ETL workflows in some products. Pentaho Data Integrator is an ETL tool that supports both of these capabilities.
In addition to ETL processing, there is a demand for analyzing Hadoop data during ETL processing to automate analysis. This can be done using technologies such as Pervasive RushAnalyzer, which works with flat files, relational databases, NoSQL databases, and the Hadoop Distributed File System.
Once processed, many ETL tools can also take data out of Hadoop and load it into RDBMS-based data warehouses. Oracle Data Integrator, which makes use of the Oracle Loader for Hadoop’s map/reduce utility, Pentaho Data Integrator, and Informatica also support Hadoop as a data source.
With respect to data virtualization, both Composite and Denodo can connect to Hadoop via Hive as well as to other systems in the analytical ecosystem. Joining big data to data from other systems via data virtualization has to be done with care, however, and I would expect data virtualization server optimization to advance considerably in the next 12 months, introducing better ways to process queries.
As you can see, enterprise data integration vendors are expanding their products to support big data. This is just the beginning. Expect much more to come.
Mike Ferguson is managing director of Intelligent Business Strategies Limited, a leading information technology analyst and consulting company. As an analyst and consultant, he specializes in business intelligence, big data, data management, and smart business. He can be contacted at +44 1625 520700.


Business Intelligence and Data Warehousing on a Limited Budget
Ralph Thomas
In their book Competing on Analytics: The New Science of Winning, Tom Davenport and Jeanne Harris provide many real-world examples about CEOs who turn their companies into data-driven competitors. However, most of us are not CEOs, and we may not be able to easily convince a CEO to spend the significant dollars on analytics that the companies portrayed in the book did.
This article focuses on the rest of us--those who know that our companies will be much more successful if they leverage analytics, but who are not senior enough to acquire the significant capital needed to quickly and dramatically make the transition.
Instead, we have a limited budget and the power of our ideas. This article focuses on how to translate these ideas into action.
Read the article: Download Business Intelligence Journal, Vol. 17, No. 2

Highlight of key findings from TDWI's wide variety of research
Making the Right Deployment Decisions
Extending existing BI and analytics to mobile platforms is preferred but not required. The introduction of new platforms and form factors always generates new technologies that are expressly suited to take advantage of the platforms’ unique capabilities. Mobile devices have had this effect on the BI and analytics market as start-up vendors and open source developers introduce tools, applications, and software-as-a-service (SaaS) offerings that are designed for use with mobile deployments. At the same time, however, organizations have major investments in existing BI, analytics, and data warehousing systems; they have management, security, and cost reasons to prefer extending existing systems onto mobile platforms.
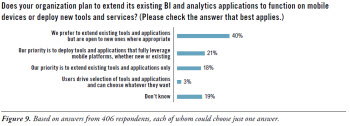
However, the desire to extend existing systems does not appear to close the door on new technologies that could help organizations realize goals more effectively. In our research (Figure 9), 40% of participants said that their organizations would prefer to extend existing tools and applications but are open to new ones where appropriate, while about 18% said it was their priority to extend only existing tools and applications (for organizations with over 100,000 employees, this percentage rises to 26%). A healthy portion (21%) said that their priority is to deploy tools and applications that fully leverage mobile platforms, whether they are new or existing products. Only about 3% said that their users drive tools and applications selection and can choose whatever they want. This result echoes the finding noted earlier that despite the “personal” nature of mobile devices, IT still plays a major role in determining and provisioning the devices--and the BI applications for them.
(Click for larger image)
Read the full report: Download Mobile Business Intelligence and Analytics: Extending Insight to a Mobile Workforce (TDWI Best Practices Report, Q1 2012)

FlashPoint Rx prescribes a "Mistake to Avoid" for business intelligence and data warehousing professionals.

Mistake: Operating Without a Plan
Marc Demarest
One of the themes in the marketing material emanating from big data proponents seems to be that we don’t need to plan or design things anymore. Usually these claims are made at fairly low levels in the value stack: we don’t have to design schemas anymore; we don’t have to plan storage tiering or allocation; we don’t have to implement complex a priori indexing strategies.
The larger message seems to be just do it. In my experience, this you-can-just-leap-to-implementation message is having a profound impact on IT professionals, who have felt for some time that planning was ultimately about going through the motions for very little value, and that planning often just got in the way of getting the job done. Planning also stretched project cycle times and angered business constituencies.
As I suggested above, the broad-based notion that big data somehow relieves us of the responsibility of planning and design is a serious misconception. I don’t see anything in the big data phenomenon that requires significant changes to our current planning and governance models; if they work well now, they’ll work well for big data projects. If they’re organizational theater now, they’ll be organizational theater for big data projects as well.
Planning is a response to risk and complexity, and, as I suggested in Mistake Two, big data equals big risk. Uncharacterized and unplanned for, that risk will certainly produce projects that consume cash and deliver no appreciable business value.
Read the full issue: Download Ten Mistakes to Avoid in Big Data (Q2 2012)

