





November 4, 2010
ANNOUNCEMENTS
Submissions for the next Business Intelligence Journal are due December 3. Submission guidelines
CONTENTS

Getting Started with Data Governance

Mistake: Inadequate Monitoring of Data Interfaces

See what's
current in TDWI Education, Research, Webinars, and Marketplace
Profiling Time-Dependent Data
Arkady Maydanchik
Topics:
Data Profiling, Metadata
Data profiling is the process of analyzing data to understand its true structure and meaning. It is critically important because existing metadata in most organizations is incomplete, incorrect, or obsolete. Thus, data profiling must be the first step in any data-driven project.
With the proliferation of efficient tools, data profiling has become one of the most common activities in data management. Unfortunately, many data profiling initiatives do not go beyond basic column profiling--gathering summary counts and statistics with frequency and distribution charts for individual data fields. Historically, data profiling tools were built for column profiling, even though they can be used to do much more.
Although column profiling produces a wealth of valuable metadata, it falls short when dealing with time-dependent data. Consider a simple example: imagine you are dealing with a payroll table that contains historical compensation data by employee paycheck. The table will likely have the following fields:
- Employee ID
- Paycheck effective date
- Payroll code
- Pay amount
- Several fields with additional details
Column profiling will easily produce the distribution of paycheck effective dates and the frequency chart for payroll codes. We may then learn that the table has more than 10 years of compensation history and 133 distinct payroll codes. We can identify and count the records with missing payroll codes and/or strange negative pay amounts, and might identify payroll code “ZZ,” which is sometimes used in place of a missing value (often referred to as a default value).
All of this information is extremely valuable. However, it leaves many questions unanswered, such as:
- How much history do we have for each payroll code? The fact that the table has 10 years of history overall does not tell us anything about the history for individual payroll codes. Some codes may have only been tracked for the last six months, while others may be historical and no longer used. Without this knowledge, we risk making incorrect assumptions about data availability.
- Do the payroll codes change meaning over time? Indeed, it is quite typical for the same code to be used to track different types of compensation during different periods of time. Such situations are especially common as a result of database consolidations after corporate mergers and acquisitions. Without this knowledge, it is likely that the data will be misused in aggregate reports.
- Do the timestamps (paycheck effective dates) follow certain patterns? Some types of payments (such as year-end bonuses) are made only during certain months. Other payments occur only on the first or last day of the month or only on business days. Knowledge of such patterns is key to the design of data quality rules designed to find incorrect or missing data.
Unfortunately, none of these questions can be answered by analyzing individual column profiles. A different set of techniques is required: time-dependent data profiling.
The objective of time-dependent data profiling is to learn how much history exists for different data categories, whether the data follows any predictable patterns, and whether the data meaning and patterns change over time. There are a great variety of techniques for time-dependent data profiling, ranging from simple timeline and time-stamp pattern profiling procedures to complex approaches for analysis of event histories and state-transition models. Some are basic; advanced techniques may involve multidimensional analysis.
Although I am not aware of existing data profiling tools that explicitly target time-dependent data, in many cases the desired information can be gathered using column profiling tools and simple SQL queries. Time-dependent data profiling requires skill, experience, and creative thinking. The real challenge is to understand what to profile, how to organize the results, and what to look for. As usual, the devil is in the details.
Arkady Maydanchik is a recognized data quality practitioner and educator. He is a frequent speaker at industry conferences and the author of the Data Profiling, Data Quality Assessment, and Ensuring Data Quality in Data Integration online courses available through eLearningCurve.

Getting Started with Data Governance
Dave Wells
Topics:
Data Governance
Data governance, the work of managing data as an asset, is a hot topic today because the risks of poorly managed data and the rewards of well-managed data are highly visible. Financial and regulatory pressures create the desire (and need) for governance. However, getting started is difficult because data governance is a complex undertaking. Before tackling the details, it is wise to survey the landscape. Ask yourself three “big picture” questions:
- Why govern data?
- What data should be governed?
- How much governance is needed?
1. Why Govern Data?
Data governance is driven by business goals in many areas: data quality, data security, data standardization, data consolidation, regulatory compliance, information utility, information management maturity, and more. Data governance programs frequently begin because of concerns about data quality, security, and/or compliance. These are typical motivators because of their high-pressure and high-visibility nature. When data governance is initiated in conjunction with a master data management (MDM) program, standardization and consolidation are common goals; with them, governance becomes a critical success factor for the MDM program.
Whatever your motivation, start with a pain point. Begin where there is pressure and visibility. Be clear about your goals, and identify a small number that are achievable and where you believe you can overcome the obstacles and challenges.
2. What Data to Govern?
Every organization has abundant data. It is present in data warehouses, decision support databases, enterprise and departmental systems, shadow systems, end-user databases, spreadsheets, and more. Each database has different needs and considerations for quality, security, and compliance. Furthermore, the data encompasses many subjects--customers, products, orders, accounts, employees, and so on--and each subject has different needs and quality, security, and compliance requirements.
The combination of abundant and often redundant data with a multitude of data subjects raises several questions about data scope. Looking at a single subject--customer, for example--the questions include:
- Do you need to govern customer data?
- What motivates you to govern customer data? Quality, security, compliance?
- Where are all the places customer data exists, including end-user databases and spreadsheets?
- For each customer data location, is data governance necessary? Is it practical?
These are not easy questions to answer, and the answers will vary by business. Consider the implications of customer data in a spreadsheet on a portable USB drive. If your business is healthcare and your customer data is patient data, security and compliance issues are significant. If your business is media services, your data may be at lower risk. It may be necessary to govern spreadsheets in one instance and impractical to do so in another.
Limit the scope to data that clearly needs governance. If you’re getting started with governance, start small: one or a few subjects with a high degree of cross-functional business activity. In addition, consider for each subject and for each kind of database the level of business interest and participation you can expect. What level of support and sponsorship is realistic? What level of resistance is likely?
3. How Much Governance?
In addition to deciding how much data to govern, you must determine how much governance you need. How much process is needed to meet your governance goals? How much enforcement is necessary? How much process and how much enforcement are culturally feasible?
At one end of the spectrum is education and communication about good data management practices. Adoption of the practices and development of good data management habits is mostly voluntary. Some workgroups are early adopters and others lag behind. The level of accountability is low and data governance maturity develops slowly.
The opposite end of the spectrum is one of defined policies with rigid enforcement. Processes, checkpoints, reviews, and audits are the essential elements of governance. The level of accountability is high, and data governance maturity is aggressively pursued.
Data management collaboration lies between the two extremes. Data management is a workgroup activity, but isolated pockets of activity aren’t sufficient. You need to have communication and coordination among workgroups. Sometimes goals are achieved through communication, education, and the development of good habits; other times policy definition and enforcement are required. The level of accountability is commensurate with the level of risk; the state of data governance maturity is continuously evolving.
Closing Thoughts
Getting started with data governance can be intimidating. Enterprise data governance can be incredibly complex with so many variables, dimensions, and details that it appears to be an impossible job. To avoid this sense of “boiling the ocean,” start small and grow systematically. Know why you’re governing and start with a small number of meaningful goals. Know which data to govern and begin with a realistic scope, then apply the level of governance that is best suited to meeting these objectives within your existing organizational structures and cultural norms.
Dave Wells is a consultant, teacher, and practitioner in information management with strong focus on practices to get maximum value from your data: data quality, data integration, and business intelligence.
For more on data governance, attend TDWI Data Governance Fundamentals, a new course being taught for the first time at the upcoming TDWI World Conference in Orlando, November 7–12, 2010.
Highlight of key findings from TDWI's wide variety of research
Integrating Data into SAP BW
TDWI asked a series of questions of SAP BW users to understand the data content of BW and how often it’s refreshed:
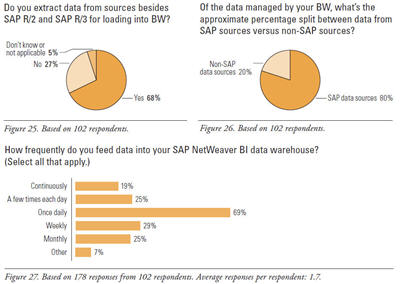
- Most BW users integrate some non-SAP data into BW. When asked, “Do you extract data from sources besides SAP for loading into BW?” two-thirds answered yes (68%) and a quarter said no (27%). (See Figure 25.)
- By far, most data in BW comes from SAP sources. TDWI asked, “Of the data managed by your BW, what’s the approximate percentage split between data from SAP sources versus non-SAP sources?” (See Figure 26.) By averaging the figures that respondents entered, we see that, in the average BW instance, a whopping 80% of the data comes from SAP sources, whereas only 20% comes from outside SAP.
- Once a day is the norm for integrating data into BW (69% of respondents in Figure 27). But some data feeds are continuous (19%) or recur multiple times daily (25%). At the other extreme, some feeds are weekly or monthly, probably for financial closings.
In summary, most BW instances are fed data once a day on average, and most are fed data from both SAP and non-SAP sources, yet the non-SAP data is only 20% of BW’s content on average.
(Click to enlarge)
Source: Business Intelligence Solutions for SAP (TDWI Best Practices Report, Q4 2007). Click here to access the report.

FlashPoint Rx prescribes a "Mistake to Avoid" for business intelligence and data warehousing professionals.
Mistake:
Inadequate Monitoring of Data Interfaces
By Arkady Maydanchik
It is not uncommon for a data warehouse to receive hundreds of batch feeds and uncountable real-time messages from multiple data sources every month. These ongoing data interfaces usually account for the greatest number of data quality problems. The problems tend to accumulate over time, and there is little opportunity to fix the ever-growing backlog as we strive toward faster data propagation and lower data latency.
Why do the well-tested data propagation interfaces falter? The source systems that originate the feeds are subject to frequent structural changes, updates, and upgrades. Testing the effect of these changes on the data feeds to multiple independent downstream databases is a difficult and often impractical step. Lack of regression testing and quality assurance inevitably leads to numerous data problems with the feeds anytime the source system is modified--which is all of the time!
The solution to interface monitoring is to design programs operating between the source and target databases. Such programs are entrusted with the task of analyzing the interface data before it’s loaded and processed. Individual data monitors use data quality rules to test data accuracy and integrity. Their objective is to identify all potential data errors. Advanced monitors that use complex business rules to compare data across batches and against target databases identify more problems. Aggregate monitors search for unexpected changes in batch interfaces. They compare various aggregate attribute characteristics (such as counts of attribute values) from batch to batch. A value outside of the reasonably expected range indicates a potential problem.
Source: Ten Mistakes to Avoid In Data Quality Management (Q4 2007). Click here to access the publication.

